Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Composite - a Compound Element that consists of two or more distinct weaknesses, in which all weaknesses must be present at the same time in order for a potential vulnerability to arise. Removing any of the weaknesses eliminates or sharply reduces the risk. One weakness, X, can be "broken down" into component weaknesses Y and Z. There can be cases in which one weakness might not be essential to a composite, but changes the nature of the composite when it becomes a vulnerability.
Chain - a Compound Element that is a sequence of two or more separate weaknesses that can be closely linked together within software. One weakness, X, can directly create the conditions that are necessary to cause another weakness, Y, to enter a vulnerable condition. When this happens, CWE refers to X as "primary" to Y, and Y is "resultant" from X. Chains can involve more than two weaknesses, and in some cases, they might have a tree-like structure.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
CWE-788: Access of Memory Location After End of Buffer
Weakness ID: 788
Vulnerability Mapping:DISCOURAGEDThis CWE ID should not be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
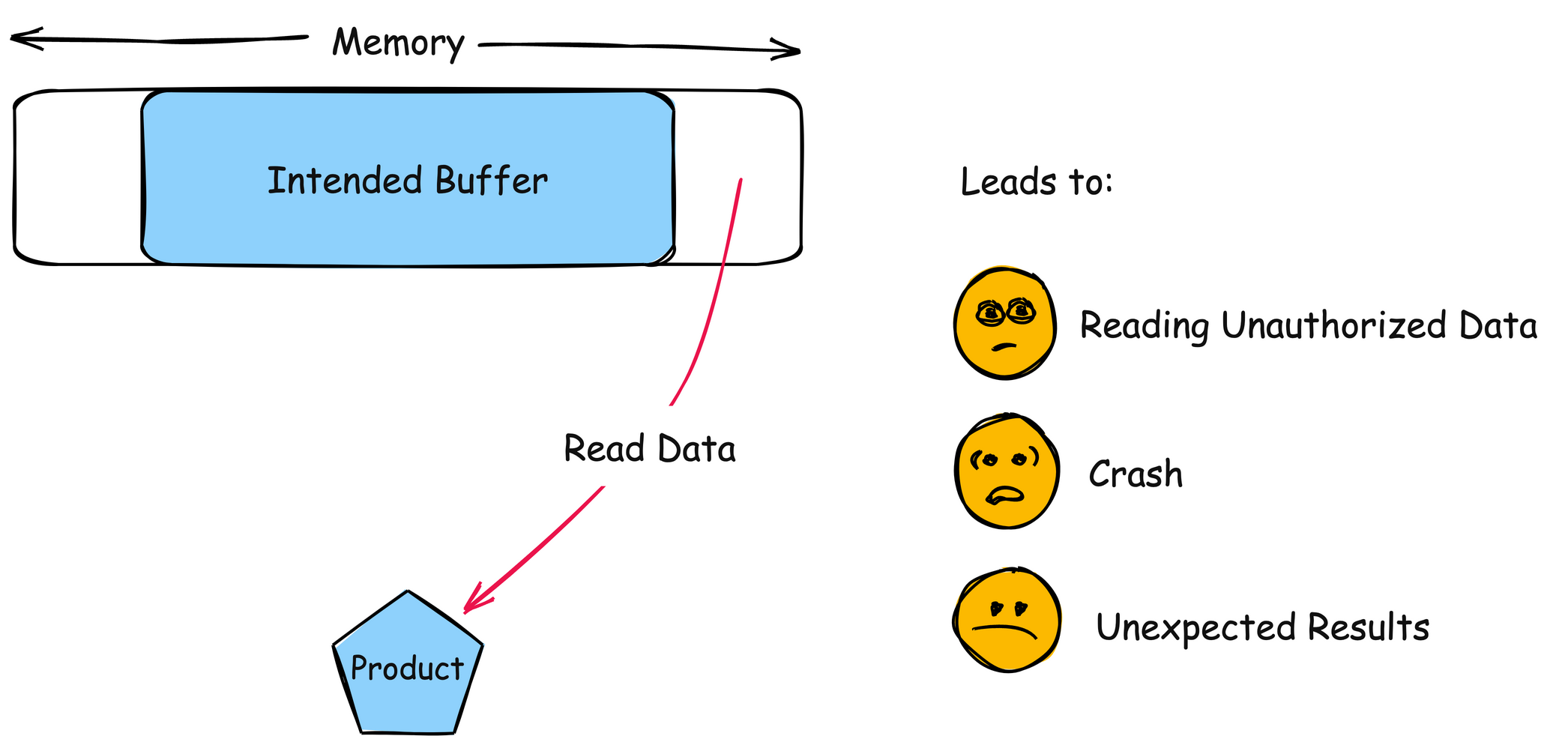
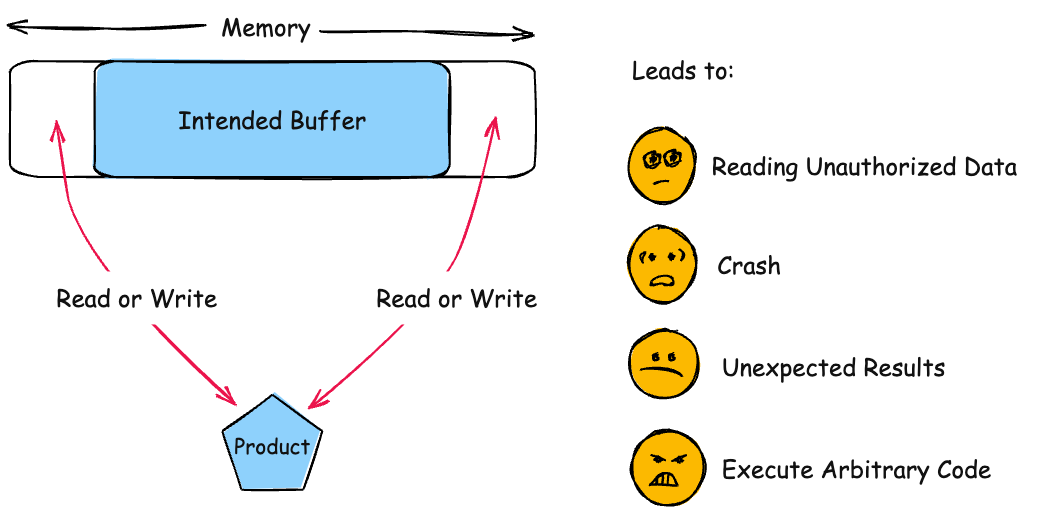
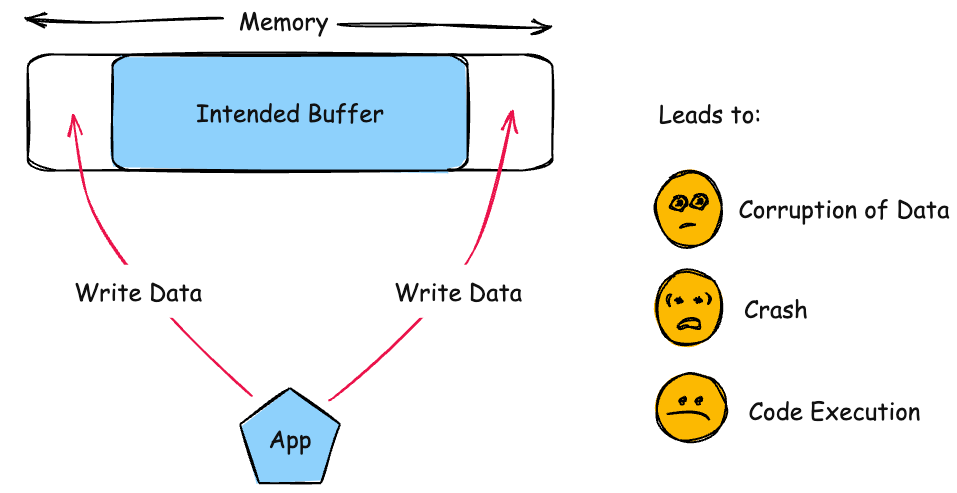
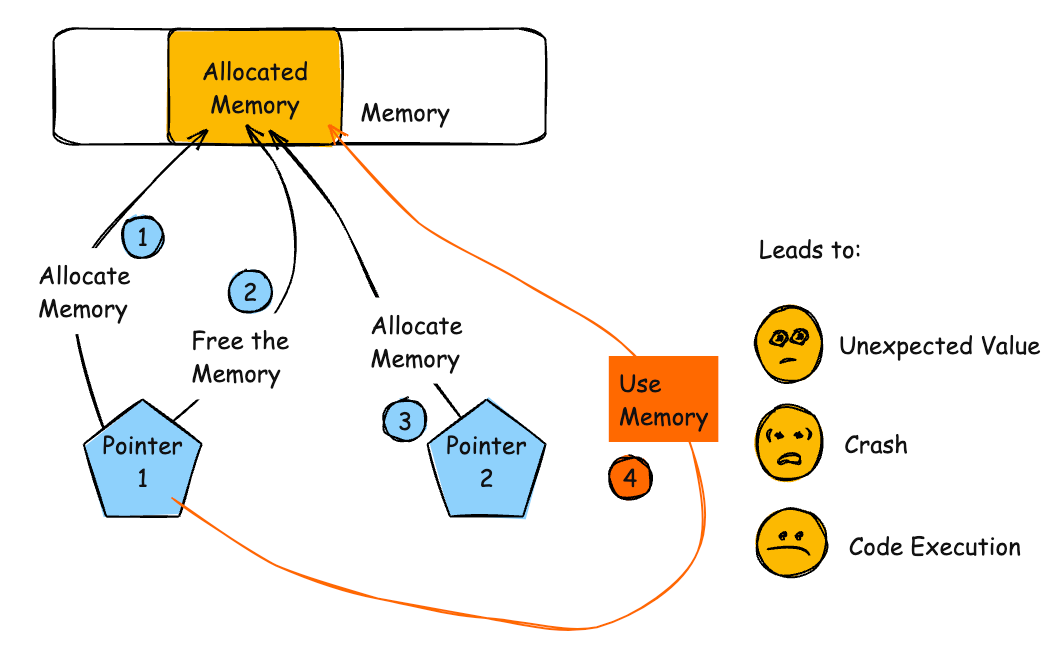
The product reads or writes to a buffer using an index or pointer that references a memory location after the end of the buffer.
Extended Description
This typically occurs when a pointer or its index is incremented to a position after the buffer; or when pointer arithmetic results in a position after the buffer.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory
Scope: Confidentiality
For an out-of-bounds read, the attacker may have access to sensitive information. If the sensitive information contains system details, such as the current buffer's position in memory, this knowledge can be used to craft further attacks, possibly with more severe consequences.
Modify Memory; DoS: Crash, Exit, or Restart
Scope: Integrity, Availability
Out of bounds memory access will very likely result in the corruption of relevant memory, and perhaps instructions, possibly leading to a crash. Other attacks leading to lack of availability are possible, including putting the program into an infinite loop.
Modify Memory; Execute Unauthorized Code or Commands
Scope: Integrity
If the memory accessible by the attacker can be effectively controlled, it may be possible to execute arbitrary code, as with a standard buffer overflow. If the attacker can overwrite a pointer's worth of memory (usually 32 or 64 bits), they can redirect a function pointer to their own malicious code. Even when the attacker can only modify a single byte arbitrary code execution can be possible. Sometimes this is because the same problem can be exploited repeatedly to the same effect. Other times it is because the attacker can overwrite security-critical application-specific data -- such as a flag indicating whether the user is an administrator.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Demonstrative Examples
Example 1
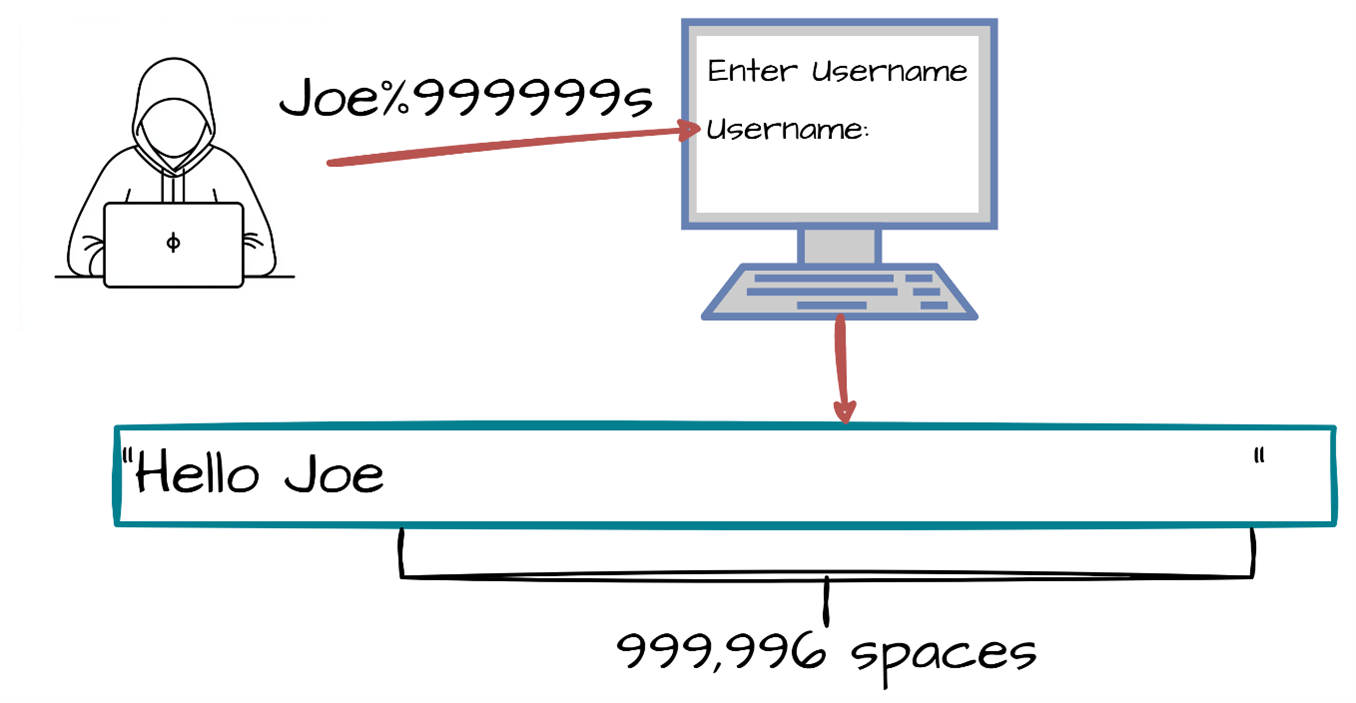
This example takes an IP address from a user, verifies that it is well formed and then looks up the hostname and copies it into a buffer.
This function allocates a buffer of 64 bytes to store the hostname, however there is no guarantee that the hostname will not be larger than 64 bytes. If an attacker specifies an address which resolves to a very large hostname, then the function may overwrite sensitive data or even relinquish control flow to the attacker.
Note that this example also contains an unchecked return value (CWE-252) that can lead to a NULL pointer dereference (CWE-476).
Example 2
In the following example, it is possible to request that memcpy move a much larger segment of memory than assumed:
(bad code)
Example Language: C
int returnChunkSize(void *) {
/* if chunk info is valid, return the size of usable memory,
If returnChunkSize() happens to encounter an error it will return -1. Notice that the return value is not checked before the memcpy operation (CWE-252), so -1 can be passed as the size argument to memcpy() (CWE-805). Because memcpy() assumes that the value is unsigned, it will be interpreted as MAXINT-1 (CWE-195), and therefore will copy far more memory than is likely available to the destination buffer (CWE-787, CWE-788).
Example 3
This example applies an encoding procedure to an input string and stores it into a buffer.
(bad code)
Example Language: C
char * copy_input(char *user_supplied_string){
int i, dst_index; char *dst_buf = (char*)malloc(4*sizeof(char) * MAX_SIZE); if ( MAX_SIZE <= strlen(user_supplied_string) ){
die("user string too long, die evil hacker!");
} dst_index = 0; for ( i = 0; i < strlen(user_supplied_string); i++ ){
The programmer attempts to encode the ampersand character in the user-controlled string, however the length of the string is validated before the encoding procedure is applied. Furthermore, the programmer assumes encoding expansion will only expand a given character by a factor of 4, while the encoding of the ampersand expands by 5. As a result, when the encoding procedure expands the string it is possible to overflow the destination buffer if the attacker provides a string of many ampersands.
Example 4
In the following C/C++ example the method processMessageFromSocket() will get a message from a socket, placed into a buffer, and will parse the contents of the buffer into a structure that contains the message length and the message body. A for loop is used to copy the message body into a local character string which will be passed to another method for processing.
//Ignoring possibliity that buffer > BUFFER_SIZE if (getMessage(socket, buffer, BUFFER_SIZE) > 0) {
// place contents of the buffer into message structure ExMessage *msg = recastBuffer(buffer);
// copy message body into string for processing int index; for (index = 0; index < msg->msgLength; index++) {
message[index] = msg->msgBody[index];
} message[index] = '\0';
// process message success = processMessage(message);
} return success;
}
However, the message length variable from the structure is used as the condition for ending the for loop without validating that the message length variable accurately reflects the length of the message body (CWE-606). This can result in a buffer over-read (CWE-125) by reading from memory beyond the bounds of the buffer if the message length variable indicates a length that is longer than the size of a message body (CWE-130).
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: integer signedness error (CWE-195) passes signed comparison, leading to heap overflow (CWE-122)
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID should not be used to map to real-world vulnerabilities)
Reasons
Potential Deprecation,
Frequent Misuse
Rationale
The CWE entry might be misused when lower-level CWE entries might be available. It also overlaps existing CWE entries and might be deprecated in the future.
Comments
If the "Access" operation is known to be a read or a write, then investigate children of entries such as CWE-787: Out-of-bounds Write and CWE-125: Out-of-bounds Read.
CWE-786: Access of Memory Location Before Start of Buffer
Weakness ID: 786
Vulnerability Mapping:DISCOURAGEDThis CWE ID should not be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product reads or writes to a buffer using an index or pointer that references a memory location prior to the beginning of the buffer.
Extended Description
This typically occurs when a pointer or its index is decremented to a position before the buffer, when pointer arithmetic results in a position before the beginning of the valid memory location, or when a negative index is used.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory
Scope: Confidentiality
For an out-of-bounds read, the attacker may have access to sensitive information. If the sensitive information contains system details, such as the current buffer's position in memory, this knowledge can be used to craft further attacks, possibly with more severe consequences.
Modify Memory; DoS: Crash, Exit, or Restart
Scope: Integrity, Availability
Out of bounds memory access will very likely result in the corruption of relevant memory, and perhaps instructions, possibly leading to a crash.
Modify Memory; Execute Unauthorized Code or Commands
Scope: Integrity
If the corrupted memory can be effectively controlled, it may be possible to execute arbitrary code. If the corrupted memory is data rather than instructions, the system will continue to function with improper changes, possibly in violation of an implicit or explicit policy.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Demonstrative Examples
Example 1
In the following C/C++ example, a utility function is used to trim trailing whitespace from a character string. The function copies the input string to a local character string and uses a while statement to remove the trailing whitespace by moving backward through the string and overwriting whitespace with a NUL character.
(bad code)
Example Language: C
char* trimTrailingWhitespace(char *strMessage, int length) {
However, this function can cause a buffer underwrite if the input character string contains all whitespace. On some systems the while statement will move backwards past the beginning of a character string and will call the isspace() function on an address outside of the bounds of the local buffer.
Example 2
The following example asks a user for an offset into an array to select an item.
(bad code)
Example Language: C
int main (int argc, char **argv) {
char *items[] = {"boat", "car", "truck", "train"}; int index = GetUntrustedOffset(); printf("You selected %s\n", items[index-1]);
}
The programmer allows the user to specify which element in the list to select, however an attacker can provide an out-of-bounds offset, resulting in a buffer over-read (CWE-126).
Example 3
The following is an example of code that may result in a buffer underwrite. This code is attempting to replace the substring "Replace Me" in destBuf with the string stored in srcBuf. It does so by using the function strstr(), which returns a pointer to the found substring in destBuf. Using pointer arithmetic, the starting index of the substring is found.
(bad code)
Example Language: C
int main() {
...
char *result = strstr(destBuf, "Replace Me");
int idx = result - destBuf;
strcpy(&destBuf[idx], srcBuf);
...
}
In the case where the substring is not found in destBuf, strstr() will return NULL, causing the pointer arithmetic to be undefined, potentially setting the value of idx to a negative number. If idx is negative, this will result in a buffer underwrite of destBuf.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Buffer underflow from an all-whitespace string, which causes a counter to be decremented before the buffer while looking for a non-whitespace character.
Buffer underflow due to mishandled special characters
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID should not be used to map to real-world vulnerabilities)
Reasons
Potential Deprecation,
Frequent Misuse
Rationale
The CWE entry might be misused when lower-level CWE entries might be available. It also overlaps existing CWE entries and might be deprecated in the future.
Comments
If the "Access" operation is known to be a read or a write, then investigate children of entries such as CWE-787: Out-of-bounds Write and CWE-125: Out-of-bounds Read.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CERT C Secure Coding
ARR30-C
CWE More Specific
Do not form or use out-of-bounds pointers or array subscripts
CWE-843: Access of Resource Using Incompatible Type ('Type Confusion')
Weakness ID: 843
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product allocates or initializes a resource such as a pointer, object, or variable using one type, but it later accesses that resource using a type that is incompatible with the original type.
Extended Description
When the product accesses the resource using an incompatible type, this could trigger logical errors because the resource does not have expected properties. In languages without memory safety, such as C and C++, type confusion can lead to out-of-bounds memory access.
While this weakness is frequently associated with unions when parsing data with many different embedded object types in C, it can be present in any application that can interpret the same variable or memory location in multiple ways.
This weakness is not unique to C and C++. For example, errors in PHP applications can be triggered by providing array parameters when scalars are expected, or vice versa. Languages such as Perl, which perform automatic conversion of a variable of one type when it is accessed as if it were another type, can also contain these issues.
Alternate Terms
Object Type Confusion
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory; Modify Memory; Execute Unauthorized Code or Commands; DoS: Crash, Exit, or Restart
Scope: Availability, Integrity, Confidentiality
When a memory buffer is accessed using the wrong type, it could read or write memory out of the bounds of the buffer, if the allocated buffer is smaller than the type that the code is attempting to access, leading to a crash and possibly code execution.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The following code uses a union to support the representation of different types of messages. It formats messages differently, depending on their type.
buf.msgType = NAME_TYPE; buf.name = defaultMessage; printf("Pointer of buf.name is %p\n", buf.name); /* This particular value for nameID is used to make the code architecture-independent. If coming from untrusted input, it could be any value. */
buf.nameID = (int)(defaultMessage + 1); printf("Pointer of buf.name is now %p\n", buf.name); if (buf.msgType == NAME_TYPE) {
printf("Message: %s\n", buf.name);
} else {
printf("Message: Use ID %d\n", buf.nameID);
}
}
The code intends to process the message as a NAME_TYPE, and sets the default message to "Hello World." However, since both buf.name and buf.nameID are part of the same union, they can act as aliases for the same memory location, depending on memory layout after compilation.
As a result, modification of buf.nameID - an int - can effectively modify the pointer that is stored in buf.name - a string.
Execution of the program might generate output such as:
Pointer of name is 10830
Pointer of name is now 10831
Message: ello World
Notice how the pointer for buf.name was changed, even though buf.name was not explicitly modified.
In this case, the first "H" character of the message is omitted. However, if an attacker is able to fully control the value of buf.nameID, then buf.name could contain an arbitrary pointer, leading to out-of-bounds reads or writes.
Example 2
The following PHP code accepts a value, adds 5, and prints the sum.
(bad code)
Example Language: PHP
$value = $_GET['value']; $sum = $value + 5; echo "value parameter is '$value'<p>"; echo "SUM is $sum";
When called with the following query string:
value=123
the program calculates the sum and prints out:
SUM is 128
However, the attacker could supply a query string such as:
value[]=123
The "[]" array syntax causes $value to be treated as an array type, which then generates a fatal error when calculating $sum:
Fatal error: Unsupported operand types in program.php on line 2
Example 3
The following Perl code is intended to look up the privileges for user ID's between 0 and 3, by performing an access of the $UserPrivilegeArray reference. It is expected that only userID 3 is an admin (since this is listed in the third element of the array).
(bad code)
Example Language: Perl
my $UserPrivilegeArray = ["user", "user", "admin", "user"];
In this case, the programmer intended to use "$UserPrivilegeArray->{$userID}" to access the proper position in the array. But because the subscript was omitted, the "user" string was compared to the scalar representation of the $UserPrivilegeArray reference, which might be of the form "ARRAY(0x229e8)" or similar.
Since the logic also "fails open" (CWE-636), the result of this bug is that all users are assigned administrator privileges.
While this is a forced example, it demonstrates how type confusion can have security consequences, even in memory-safe languages.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Improperly-parsed file containing records of different types leads to code execution when a memory location is interpreted as a different object than intended.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Applicable Platform
This weakness is possible in any type-unsafe programming language.
Research Gap
Type confusion weaknesses have received some attention by applied researchers and major software vendors for C and C++ code. Some publicly-reported vulnerabilities probably have type confusion as a root-cause weakness, but these may be described as "memory corruption" instead.
For other languages, there are very few public reports of type confusion weaknesses. These are probably under-studied. Since many programs rely directly or indirectly on loose typing, a potential "type confusion" behavior might be intentional, possibly requiring more manual analysis.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CERT C Secure Coding
EXP39-C
Exact
Do not access a variable through a pointer of an incompatible type
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 7, "Type Confusion", Page 319. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product accesses or uses a pointer that has not been initialized.
Extended Description
If the pointer contains an uninitialized value, then the value might not point to a valid memory location. This could cause the product to read from or write to unexpected memory locations, leading to a denial of service. If the uninitialized pointer is used as a function call, then arbitrary functions could be invoked. If an attacker can influence the portion of uninitialized memory that is contained in the pointer, this weakness could be leveraged to execute code or perform other attacks.
Depending on memory layout, associated memory management behaviors, and product operation, the attacker might be able to influence the contents of the uninitialized pointer, thus gaining more fine-grained control of the memory location to be accessed.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory
Scope: Confidentiality
If the uninitialized pointer is used in a read operation, an attacker might be able to read sensitive portions of memory.
DoS: Crash, Exit, or Restart
Scope: Availability
If the uninitialized pointer references a memory location that is not accessible to the product, or points to a location that is "malformed" (such as NULL) or larger than expected by a read or write operation, then a crash may occur.
Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
If the uninitialized pointer is used in a function call, or points to unexpected data in a write operation, then code execution may be possible.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
CanPrecede
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: secure communications library does not initialize a local variable for a data structure (CWE-456), leading to access of an uninitialized pointer (CWE-824).
Step-based manipulation: invocation of debugging function before the primary initialization function leads to access of an uninitialized pointer and code execution.
LDAP server does not initialize members of structs, which leads to free of uninitialized pointer if an LDAP request fails.
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Terminology
Many weaknesses related to pointer dereferences fall under the general term of "memory corruption" or "memory safety." As of September 2010, there is no commonly-used terminology that covers the lower-level variants.
Maintenance
There are close relationships between incorrect pointer dereferences and other weaknesses related to buffer operations. There may not be sufficient community agreement regarding these relationships. Further study is needed to determine when these relationships are chains, composites, perspective/layering, or other types of relationships. As of September 2010, most of the relationships are being captured as chains.
References
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 7, "Variable Initialization", Page 312. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The accidental addition of a data-structure sentinel can cause serious programming logic problems.
Extended Description
Data-structure sentinels are often used to mark the structure of data. A common example of this is the null character at the end of strings or a special sentinel to mark the end of a linked list. It is dangerous to allow this type of control data to be easily accessible. Therefore, it is important to protect from the addition or modification of sentinels.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Application Data
Scope: Integrity
Generally this error will cause the data structure to not work properly by truncating the data.
Potential Mitigations
Phase(s)
Mitigation
Implementation; Architecture and Design
Encapsulate the user from interacting with data sentinels. Validate user input to verify that sentinels are not present.
Implementation
Proper error checking can reduce the risk of inadvertently introducing sentinel values into data. For example, if a parsing function fails or encounters an error, it might return a value that is the same as the sentinel.
Architecture and Design
Use an abstraction library to abstract away risky APIs. This is not a complete solution.
Operation
Use OS-level preventative functionality. This is not a complete solution.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
The following example assigns some character values to a list of characters and prints them each individually, and then as a string. The third character value is intended to be an integer taken from user input and converted to an int.
The first print statement will print each character separated by a space. However, if a NULL byte is read from stdin by fgetc, then it will return 0. When foo is printed as a string, the 0 at character foo[2] will act as a NULL terminator and foo[3] will never be printed.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Addition of data-structure sentinel
CERT C Secure Coding
STR03-C
Do not inadvertently truncate a null-terminated byte string
CERT C Secure Coding
STR06-C
Do not assume that strtok() leaves the parse string unchanged
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The code uses an operator for assignment when the intention was to perform a comparison.
Extended Description
In many languages the compare statement is very close in appearance to the assignment statement and are often confused. This bug is generally the result of a typo and usually causes obvious problems with program execution. If the comparison is in an if statement, the if statement will usually evaluate the value of the right-hand side of the predicate.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Alter Execution Logic
Scope: Other
Potential Mitigations
Phase(s)
Mitigation
Testing
Many IDEs and static analysis products will detect this problem.
Implementation
Place constants on the left. If one attempts to assign a constant with a variable, the compiler will produce an error.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Likelihood Of Exploit
Low
Demonstrative Examples
Example 1
The following C/C++ and C# examples attempt to validate an int input parameter against the integer value 100.
(bad code)
Example Language: C
int isValid(int value) {
if (value=100) {
printf("Value is valid\n"); return(1);
} printf("Value is not valid\n"); return(0);
}
(bad code)
Example Language: C#
bool isValid(int value) {
if (value=100) {
Console.WriteLine("Value is valid."); return true;
} Console.WriteLine("Value is not valid."); return false;
}
However, the expression to be evaluated in the if statement uses the assignment operator "=" rather than the comparison operator "==". The result of using the assignment operator instead of the comparison operator causes the int variable to be reassigned locally and the expression in the if statement will always evaluate to the value on the right hand side of the expression. This will result in the input value not being properly validated, which can cause unexpected results.
Example 2
In this example, we show how assigning instead of comparing can impact code when values are being passed by reference instead of by value. Consider a scenario in which a string is being processed from user input. Assume the string has already been formatted such that different user inputs are concatenated with the colon character. When the processString function is called, the test for the colon character will result in an insertion of the colon character instead, adding new input separators. Since the string was passed by reference, the data sentinels will be inserted in the original string (CWE-464), and further processing of the inputs will be altered, possibly malformed..
(bad code)
Example Language: C
void processString (char *str) {
int i;
for(i=0; i<strlen(str); i++) {
if (isalnum(str[i])){
processChar(str[i]);
} else if (str[i] = ':') {
movingToNewInput();}
}
}
}
Example 3
The following Java example attempts to perform some processing based on the boolean value of the input parameter. However, the expression to be evaluated in the if statement uses the assignment operator "=" rather than the comparison operator "==". As with the previous examples, the variable will be reassigned locally and the expression in the if statement will evaluate to true and unintended processing may occur.
System.out.println("Not Valid, do not perform processing"); return;
}
}
While most Java compilers will catch the use of an assignment operator when a comparison operator is required, for boolean variables in Java the use of the assignment operator within an expression is allowed. If possible, try to avoid using comparison operators on boolean variables in java. Instead, let the values of the variables stand for themselves, as in the following code.
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
Comprehensive Categorization: Insufficient Control Flow Management
Vulnerability Mapping Notes
Usage
ALLOWED
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Assigning instead of comparing
Software Fault Patterns
SFP1
Glitch in computation
CERT C Secure Coding
EXP45-C
CWE More Abstract
Do not perform assignments in selection statements
CWE-587: Assignment of a Fixed Address to a Pointer
Weakness ID: 587
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product sets a pointer to a specific address other than NULL or 0.
Extended Description
Using a fixed address is not portable, because that address will probably not be valid in all environments or platforms.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
If one executes code at a known location, an attacker might be able to inject code there beforehand.
DoS: Crash, Exit, or Restart; Reduce Maintainability; Reduce Reliability
Scope: Availability
If the code is ported to another platform or environment, the pointer is likely to be invalid and cause a crash.
Read Memory; Modify Memory
Scope: Confidentiality, Integrity
The data at a known pointer location can be easily read or influenced by an attacker.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Never set a pointer to a fixed address.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Use of Invariant Value in Dynamically Changing Context
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Class: Assembly
(Undetermined Prevalence)
Demonstrative Examples
Example 1
This code assumes a particular function will always be found at a particular address. It assigns a pointer to that address and calls the function.
(bad code)
Example Language: C
int (*pt2Function) (float, char, char)=0x08040000; int result2 = (*pt2Function) (12, 'a', 'b'); // Here we can inject code to execute.
The same function may not always be found at the same memory address. This could lead to a crash, or an attacker may alter the memory at the expected address, leading to arbitrary code execution.
Weakness Ordinalities
Ordinality
Description
Indirect
(where the weakness is a quality issue that might indirectly make it easier to introduce security-relevant weaknesses or make them more difficult to detect)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 04 - Integers (INT)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CERT C Secure Coding
INT36-C
Imprecise
Converting a pointer to integer or integer to pointer
CWE-806: Buffer Access Using Size of Source Buffer
Weakness ID: 806
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses the size of a source buffer when reading from or writing to a destination buffer, which may cause it to access memory that is outside of the bounds of the buffer.
Extended Description
When the size of the destination is smaller than the size of the source, a buffer overflow could occur.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Buffer overflows generally lead to crashes. Other attacks leading to lack of availability are possible, including putting the program into an infinite loop.
Read Memory; Modify Memory; Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
Buffer overflows often can be used to execute arbitrary code, which is usually outside the scope of a program's implicit security policy.
Bypass Protection Mechanism
Scope: Access Control
When the consequence is arbitrary code execution, this can often be used to subvert any other security service.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Use an abstraction library to abstract away risky APIs. Examples include the Safe C String Library (SafeStr) by Viega, and the Strsafe.h library from Microsoft. This is not a complete solution, since many buffer overflows are not related to strings.
Operation; Build and Compilation
Strategy: Environment Hardening
Use automatic buffer overflow detection mechanisms that are offered by certain compilers or compiler extensions. Examples include: the Microsoft Visual Studio /GS flag, Fedora/Red Hat FORTIFY_SOURCE GCC flag, StackGuard, and ProPolice, which provide various mechanisms including canary-based detection and range/index checking.
D3-SFCV (Stack Frame Canary Validation) from D3FEND [REF-1334] discusses canary-based detection in detail.
Effectiveness: Defense in Depth
Note:
This is not necessarily a complete solution, since these mechanisms only detect certain types of overflows. In addition, the result is still a denial of service, since the typical response is to exit the application.
Implementation
Programmers should adhere to the following rules when allocating and managing their applications memory: Double check that your buffer is as large as you specify. When using functions that accept a number of bytes to copy, such as strncpy(), be aware that if the destination buffer size is equal to the source buffer size, it may not NULL-terminate the string. Check buffer boundaries if calling this function in a loop and make sure there is no danger of writing past the allocated space. Truncate all input strings to a reasonable length before passing them to the copy and concatenation functions.
Operation; Build and Compilation
Strategy: Environment Hardening
Run or compile the software using features or extensions that randomly arrange the positions of a program's executable and libraries in memory. Because this makes the addresses unpredictable, it can prevent an attacker from reliably jumping to exploitable code.
Examples include Address Space Layout Randomization (ASLR) [REF-58] [REF-60] and Position-Independent Executables (PIE) [REF-64]. Imported modules may be similarly realigned if their default memory addresses conflict with other modules, in a process known as "rebasing" (for Windows) and "prelinking" (for Linux) [REF-1332] using randomly generated addresses. ASLR for libraries cannot be used in conjunction with prelink since it would require relocating the libraries at run-time, defeating the whole purpose of prelinking.
For more information on these techniques see D3-SAOR (Segment Address Offset Randomization) from D3FEND [REF-1335].
Effectiveness: Defense in Depth
Note: These techniques do not provide a complete solution. For instance, exploits frequently use a bug that discloses memory addresses in order to maximize reliability of code execution [REF-1337]. It has also been shown that a side-channel attack can bypass ASLR [REF-1333].
Operation
Strategy: Environment Hardening
Use a CPU and operating system that offers Data Execution Protection (using hardware NX or XD bits) or the equivalent techniques that simulate this feature in software, such as PaX [REF-60] [REF-61]. These techniques ensure that any instruction executed is exclusively at a memory address that is part of the code segment.
For more information on these techniques see D3-PSEP (Process Segment Execution Prevention) from D3FEND [REF-1336].
Effectiveness: Defense in Depth
Note: This is not a complete solution, since buffer overflows could be used to overwrite nearby variables to modify the software's state in dangerous ways. In addition, it cannot be used in cases in which self-modifying code is required. Finally, an attack could still cause a denial of service, since the typical response is to exit the application.
Build and Compilation; Operation
Most mitigating technologies at the compiler or OS level to date address only a subset of buffer overflow problems and rarely provide complete protection against even that subset. It is good practice to implement strategies to increase the workload of an attacker, such as leaving the attacker to guess an unknown value that changes every program execution.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Sometimes Prevalent)
C++
(Sometimes Prevalent)
Demonstrative Examples
Example 1
In the following example, the source character string is copied to the dest character string using the method strncpy.
(bad code)
Example Language: C
... char source[21] = "the character string"; char dest[12]; strncpy(dest, source, sizeof(source)-1); ...
However, in the call to strncpy the source character string is used within the sizeof call to determine the number of characters to copy. This will create a buffer overflow as the size of the source character string is greater than the dest character string. The dest character string should be used within the sizeof call to ensure that the correct number of characters are copied, as shown below.
(good code)
Example Language: C
... char source[21] = "the character string"; char dest[12]; strncpy(dest, source, sizeof(dest)-1); ...
Example 2
In this example, the method outputFilenameToLog outputs a filename to a log file. The method arguments include a pointer to a character string containing the file name and an integer for the number of characters in the string. The filename is copied to a buffer where the buffer size is set to a maximum size for inputs to the log file. The method then calls another method to save the contents of the buffer to the log file.
(bad code)
Example Language: C
#define LOG_INPUT_SIZE 40
// saves the file name to a log file int outputFilenameToLog(char *filename, int length) {
int success;
// buffer with size set to maximum size for input to log file char buf[LOG_INPUT_SIZE];
// copy filename to buffer strncpy(buf, filename, length);
// save to log file success = saveToLogFile(buf);
return success;
}
However, in this case the string copy method, strncpy, mistakenly uses the length method argument to determine the number of characters to copy rather than using the size of the local character string, buf. This can lead to a buffer overflow if the number of characters contained in character string pointed to by filename is larger then the number of characters allowed for the local character string. The string copy method should use the buf character string within a sizeof call to ensure that only characters up to the size of the buf array are copied to avoid a buffer overflow, as shown below.
(good code)
Example Language: C
... // copy filename to buffer strncpy(buf, filename, sizeof(buf)-1); ...
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
Primary
(where the weakness exists independent of other weaknesses)
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
CWE-805: Buffer Access with Incorrect Length Value
Weakness ID: 805
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses a sequential operation to read or write a buffer, but it uses an incorrect length value that causes it to access memory that is outside of the bounds of the buffer.
Extended Description
When the length value exceeds the size of the destination, a buffer overflow could occur.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory; Modify Memory; Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
Buffer overflows often can be used to execute arbitrary code, which is usually outside the scope of a program's implicit security policy. This can often be used to subvert any other security service.
Buffer overflows generally lead to crashes. Other attacks leading to lack of availability are possible, including putting the program into an infinite loop.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Strategy: Language Selection
Use a language that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
For example, many languages that perform their own memory management, such as Java and Perl, are not subject to buffer overflows. Other languages, such as Ada and C#, typically provide overflow protection, but the protection can be disabled by the programmer.
Be wary that a language's interface to native code may still be subject to overflows, even if the language itself is theoretically safe.
Architecture and Design
Strategy: Libraries or Frameworks
Use a vetted library or framework that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
Examples include the Safe C String Library (SafeStr) by Messier and Viega [REF-57], and the Strsafe.h library from Microsoft [REF-56]. These libraries provide safer versions of overflow-prone string-handling functions.
Note: This is not a complete solution, since many buffer overflows are not related to strings.
Operation; Build and Compilation
Strategy: Environment Hardening
Use automatic buffer overflow detection mechanisms that are offered by certain compilers or compiler extensions. Examples include: the Microsoft Visual Studio /GS flag, Fedora/Red Hat FORTIFY_SOURCE GCC flag, StackGuard, and ProPolice, which provide various mechanisms including canary-based detection and range/index checking.
D3-SFCV (Stack Frame Canary Validation) from D3FEND [REF-1334] discusses canary-based detection in detail.
Effectiveness: Defense in Depth
Note:
This is not necessarily a complete solution, since these mechanisms only detect certain types of overflows. In addition, the result is still a denial of service, since the typical response is to exit the application.
Implementation
Consider adhering to the following rules when allocating and managing an application's memory:
Double check that the buffer is as large as specified.
When using functions that accept a number of bytes to copy, such as strncpy(), be aware that if the destination buffer size is equal to the source buffer size, it may not NULL-terminate the string.
Check buffer boundaries if accessing the buffer in a loop and make sure there is no danger of writing past the allocated space.
If necessary, truncate all input strings to a reasonable length before passing them to the copy and concatenation functions.
Architecture and Design
For any security checks that are performed on the client side, ensure that these checks are duplicated on the server side, in order to avoid CWE-602. Attackers can bypass the client-side checks by modifying values after the checks have been performed, or by changing the client to remove the client-side checks entirely. Then, these modified values would be submitted to the server.
Operation; Build and Compilation
Strategy: Environment Hardening
Run or compile the software using features or extensions that randomly arrange the positions of a program's executable and libraries in memory. Because this makes the addresses unpredictable, it can prevent an attacker from reliably jumping to exploitable code.
Examples include Address Space Layout Randomization (ASLR) [REF-58] [REF-60] and Position-Independent Executables (PIE) [REF-64]. Imported modules may be similarly realigned if their default memory addresses conflict with other modules, in a process known as "rebasing" (for Windows) and "prelinking" (for Linux) [REF-1332] using randomly generated addresses. ASLR for libraries cannot be used in conjunction with prelink since it would require relocating the libraries at run-time, defeating the whole purpose of prelinking.
For more information on these techniques see D3-SAOR (Segment Address Offset Randomization) from D3FEND [REF-1335].
Effectiveness: Defense in Depth
Note: These techniques do not provide a complete solution. For instance, exploits frequently use a bug that discloses memory addresses in order to maximize reliability of code execution [REF-1337]. It has also been shown that a side-channel attack can bypass ASLR [REF-1333].
Operation
Strategy: Environment Hardening
Use a CPU and operating system that offers Data Execution Protection (using hardware NX or XD bits) or the equivalent techniques that simulate this feature in software, such as PaX [REF-60] [REF-61]. These techniques ensure that any instruction executed is exclusively at a memory address that is part of the code segment.
For more information on these techniques see D3-PSEP (Process Segment Execution Prevention) from D3FEND [REF-1336].
Effectiveness: Defense in Depth
Note: This is not a complete solution, since buffer overflows could be used to overwrite nearby variables to modify the software's state in dangerous ways. In addition, it cannot be used in cases in which self-modifying code is required. Finally, an attack could still cause a denial of service, since the typical response is to exit the application.
Architecture and Design; Operation
Strategy: Environment Hardening
Run your code using the lowest privileges that are required to accomplish the necessary tasks [REF-76]. If possible, create isolated accounts with limited privileges that are only used for a single task. That way, a successful attack will not immediately give the attacker access to the rest of the product or its environment. For example, database applications rarely need to run as the database administrator, especially in day-to-day operations.
Architecture and Design; Operation
Strategy: Sandbox or Jail
Run the code in a "jail" or similar sandbox environment that enforces strict boundaries between the process and the operating system. This may effectively restrict which files can be accessed in a particular directory or which commands can be executed by the software.
OS-level examples include the Unix chroot jail, AppArmor, and SELinux. In general, managed code may provide some protection. For example, java.io.FilePermission in the Java SecurityManager allows the software to specify restrictions on file operations.
This may not be a feasible solution, and it only limits the impact to the operating system; the rest of the application may still be subject to compromise.
Be careful to avoid CWE-243 and other weaknesses related to jails.
Effectiveness: Limited
Note: The effectiveness of this mitigation depends on the prevention capabilities of the specific sandbox or jail being used and might only help to reduce the scope of an attack, such as restricting the attacker to certain system calls or limiting the portion of the file system that can be accessed.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Class: Assembly
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
This example takes an IP address from a user, verifies that it is well formed and then looks up the hostname and copies it into a buffer.
This function allocates a buffer of 64 bytes to store the hostname under the assumption that the maximum length value of hostname is 64 bytes, however there is no guarantee that the hostname will not be larger than 64 bytes. If an attacker specifies an address which resolves to a very large hostname, then the function may overwrite sensitive data or even relinquish control flow to the attacker.
Note that this example also contains an unchecked return value (CWE-252) that can lead to a NULL pointer dereference (CWE-476).
Example 2
In the following example, it is possible to request that memcpy move a much larger segment of memory than assumed:
(bad code)
Example Language: C
int returnChunkSize(void *) {
/* if chunk info is valid, return the size of usable memory,
If returnChunkSize() happens to encounter an error it will return -1. Notice that the return value is not checked before the memcpy operation (CWE-252), so -1 can be passed as the size argument to memcpy() (CWE-805). Because memcpy() assumes that the value is unsigned, it will be interpreted as MAXINT-1 (CWE-195), and therefore will copy far more memory than is likely available to the destination buffer (CWE-787, CWE-788).
Example 3
In the following example, the source character string is copied to the dest character string using the method strncpy.
(bad code)
Example Language: C
... char source[21] = "the character string"; char dest[12]; strncpy(dest, source, sizeof(source)-1); ...
However, in the call to strncpy the source character string is used within the sizeof call to determine the number of characters to copy. This will create a buffer overflow as the size of the source character string is greater than the dest character string. The dest character string should be used within the sizeof call to ensure that the correct number of characters are copied, as shown below.
(good code)
Example Language: C
... char source[21] = "the character string"; char dest[12]; strncpy(dest, source, sizeof(dest)-1); ...
Example 4
In this example, the method outputFilenameToLog outputs a filename to a log file. The method arguments include a pointer to a character string containing the file name and an integer for the number of characters in the string. The filename is copied to a buffer where the buffer size is set to a maximum size for inputs to the log file. The method then calls another method to save the contents of the buffer to the log file.
(bad code)
Example Language: C
#define LOG_INPUT_SIZE 40
// saves the file name to a log file int outputFilenameToLog(char *filename, int length) {
int success;
// buffer with size set to maximum size for input to log file char buf[LOG_INPUT_SIZE];
// copy filename to buffer strncpy(buf, filename, length);
// save to log file success = saveToLogFile(buf);
return success;
}
However, in this case the string copy method, strncpy, mistakenly uses the length method argument to determine the number of characters to copy rather than using the size of the local character string, buf. This can lead to a buffer overflow if the number of characters contained in character string pointed to by filename is larger then the number of characters allowed for the local character string. The string copy method should use the buf character string within a sizeof call to ensure that only characters up to the size of the buf array are copied to avoid a buffer overflow, as shown below.
(good code)
Example Language: C
... // copy filename to buffer strncpy(buf, filename, sizeof(buf)-1); ...
Example 5
Windows provides the MultiByteToWideChar(), WideCharToMultiByte(), UnicodeToBytes(), and BytesToUnicode() functions to convert between arbitrary multibyte (usually ANSI) character strings and Unicode (wide character) strings. The size arguments to these functions are specified in different units, (one in bytes, the other in characters) making their use prone to error.
In a multibyte character string, each character occupies a varying number of bytes, and therefore the size of such strings is most easily specified as a total number of bytes. In Unicode, however, characters are always a fixed size, and string lengths are typically given by the number of characters they contain. Mistakenly specifying the wrong units in a size argument can lead to a buffer overflow.
The following function takes a username specified as a multibyte string and a pointer to a structure for user information and populates the structure with information about the specified user. Since Windows authentication uses Unicode for usernames, the username argument is first converted from a multibyte string to a Unicode string.
This function incorrectly passes the size of unicodeUser in bytes instead of characters. The call to MultiByteToWideChar() can therefore write up to (UNLEN+1)*sizeof(WCHAR) wide characters, or (UNLEN+1)*sizeof(WCHAR)*sizeof(WCHAR) bytes, to the unicodeUser array, which has only (UNLEN+1)*sizeof(WCHAR) bytes allocated.
If the username string contains more than UNLEN characters, the call to MultiByteToWideChar() will overflow the buffer unicodeUser.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Language interpreter API function doesn't validate length argument, leading to information exposure
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Automated Static Analysis
This weakness can often be detected using automated static analysis tools. Many modern tools use data flow analysis or constraint-based techniques to minimize the number of false positives.
Automated static analysis generally does not account for environmental considerations when reporting out-of-bounds memory operations. This can make it difficult for users to determine which warnings should be investigated first. For example, an analysis tool might report buffer overflows that originate from command line arguments in a program that is not expected to run with setuid or other special privileges.
Effectiveness: High
Note:Detection techniques for buffer-related errors are more mature than for most other weakness types.
Automated Dynamic Analysis
This weakness can be detected using dynamic tools and techniques that interact with the product using large test suites with many diverse inputs, such as fuzz testing (fuzzing), robustness testing, and fault injection. The product's operation may slow down, but it should not become unstable, crash, or generate incorrect results.
Effectiveness: Moderate
Note:Without visibility into the code, black box methods may not be able to sufficiently distinguish this weakness from others, requiring manual methods to diagnose the underlying problem.
Manual Analysis
Manual analysis can be useful for finding this weakness, but it might not achieve desired code coverage within limited time constraints. This becomes difficult for weaknesses that must be considered for all inputs, since the attack surface can be too large.
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 06 - Arrays and the STL (ARR)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CERT C Secure Coding
ARR38-C
Imprecise
Guarantee that library functions do not form invalid pointers
CWE-120: Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
Weakness ID: 120
Vulnerability Mapping:ALLOWEDThis CWE ID could be used to map to real-world vulnerabilities in limited situations requiring careful review
(with careful review of mapping notes)
Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product copies an input buffer to an output buffer without verifying that the size of the input buffer is less than the size of the output buffer, leading to a buffer overflow.
Extended Description
A buffer overflow condition exists when a product attempts to put more data in a buffer than it can hold, or when it attempts to put data in a memory area outside of the boundaries of a buffer. The simplest type of error, and the most common cause of buffer overflows, is the "classic" case in which the product copies the buffer without restricting how much is copied. Other variants exist, but the existence of a classic overflow strongly suggests that the programmer is not considering even the most basic of security protections.
Alternate Terms
Classic Buffer Overflow
This term was frequently used by vulnerability researchers during approximately 1995 to 2005 to differentiate buffer copies without length checks (which had been known about for decades) from other emerging weaknesses that still involved invalid accesses of buffers, as vulnerability researchers began to develop advanced exploitation techniques.
Unbounded Transfer
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
Buffer overflows often can be used to execute arbitrary code, which is usually outside the scope of the product's implicit security policy. This can often be used to subvert any other security service.
Buffer overflows generally lead to crashes. Other attacks leading to lack of availability are possible, including putting the product into an infinite loop.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Strategy: Language Selection
Use a language that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
For example, many languages that perform their own memory management, such as Java and Perl, are not subject to buffer overflows. Other languages, such as Ada and C#, typically provide overflow protection, but the protection can be disabled by the programmer.
Be wary that a language's interface to native code may still be subject to overflows, even if the language itself is theoretically safe.
Architecture and Design
Strategy: Libraries or Frameworks
Use a vetted library or framework that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
Examples include the Safe C String Library (SafeStr) by Messier and Viega [REF-57], and the Strsafe.h library from Microsoft [REF-56]. These libraries provide safer versions of overflow-prone string-handling functions.
Note: This is not a complete solution, since many buffer overflows are not related to strings.
Operation; Build and Compilation
Strategy: Environment Hardening
Use automatic buffer overflow detection mechanisms that are offered by certain compilers or compiler extensions. Examples include: the Microsoft Visual Studio /GS flag, Fedora/Red Hat FORTIFY_SOURCE GCC flag, StackGuard, and ProPolice, which provide various mechanisms including canary-based detection and range/index checking.
D3-SFCV (Stack Frame Canary Validation) from D3FEND [REF-1334] discusses canary-based detection in detail.
Effectiveness: Defense in Depth
Note:
This is not necessarily a complete solution, since these mechanisms only detect certain types of overflows. In addition, the result is still a denial of service, since the typical response is to exit the application.
Implementation
Consider adhering to the following rules when allocating and managing an application's memory:
Double check that your buffer is as large as you specify.
When using functions that accept a number of bytes to copy, such as strncpy(), be aware that if the destination buffer size is equal to the source buffer size, it may not NULL-terminate the string.
Check buffer boundaries if accessing the buffer in a loop and make sure there is no danger of writing past the allocated space.
If necessary, truncate all input strings to a reasonable length before passing them to the copy and concatenation functions.
Implementation
Strategy: Input Validation
Assume all input is malicious. Use an "accept known good" input validation strategy, i.e., use a list of acceptable inputs that strictly conform to specifications. Reject any input that does not strictly conform to specifications, or transform it into something that does.
When performing input validation, consider all potentially relevant properties, including length, type of input, the full range of acceptable values, missing or extra inputs, syntax, consistency across related fields, and conformance to business rules. As an example of business rule logic, "boat" may be syntactically valid because it only contains alphanumeric characters, but it is not valid if the input is only expected to contain colors such as "red" or "blue."
Do not rely exclusively on looking for malicious or malformed inputs. This is likely to miss at least one undesirable input, especially if the code's environment changes. This can give attackers enough room to bypass the intended validation. However, denylists can be useful for detecting potential attacks or determining which inputs are so malformed that they should be rejected outright.
Architecture and Design
For any security checks that are performed on the client side, ensure that these checks are duplicated on the server side, in order to avoid CWE-602. Attackers can bypass the client-side checks by modifying values after the checks have been performed, or by changing the client to remove the client-side checks entirely. Then, these modified values would be submitted to the server.
Operation; Build and Compilation
Strategy: Environment Hardening
Run or compile the software using features or extensions that randomly arrange the positions of a program's executable and libraries in memory. Because this makes the addresses unpredictable, it can prevent an attacker from reliably jumping to exploitable code.
Examples include Address Space Layout Randomization (ASLR) [REF-58] [REF-60] and Position-Independent Executables (PIE) [REF-64]. Imported modules may be similarly realigned if their default memory addresses conflict with other modules, in a process known as "rebasing" (for Windows) and "prelinking" (for Linux) [REF-1332] using randomly generated addresses. ASLR for libraries cannot be used in conjunction with prelink since it would require relocating the libraries at run-time, defeating the whole purpose of prelinking.
For more information on these techniques see D3-SAOR (Segment Address Offset Randomization) from D3FEND [REF-1335].
Effectiveness: Defense in Depth
Note: These techniques do not provide a complete solution. For instance, exploits frequently use a bug that discloses memory addresses in order to maximize reliability of code execution [REF-1337]. It has also been shown that a side-channel attack can bypass ASLR [REF-1333]
Operation
Strategy: Environment Hardening
Use a CPU and operating system that offers Data Execution Protection (using hardware NX or XD bits) or the equivalent techniques that simulate this feature in software, such as PaX [REF-60] [REF-61]. These techniques ensure that any instruction executed is exclusively at a memory address that is part of the code segment.
For more information on these techniques see D3-PSEP (Process Segment Execution Prevention) from D3FEND [REF-1336].
Effectiveness: Defense in Depth
Note: This is not a complete solution, since buffer overflows could be used to overwrite nearby variables to modify the software's state in dangerous ways. In addition, it cannot be used in cases in which self-modifying code is required. Finally, an attack could still cause a denial of service, since the typical response is to exit the application.
Build and Compilation; Operation
Most mitigating technologies at the compiler or OS level to date address only a subset of buffer overflow problems and rarely provide complete protection against even that subset. It is good practice to implement strategies to increase the workload of an attacker, such as leaving the attacker to guess an unknown value that changes every program execution.
Implementation
Replace unbounded copy functions with analogous functions that support length arguments, such as strcpy with strncpy. Create these if they are not available.
Effectiveness: Moderate
Note: This approach is still susceptible to calculation errors, including issues such as off-by-one errors (CWE-193) and incorrectly calculating buffer lengths (CWE-131).
Architecture and Design
Strategy: Enforcement by Conversion
When the set of acceptable objects, such as filenames or URLs, is limited or known, create a mapping from a set of fixed input values (such as numeric IDs) to the actual filenames or URLs, and reject all other inputs.
Architecture and Design; Operation
Strategy: Environment Hardening
Run your code using the lowest privileges that are required to accomplish the necessary tasks [REF-76]. If possible, create isolated accounts with limited privileges that are only used for a single task. That way, a successful attack will not immediately give the attacker access to the rest of the software or its environment. For example, database applications rarely need to run as the database administrator, especially in day-to-day operations.
Architecture and Design; Operation
Strategy: Sandbox or Jail
Run the code in a "jail" or similar sandbox environment that enforces strict boundaries between the process and the operating system. This may effectively restrict which files can be accessed in a particular directory or which commands can be executed by the software.
OS-level examples include the Unix chroot jail, AppArmor, and SELinux. In general, managed code may provide some protection. For example, java.io.FilePermission in the Java SecurityManager allows the software to specify restrictions on file operations.
This may not be a feasible solution, and it only limits the impact to the operating system; the rest of the application may still be subject to compromise.
Be careful to avoid CWE-243 and other weaknesses related to jails.
Effectiveness: Limited
Note: The effectiveness of this mitigation depends on the prevention capabilities of the specific sandbox or jail being used and might only help to reduce the scope of an attack, such as restricting the attacker to certain system calls or limiting the portion of the file system that can be accessed.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Use of Path Manipulation Function without Maximum-sized Buffer
CanFollow
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Seven Pernicious Kingdoms" (View-700)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Class: Assembly
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
The following code asks the user to enter their last name and then attempts to store the value entered in the last_name array.
(bad code)
Example Language: C
char last_name[20]; printf ("Enter your last name: "); scanf ("%s", last_name);
The problem with the code above is that it does not restrict or limit the size of the name entered by the user. If the user enters "Very_very_long_last_name" which is 24 characters long, then a buffer overflow will occur since the array can only hold 20 characters total.
Example 2
The following code attempts to create a local copy of a buffer to perform some manipulations to the data.
(bad code)
Example Language: C
void manipulate_string(char * string){
char buf[24]; strcpy(buf, string); ...
}
However, the programmer does not ensure that the size of the data pointed to by string will fit in the local buffer and copies the data with the potentially dangerous strcpy() function. This may result in a buffer overflow condition if an attacker can influence the contents of the string parameter.
Example 3
The code below calls the gets() function to read in data from the command line.
(bad code)
Example Language: C
char buf[24]; printf("Please enter your name and press <Enter>\n"); gets(buf); ...
}
However, gets() is inherently unsafe, because it copies all input from STDIN to the buffer without checking size. This allows the user to provide a string that is larger than the buffer size, resulting in an overflow condition.
Example 4
In the following example, a server accepts connections from a client and processes the client request. After accepting a client connection, the program will obtain client information using the gethostbyaddr method, copy the hostname of the client that connected to a local variable and output the hostname of the client to a log file.
(bad code)
Example Language: C
...
struct hostent *clienthp; char hostname[MAX_LEN];
// create server socket, bind to server address and listen on socket ...
// accept client connections and process requests int count = 0; for (count = 0; count < MAX_CONNECTIONS; count++) {
int clientlen = sizeof(struct sockaddr_in); int clientsocket = accept(serversocket, (struct sockaddr *)&clientaddr, &clientlen);
// process client request ... close(clientsocket);
}
} close(serversocket);
...
However, the hostname of the client that connected may be longer than the allocated size for the local hostname variable. This will result in a buffer overflow when copying the client hostname to the local variable using the strcpy method.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
By replacing a valid cookie value with an extremely long string of characters, an attacker may overflow the application's buffers.
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Automated Static Analysis
This weakness can often be detected using automated static analysis tools. Many modern tools use data flow analysis or constraint-based techniques to minimize the number of false positives.
Automated static analysis generally does not account for environmental considerations when reporting out-of-bounds memory operations. This can make it difficult for users to determine which warnings should be investigated first. For example, an analysis tool might report buffer overflows that originate from command line arguments in a program that is not expected to run with setuid or other special privileges.
Effectiveness: High
Note:Detection techniques for buffer-related errors are more mature than for most other weakness types.
Automated Dynamic Analysis
This weakness can be detected using dynamic tools and techniques that interact with the software using large test suites with many diverse inputs, such as fuzz testing (fuzzing), robustness testing, and fault injection. The software's operation may slow down, but it should not become unstable, crash, or generate incorrect results.
Manual Analysis
Manual analysis can be useful for finding this weakness, but it might not achieve desired code coverage within limited time constraints. This becomes difficult for weaknesses that must be considered for all inputs, since the attack surface can be too large.
Automated Static Analysis - Binary or Bytecode
According to SOAR, the following detection techniques may be useful:
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 07 - Characters and Strings (STR)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID could be used to map to real-world vulnerabilities in limited situations requiring careful review)
Reason
Frequent Misuse
Rationale
There are some indications that this CWE ID might be misused and selected simply because it mentions "buffer overflow" - an increasingly vague term. This CWE entry is only appropriate for "Buffer Copy" operations (not buffer reads), in which where there is no "Checking [the] Size of Input", and (by implication of the copy) writing past the end of the buffer.
Comments
If the vulnerability being analyzed involves out-of-bounds reads, then consider CWE-125 or descendants. For root cause analysis: if there is any input validation, consider children of CWE-20 such as CWE-1284. If there is a calculation error for buffer sizes, consider CWE-131 or similar.
Notes
Relationship
At the code level, stack-based and heap-based overflows do not differ significantly, so there usually is not a need to distinguish them. From the attacker perspective, they can be quite different, since different techniques are required to exploit them.
Terminology
Many issues that are now called "buffer overflows" are substantively different than the "classic" overflow, including entirely different bug types that rely on overflow exploit techniques, such as integer signedness errors, integer overflows, and format string bugs. This imprecise terminology can make it difficult to determine which variant is being reported.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Unbounded Transfer ('classic overflow')
7 Pernicious Kingdoms
Buffer Overflow
CLASP
Buffer overflow
OWASP Top Ten 2004
A1
CWE More Specific
Unvalidated Input
OWASP Top Ten 2004
A5
CWE More Specific
Buffer Overflows
CERT C Secure Coding
STR31-C
Exact
Guarantee that storage for strings has sufficient space for character data and the null terminator
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 3, "Nonexecutable Stack", Page 76. 1st Edition. Addison Wesley. 2006.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 5, "Protection Mechanisms", Page 189. 1st Edition. Addison Wesley. 2006.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 8, "C String Handling", Page 388. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product reads from a buffer using buffer access mechanisms such as indexes or pointers that reference memory locations after the targeted buffer.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory
Scope: Confidentiality
Bypass Protection Mechanism
Scope: Confidentiality
By reading out-of-bounds memory, an attacker might be able to get secret values, such as memory addresses, which can be bypass protection mechanisms such as ASLR in order to improve the reliability and likelihood of exploiting a separate weakness to achieve code execution instead of just denial of service.
DoS: Crash, Exit, or Restart
Scope: Availability, Integrity
An attacker might be able to cause a crash or other denial of service by causing the product to read a memory location that is not allowed (such as a segmentation fault), or to cause other conditions in which the read operation returns more data than is expected.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Demonstrative Examples
Example 1
In the following C/C++ example the method processMessageFromSocket() will get a message from a socket, placed into a buffer, and will parse the contents of the buffer into a structure that contains the message length and the message body. A for loop is used to copy the message body into a local character string which will be passed to another method for processing.
//Ignoring possibliity that buffer > BUFFER_SIZE if (getMessage(socket, buffer, BUFFER_SIZE) > 0) {
// place contents of the buffer into message structure ExMessage *msg = recastBuffer(buffer);
// copy message body into string for processing int index; for (index = 0; index < msg->msgLength; index++) {
message[index] = msg->msgBody[index];
} message[index] = '\0';
// process message success = processMessage(message);
} return success;
}
However, the message length variable from the structure is used as the condition for ending the for loop without validating that the message length variable accurately reflects the length of the message body (CWE-606). This can result in a buffer over-read (CWE-125) by reading from memory beyond the bounds of the buffer if the message length variable indicates a length that is longer than the size of a message body (CWE-130).
Example 2
The following C/C++ example demonstrates a buffer over-read due to a missing NULL terminator. The main method of a pattern matching utility that looks for a specific pattern within a specific file uses the string strncopy() method to copy the command line user input file name and pattern to the Filename and Pattern character arrays respectively.
(bad code)
Example Language: C
int main(int argc, char **argv) {
char Filename[256]; char Pattern[32];
/* Validate number of parameters and ensure valid content */ ...
/* copy filename parameter to variable, may cause off-by-one overflow */ strncpy(Filename, argv[1], sizeof(Filename));
/* copy pattern parameter to variable, may cause off-by-one overflow */ strncpy(Pattern, argv[2], sizeof(Pattern));
printf("Searching file: %s for the pattern: %s\n", Filename, Pattern); Scan_File(Filename, Pattern);
}
However, the code do not take into account that strncpy() will not add a NULL terminator when the source buffer is equal in length of longer than that provide size attribute. Therefore if a user enters a filename or pattern that are the same size as (or larger than) their respective character arrays, a NULL terminator will not be added (CWE-170) which leads to the printf() read beyond the expected end of the Filename and Pattern buffers.
To fix this problem, be sure to subtract 1 from the sizeof() call to allow room for the null byte to be added.
(good code)
Example Language: C
/* copy filename parameter to variable, no off-by-one overflow */ strncpy(Filename, argv[2], sizeof(Filename)-1); Filename[255]='\0';
/* copy pattern parameter to variable, no off-by-one overflow */ strncpy(Pattern, argv[3], sizeof(Pattern)-1);
Pattern[31]='\0';
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: "Heartbleed" bug receives an inconsistent length parameter (CWE-130) enabling an out-of-bounds read (CWE-126), returning memory that could include private cryptographic keys and other sensitive data.
Chain: product does not handle when an input string is not NULL terminated, leading to buffer over-read or heap-based buffer overflow.
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
These problems may be resultant from missing sentinel values (CWE-463) or trusting a user-influenced input length variable.
Other
A buffer over-read typically occurs when the pointer or its index is incremented to a position past the end of the buffer or when pointer arithmetic results in a position after the valid memory location.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Buffer over-read
Software Fault Patterns
SFP8
Faulty Buffer Access
References
[REF-1034]
Raoul Strackx, Yves Younan, Pieter Philippaerts, Frank Piessens, Sven Lachmund and Thomas Walter. "Breaking the memory secrecy assumption". ACM. 2009-03-31.
<https://dl.acm.org/doi/10.1145/1519144.1519145>.
(URL validated: 2023-04-07)
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product reads from a buffer using buffer access mechanisms such as indexes or pointers that reference memory locations prior to the targeted buffer.
Extended Description
This typically occurs when the pointer or its index is decremented to a position before the buffer, when pointer arithmetic results in a position before the beginning of the valid memory location, or when a negative index is used. This may result in exposure of sensitive information or possibly a crash.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory
Scope: Confidentiality
Bypass Protection Mechanism
Scope: Confidentiality
By reading out-of-bounds memory, an attacker might be able to get secret values, such as memory addresses, which can be bypass protection mechanisms such as ASLR in order to improve the reliability and likelihood of exploiting a separate weakness to achieve code execution instead of just denial of service.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
HTML conversion package has a buffer under-read, allowing a crash
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Research Gap
Under-studied.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Buffer under-read
Software Fault Patterns
SFP8
Faulty Buffer Access
References
[REF-1034]
Raoul Strackx, Yves Younan, Pieter Philippaerts, Frank Piessens, Sven Lachmund and Thomas Walter. "Breaking the memory secrecy assumption". ACM. 2009-03-31.
<https://dl.acm.org/doi/10.1145/1519144.1519145>.
(URL validated: 2023-04-07)
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product writes to a buffer using an index or pointer that references a memory location prior to the beginning of the buffer.
Extended Description
This typically occurs when a pointer or its index is decremented to a position before the buffer, when pointer arithmetic results in a position before the beginning of the valid memory location, or when a negative index is used.
Alternate Terms
buffer underrun
Some prominent vendors and researchers use the term "buffer underrun". "Buffer underflow" is more commonly used, although both terms are also sometimes used to describe a buffer under-read (CWE-127).
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; DoS: Crash, Exit, or Restart
Scope: Integrity, Availability
Out of bounds memory access will very likely result in the corruption of relevant memory, and perhaps instructions, possibly leading to a crash.
Execute Unauthorized Code or Commands; Modify Memory; Bypass Protection Mechanism; Other
Scope: Integrity, Confidentiality, Availability, Access Control, Other
If the corrupted memory can be effectively controlled, it may be possible to execute arbitrary code. If the corrupted memory is data rather than instructions, the system will continue to function with improper changes, possibly in violation of an implicit or explicit policy. The consequences would only be limited by how the affected data is used, such as an adjacent memory location that is used to specify whether the user has special privileges.
Bypass Protection Mechanism; Other
Scope: Access Control, Other
When the consequence is arbitrary code execution, this can often be used to subvert any other security service.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Choose a language that is not susceptible to these issues.
Implementation
All calculated values that are used as index or for pointer arithmetic should be validated to ensure that they are within an expected range.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
In the following C/C++ example, a utility function is used to trim trailing whitespace from a character string. The function copies the input string to a local character string and uses a while statement to remove the trailing whitespace by moving backward through the string and overwriting whitespace with a NUL character.
(bad code)
Example Language: C
char* trimTrailingWhitespace(char *strMessage, int length) {
However, this function can cause a buffer underwrite if the input character string contains all whitespace. On some systems the while statement will move backwards past the beginning of a character string and will call the isspace() function on an address outside of the bounds of the local buffer.
Example 2
The following is an example of code that may result in a buffer underwrite. This code is attempting to replace the substring "Replace Me" in destBuf with the string stored in srcBuf. It does so by using the function strstr(), which returns a pointer to the found substring in destBuf. Using pointer arithmetic, the starting index of the substring is found.
(bad code)
Example Language: C
int main() {
...
char *result = strstr(destBuf, "Replace Me");
int idx = result - destBuf;
strcpy(&destBuf[idx], srcBuf);
...
}
In the case where the substring is not found in destBuf, strstr() will return NULL, causing the pointer arithmetic to be undefined, potentially setting the value of idx to a negative number. If idx is negative, this will result in a buffer underwrite of destBuf.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Buffer underflow from an all-whitespace string, which causes a counter to be decremented before the buffer while looking for a non-whitespace character.
Buffer underflow due to mishandled special characters
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
This could be resultant from several errors, including a bad offset or an array index that decrements before the beginning of the buffer (see CWE-129).
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
UNDER - Boundary beginning violation ('buffer underflow'?)
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The code uses an operator for comparison when the intention was to perform an assignment.
Extended Description
In many languages, the compare statement is very close in appearance to the assignment statement; they are often confused.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Unexpected State
Scope: Availability, Integrity
The assignment will not take place, which should cause obvious program execution problems.
Potential Mitigations
Phase(s)
Mitigation
Testing
Many IDEs and static analysis products will detect this problem.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
This bug primarily originates from a typo.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
Low
Demonstrative Examples
Example 1
The following example demonstrates the weakness.
(bad code)
Example Language: Java
void called(int foo) {
foo==1; if (foo==1) System.out.println("foo\n");
} int main() {
called(2); return 0;
}
Example 2
The following C/C++ example shows a simple implementation of a stack that includes methods for adding and removing integer values from the stack. The example uses pointers to add and remove integer values to the stack array variable.
(bad code)
Example Language: C
#define SIZE 50 int *tos, *p1, stack[SIZE];
void push(int i) {
p1++; if(p1==(tos+SIZE)) {
// Print stack overflow error message and exit
} *p1 == i;
}
int pop(void) {
if(p1==tos) {
// Print stack underflow error message and exit
} p1--; return *(p1+1);
}
int main(int argc, char *argv[]) {
// initialize tos and p1 to point to the top of stack tos = stack; p1 = stack; // code to add and remove items from stack ... return 0;
}
The push method includes an expression to assign the integer value to the location in the stack pointed to by the pointer variable.
However, this expression uses the comparison operator "==" rather than the assignment operator "=". The result of using the comparison operator instead of the assignment operator causes erroneous values to be entered into the stack and can cause unexpected results.
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
Comprehensive Categorization: Insufficient Control Flow Management
Vulnerability Mapping Notes
Usage
ALLOWED
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
CWE-733: Compiler Optimization Removal or Modification of Security-critical Code
Weakness ID: 733
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The developer builds a security-critical protection mechanism into the software, but the compiler optimizes the program such that the mechanism is removed or modified.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Bypass Protection Mechanism; Other
Scope: Access Control, Other
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Class: Compiled
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The following code reads a password from the user, uses the password to connect to a back-end mainframe and then attempts to scrub the password from memory using memset().
(bad code)
Example Language: C
void GetData(char *MFAddr) {
char pwd[64]; if (GetPasswordFromUser(pwd, sizeof(pwd))) {
if (ConnectToMainframe(MFAddr, pwd)) {
// Interaction with mainframe
}
} memset(pwd, 0, sizeof(pwd));
}
The code in the example will behave correctly if it is executed verbatim, but if the code is compiled using an optimizing compiler, such as Microsoft Visual C++ .NET or GCC 3.x, then the call to memset() will be removed as a dead store because the buffer pwd is not used after its value is overwritten [18]. Because the buffer pwd contains a sensitive value, the application may be vulnerable to attack if the data are left memory resident. If attackers are able to access the correct region of memory, they may use the recovered password to gain control of the system.
It is common practice to overwrite sensitive data manipulated in memory, such as passwords or cryptographic keys, in order to prevent attackers from learning system secrets. However, with the advent of optimizing compilers, programs do not always behave as their source code alone would suggest. In the example, the compiler interprets the call to memset() as dead code because the memory being written to is not subsequently used, despite the fact that there is clearly a security motivation for the operation to occur. The problem here is that many compilers, and in fact many programming languages, do not take this and other security concerns into consideration in their efforts to improve efficiency.
Attackers typically exploit this type of vulnerability by using a core dump or runtime mechanism to access the memory used by a particular application and recover the secret information. Once an attacker has access to the secret information, it is relatively straightforward to further exploit the system and possibly compromise other resources with which the application interacts.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: compiler optimization (CWE-733) removes or modifies code used to detect integer overflow (CWE-190), allowing out-of-bounds write (CWE-787).
Detection
Methods
Method
Details
Black Box
This specific weakness is impossible to detect using black box methods. While an analyst could examine memory to see that it has not been scrubbed, an analysis of the executable would not be successful. This is because the compiler has already removed the relevant code. Only the source code shows whether the programmer intended to clear the memory or not, so this weakness is indistinguishable from others.
White Box
This weakness is only detectable using white box methods (see black box detection factor). Careful analysis is required to determine if the code is likely to be removed by the compiler.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
Sensitive memory is cleared according to the source code, but compiler optimizations leave the memory untouched when it is not read from again, aka "dead store removal."
Extended Description
This compiler optimization error occurs when:
Secret data are stored in memory.
The secret data are scrubbed from memory by overwriting its contents.
The source code is compiled using an optimizing compiler, which identifies and removes the function that overwrites the contents as a dead store because the memory is not used subsequently.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory; Bypass Protection Mechanism
Scope: Confidentiality, Access Control
This weakness will allow data that has not been cleared from memory to be read. If this data contains sensitive password information, then an attacker can read the password and use the information to bypass protection mechanisms.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Store the sensitive data in a "volatile" memory location if available.
Build and Compilation
If possible, configure your compiler so that it does not remove dead stores.
Architecture and Design
Where possible, encrypt sensitive data that are used by a software system.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Compiler Optimization Removal or Modification of Security-critical Code
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Build and Compilation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The following code reads a password from the user, uses the password to connect to a back-end mainframe and then attempts to scrub the password from memory using memset().
(bad code)
Example Language: C
void GetData(char *MFAddr) {
char pwd[64]; if (GetPasswordFromUser(pwd, sizeof(pwd))) {
if (ConnectToMainframe(MFAddr, pwd)) {
// Interaction with mainframe
}
} memset(pwd, 0, sizeof(pwd));
}
The code in the example will behave correctly if it is executed verbatim, but if the code is compiled using an optimizing compiler, such as Microsoft Visual C++ .NET or GCC 3.x, then the call to memset() will be removed as a dead store because the buffer pwd is not used after its value is overwritten [18]. Because the buffer pwd contains a sensitive value, the application may be vulnerable to attack if the data are left memory resident. If attackers are able to access the correct region of memory, they may use the recovered password to gain control of the system.
It is common practice to overwrite sensitive data manipulated in memory, such as passwords or cryptographic keys, in order to prevent attackers from learning system secrets. However, with the advent of optimizing compilers, programs do not always behave as their source code alone would suggest. In the example, the compiler interprets the call to memset() as dead code because the memory being written to is not subsequently used, despite the fact that there is clearly a security motivation for the operation to occur. The problem here is that many compilers, and in fact many programming languages, do not take this and other security concerns into consideration in their efforts to improve efficiency.
Attackers typically exploit this type of vulnerability by using a core dump or runtime mechanism to access the memory used by a particular application and recover the secret information. Once an attacker has access to the secret information, it is relatively straightforward to further exploit the system and possibly compromise other resources with which the application interacts.
Detection
Methods
Method
Details
Black Box
This specific weakness is impossible to detect using black box methods. While an analyst could examine memory to see that it has not been scrubbed, an analysis of the executable would not be successful. This is because the compiler has already removed the relevant code. Only the source code shows whether the programmer intended to clear the memory or not, so this weakness is indistinguishable from others.
White Box
This weakness is only detectable using white box methods (see black box detection factor). Careful analysis is required to determine if the code is likely to be removed by the compiler.
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 49 - Miscellaneous (MSC)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
7 Pernicious Kingdoms
Insecure Compiler Optimization
PLOVER
Sensitive memory uncleared by compiler optimization
OWASP Top Ten 2004
A8
CWE More Specific
Insecure Storage
CERT C Secure Coding
MSC06-C
Be aware of compiler optimization when dealing with sensitive data
CWE-362: Concurrent Execution using Shared Resource with Improper Synchronization ('Race Condition')
Weakness ID: 362
Vulnerability Mapping:ALLOWEDThis CWE ID could be used to map to real-world vulnerabilities in limited situations requiring careful review
(with careful review of mapping notes)
Abstraction:
ClassClass - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product contains a concurrent code sequence that requires temporary, exclusive access to a shared resource, but a timing window exists in which the shared resource can be modified by another code sequence operating concurrently.
Extended Description
A race condition occurs within concurrent environments, and it is effectively a property of a code sequence. Depending on the context, a code sequence may be in the form of a function call, a small number of instructions, a series of program invocations, etc.
A race condition violates these properties, which are closely related:
Exclusivity - the code sequence is given exclusive access to the shared resource, i.e., no other code sequence can modify properties of the shared resource before the original sequence has completed execution.
Atomicity - the code sequence is behaviorally atomic, i.e., no other thread or process can concurrently execute the same sequence of instructions (or a subset) against the same resource.
A race condition exists when an "interfering code sequence" can still access the shared resource, violating exclusivity.
The interfering code sequence could be "trusted" or "untrusted." A trusted interfering code sequence occurs within the product; it cannot be modified by the attacker, and it can only be invoked indirectly. An untrusted interfering code sequence can be authored directly by the attacker, and typically it is external to the vulnerable product.
Alternate Terms
Race Condition
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
When a race condition makes it possible to bypass a resource cleanup routine or trigger multiple initialization routines, it may lead to resource exhaustion.
DoS: Crash, Exit, or Restart; DoS: Instability
Scope: Availability
When a race condition allows multiple control flows to access a resource simultaneously, it might lead the product(s) into unexpected states, possibly resulting in a crash.
Read Files or Directories; Read Application Data
Scope: Confidentiality, Integrity
When a race condition is combined with predictable resource names and loose permissions, it may be possible for an attacker to overwrite or access confidential data (CWE-59).
Execute Unauthorized Code or Commands; Gain Privileges or Assume Identity; Bypass Protection Mechanism
Scope: Access Control
This can have security implications when the expected synchronization is in security-critical code, such as recording whether a user is authenticated or modifying important state information that should not be influenced by an outsider.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
In languages that support it, use synchronization primitives. Only wrap these around critical code to minimize the impact on performance.
Architecture and Design
Use thread-safe capabilities such as the data access abstraction in Spring.
Architecture and Design
Minimize the usage of shared resources in order to remove as much complexity as possible from the control flow and to reduce the likelihood of unexpected conditions occurring.
Additionally, this will minimize the amount of synchronization necessary and may even help to reduce the likelihood of a denial of service where an attacker may be able to repeatedly trigger a critical section (CWE-400).
Implementation
When using multithreading and operating on shared variables, only use thread-safe functions.
Implementation
Use atomic operations on shared variables. Be wary of innocent-looking constructs such as "x++". This may appear atomic at the code layer, but it is actually non-atomic at the instruction layer, since it involves a read, followed by a computation, followed by a write.
Implementation
Use a mutex if available, but be sure to avoid related weaknesses such as CWE-412.
Implementation
Avoid double-checked locking (CWE-609) and other implementation errors that arise when trying to avoid the overhead of synchronization.
Implementation
Disable interrupts or signals over critical parts of the code, but also make sure that the code does not go into a large or infinite loop.
Implementation
Use the volatile type modifier for critical variables to avoid unexpected compiler optimization or reordering. This does not necessarily solve the synchronization problem, but it can help.
Architecture and Design; Operation
Strategy: Environment Hardening
Run your code using the lowest privileges that are required to accomplish the necessary tasks [REF-76]. If possible, create isolated accounts with limited privileges that are only used for a single task. That way, a successful attack will not immediately give the attacker access to the rest of the software or its environment. For example, database applications rarely need to run as the database administrator, especially in day-to-day operations.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Composite - a Compound Element that consists of two or more distinct weaknesses, in which all weaknesses must be present at the same time in order for a potential vulnerability to arise. Removing any of the weaknesses eliminates or sharply reduces the risk. One weakness, X, can be "broken down" into component weaknesses Y and Z. There can be cases in which one weakness might not be essential to a composite, but changes the nature of the composite when it becomes a vulnerability.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses for Simplified Mapping of Published Vulnerabilities
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Architecture and Design
Implementation
Programmers may assume that certain code sequences execute too quickly to be affected by an interfering code sequence; when they are not, this violates atomicity. For example, the single "x++" statement may appear atomic at the code layer, but it is actually non-atomic at the instruction layer, since it involves a read (the original value of x), followed by a computation (x+1), followed by a write (save the result to x).
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Sometimes Prevalent)
C++
(Sometimes Prevalent)
Java
(Sometimes Prevalent)
Technologies
Class: Mobile
(Undetermined Prevalence)
Class: ICS/OT
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
This code could be used in an e-commerce application that supports transfers between accounts. It takes the total amount of the transfer, sends it to the new account, and deducts the amount from the original account.
} SendNewBalanceToDatabase($newbalance); NotifyUser("Transfer of $transfer_amount succeeded."); NotifyUser("New balance: $newbalance");
A race condition could occur between the calls to GetBalanceFromDatabase() and SendNewBalanceToDatabase().
Suppose the balance is initially 100.00. An attack could be constructed as follows:
(attack code)
Example Language: Other
In the following pseudocode, the attacker makes two simultaneous calls of the program, CALLER-1 and CALLER-2. Both callers are for the same user account. CALLER-1 (the attacker) is associated with PROGRAM-1 (the instance that handles CALLER-1). CALLER-2 is associated with PROGRAM-2. CALLER-1 makes a transfer request of 80.00. PROGRAM-1 calls GetBalanceFromDatabase and sets $balance to 100.00 PROGRAM-1 calculates $newbalance as 20.00, then calls SendNewBalanceToDatabase(). Due to high server load, the PROGRAM-1 call to SendNewBalanceToDatabase() encounters a delay. CALLER-2 makes a transfer request of 1.00. PROGRAM-2 calls GetBalanceFromDatabase() and sets $balance to 100.00. This happens because the previous PROGRAM-1 request was not processed yet. PROGRAM-2 determines the new balance as 99.00. After the initial delay, PROGRAM-1 commits its balance to the database, setting it to 20.00. PROGRAM-2 sends a request to update the database, setting the balance to 99.00
At this stage, the attacker should have a balance of 19.00 (due to 81.00 worth of transfers), but the balance is 99.00, as recorded in the database.
To prevent this weakness, the programmer has several options, including using a lock to prevent multiple simultaneous requests to the web application, or using a synchronization mechanism that includes all the code between GetBalanceFromDatabase() and SendNewBalanceToDatabase().
Example 2
The following function attempts to acquire a lock in order to perform operations on a shared resource.
(bad code)
Example Language: C
void f(pthread_mutex_t *mutex) {
pthread_mutex_lock(mutex);
/* access shared resource */
pthread_mutex_unlock(mutex);
}
However, the code does not check the value returned by pthread_mutex_lock() for errors. If pthread_mutex_lock() cannot acquire the mutex for any reason, the function may introduce a race condition into the program and result in undefined behavior.
In order to avoid data races, correctly written programs must check the result of thread synchronization functions and appropriately handle all errors, either by attempting to recover from them or reporting them to higher levels.
(good code)
Example Language: C
int f(pthread_mutex_t *mutex) {
int result;
result = pthread_mutex_lock(mutex); if (0 != result)
return result;
/* access shared resource */
return pthread_mutex_unlock(mutex);
}
Example 3
Suppose a processor's Memory Management Unit (MMU) has 5 other shadow MMUs to distribute its workload for its various cores. Each MMU has the start address and end address of "accessible" memory. Any time this accessible range changes (as per the processor's boot status), the main MMU sends an update message to all the shadow MMUs.
Suppose the interconnect fabric does not prioritize such "update" packets over other general traffic packets. This introduces a race condition. If an attacker can flood the target with enough messages so that some of those attack packets reach the target before the new access ranges gets updated, then the attacker can leverage this scenario.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Go application for cloud management creates a world-writable sudoers file that allows local attackers to inject sudo rules and escalate privileges to root by winning a race condition.
Chain: race condition (CWE-362) in anti-malware product allows deletion of files by creating a junction (CWE-1386) and using hard links during the time window in which a temporary file is created and deleted.
Chain: chipset has a race condition (CWE-362) between when an interrupt handler detects an attempt to write-enable the BIOS (in violation of the lock bit), and when the handler resets the write-enable bit back to 0, allowing attackers to issue BIOS writes during the timing window [REF-1237].
chain: time-of-check time-of-use (TOCTOU) race condition in program allows bypass of protection mechanism that was designed to prevent symlink attacks.
chain: time-of-check time-of-use (TOCTOU) race condition in program allows bypass of protection mechanism that was designed to prevent symlink attacks.
Chain: Signal handler contains too much functionality (CWE-828), introducing a race condition (CWE-362) that leads to a double free (CWE-415).
Detection
Methods
Method
Details
Black Box
Black box methods may be able to identify evidence of race conditions via methods such as multiple simultaneous connections, which may cause the software to become instable or crash. However, race conditions with very narrow timing windows would not be detectable.
White Box
Common idioms are detectable in white box analysis, such as time-of-check-time-of-use (TOCTOU) file operations (CWE-367), or double-checked locking (CWE-609).
Automated Dynamic Analysis
This weakness can be detected using dynamic tools and techniques that interact with the software using large test suites with many diverse inputs, such as fuzz testing (fuzzing), robustness testing, and fault injection. The software's operation may slow down, but it should not become unstable, crash, or generate incorrect results.
Race conditions may be detected with a stress-test by calling the software simultaneously from a large number of threads or processes, and look for evidence of any unexpected behavior.
Insert breakpoints or delays in between relevant code statements to artificially expand the race window so that it will be easier to detect.
Effectiveness: Moderate
Automated Static Analysis - Binary or Bytecode
According to SOAR, the following detection techniques may be useful:
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
ICS Engineering (Construction/Deployment): Security Gaps in Commissioning
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2023 CWE Top 25 Most Dangerous Software Weaknesses
Vulnerability Mapping Notes
Usage
ALLOWED-WITH-REVIEW
(this CWE ID could be used to map to real-world vulnerabilities in limited situations requiring careful review)
Reason
Abstraction
Rationale
This CWE entry is a Class and might have Base-level children that would be more appropriate
Comments
Examine children of this entry to see if there is a better fit
Notes
Research Gap
Race conditions in web applications are under-studied and probably under-reported. However, in 2008 there has been growing interest in this area.
Research Gap
Much of the focus of race condition research has been in Time-of-check Time-of-use (TOCTOU) variants (CWE-367), but many race conditions are related to synchronization problems that do not necessarily require a time-of-check.
Research Gap
From a classification/taxonomy perspective, the relationships between concurrency and program state need closer investigation and may be useful in organizing related issues.
Maintenance
The relationship between race conditions and synchronization problems (CWE-662) needs to be further developed. They are not necessarily two perspectives of the same core concept, since synchronization is only one technique for avoiding race conditions, and synchronization can be used for other purposes besides race condition prevention.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Race Conditions
The CERT Oracle Secure Coding Standard for Java (2011)
VNA03-J
Do not assume that a group of calls to independently atomic methods is atomic
CWE-243: Creation of chroot Jail Without Changing Working Directory
Weakness ID: 243
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses the chroot() system call to create a jail, but does not change the working directory afterward. This does not prevent access to files outside of the jail.
Extended Description
Improper use of chroot() may allow attackers to escape from the chroot jail. The chroot() function call does not change the process's current working directory, so relative paths may still refer to file system resources outside of the chroot jail after chroot() has been called.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Files or Directories
Scope: Confidentiality
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The chroot() system call allows a process to change its perception of the root directory of the file system. After properly invoking chroot(), a process cannot access any files outside the directory tree defined by the new root directory. Such an environment is called a chroot jail and is commonly used to prevent the possibility that a processes could be subverted and used to access unauthorized files. For instance, many FTP servers run in chroot jails to prevent an attacker who discovers a new vulnerability in the server from being able to download the password file or other sensitive files on the system.
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
REALIZATION: This weakness is caused during implementation of an architectural security tactic.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Operating Systems
Class: Unix
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
Consider the following source code from a (hypothetical) FTP server:
This code is responsible for reading a filename from the network, opening the corresponding file on the local machine, and sending the contents over the network. This code could be used to implement the FTP GET command. The FTP server calls chroot() in its initialization routines in an attempt to prevent access to files outside of /var/ftproot. But because the server does not change the current working directory by calling chdir("/"), an attacker could request the file "../../../../../etc/passwd" and obtain a copy of the system password file.
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Affected Resources
File or Directory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The accidental deletion of a data-structure sentinel can cause serious programming logic problems.
Extended Description
Often times data-structure sentinels are used to mark structure of the data structure. A common example of this is the null character at the end of strings. Another common example is linked lists which may contain a sentinel to mark the end of the list. It is dangerous to allow this type of control data to be easily accessible. Therefore, it is important to protect from the deletion or modification outside of some wrapper interface which provides safety.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Other
Scope: Availability, Other
Generally this error will cause the data structure to not work properly.
Other
Scope: Authorization, Other
If a control character, such as NULL is removed, one may cause resource access control problems.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Use an abstraction library to abstract away risky APIs. Not a complete solution.
Build and Compilation
Strategy: Compilation or Build Hardening
Run or compile the software using features or extensions that automatically provide a protection mechanism that mitigates or eliminates buffer overflows.
For example, certain compilers and extensions provide automatic buffer overflow detection mechanisms that are built into the compiled code. Examples include the Microsoft Visual Studio /GS flag, Fedora/Red Hat FORTIFY_SOURCE GCC flag, StackGuard, and ProPolice.
Effectiveness: Defense in Depth
Note: This is not necessarily a complete solution, since these mechanisms can only detect certain types of overflows. In addition, an attack could still cause a denial of service, since the typical response is to exit the application.
Operation
Use OS-level preventative functionality. Not a complete solution.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Demonstrative Examples
Example 1
This example creates a null terminated string and prints it contents.
(bad code)
Example Language: C
char *foo; int counter; foo=calloc(sizeof(char)*10);
for (counter=0;counter!=10;counter++) {
foo[counter]='a';
printf("%s\n",foo); }
The string foo has space for 9 characters and a null terminator, but 10 characters are written to it. As a result, the string foo is not null terminated and calling printf() on it will have unpredictable and possibly dangerous results.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 8, "NUL-Termination Problems", Page 452. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product calls free() twice on the same memory address.
Alternate Terms
Double-free
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
When a program calls free() twice with the same argument, the program's memory management data structures may become corrupted, potentially leading to the reading or modification of unexpected memory addresses. This corruption can cause the program to crash or, in some circumstances, cause two later calls to malloc() to return the same pointer. If malloc() returns the same value twice and the program later gives the attacker control over the data that is written into this doubly-allocated memory, the program becomes vulnerable to a buffer overflow attack.
Doubly freeing memory may result in a write-what-where condition, allowing an attacker to execute arbitrary code.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Choose a language that provides automatic memory management.
Implementation
Ensure that each allocation is freed only once. After freeing a chunk, set the pointer to NULL to ensure the pointer cannot be freed again. In complicated error conditions, be sure that clean-up routines respect the state of allocation properly. If the language is object oriented, ensure that object destructors delete each chunk of memory only once.
Implementation
Use a static analysis tool to find double free instances.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Operation on a Resource after Expiration or Release
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Operation on a Resource after Expiration or Release
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Operation on a Resource after Expiration or Release
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
The following code shows a simple example of a double free vulnerability.
(bad code)
Example Language: C
char* ptr = (char*)malloc (SIZE);
...
if (abrt) {
free(ptr);
}
...
free(ptr);
Double free vulnerabilities have two common (and sometimes overlapping) causes:
Error conditions and other exceptional circumstances
Confusion over which part of the program is responsible for freeing the memory
Although some double free vulnerabilities are not much more complicated than this example, most are spread out across hundreds of lines of code or even different files. Programmers seem particularly susceptible to freeing global variables more than once.
Example 2
While contrived, this code should be exploitable on Linux distributions that do not ship with heap-chunk check summing turned on.
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
This is usually resultant from another weakness, such as an unhandled error or race condition between threads. It could also be primary to weaknesses such as buffer overflows.
Theoretical
It could be argued that Double Free would be most appropriately located as a child of "Use after Free", but "Use" and "Release" are considered to be distinct operations within vulnerability theory, therefore this is more accurately "Release of a Resource after Expiration or Release", which doesn't exist yet.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
DFREE - Double-Free Vulnerability
7 Pernicious Kingdoms
Double Free
CLASP
Doubly freeing memory
CERT C Secure Coding
MEM00-C
Allocate and free memory in the same module, at the same level of abstraction
CERT C Secure Coding
MEM01-C
Store a new value in pointers immediately after free()
CERT C Secure Coding
MEM30-C
CWE More Specific
Do not access freed memory
CERT C Secure Coding
MEM31-C
Free dynamically allocated memory exactly once
Software Fault Patterns
SFP12
Faulty Memory Release
References
[REF-44]
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 8: C++ Catastrophes." Page 143. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 7, "Double Frees", Page 379. 1st Edition. Addison Wesley. 2006.
CWE-462: Duplicate Key in Associative List (Alist)
Weakness ID: 462
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
Duplicate keys in associative lists can lead to non-unique keys being mistaken for an error.
Extended Description
A duplicate key entry -- if the alist is designed properly -- could be used as a constant time replace function. However, duplicate key entries could be inserted by mistake. Because of this ambiguity, duplicate key entries in an association list are not recommended and should not be allowed.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Quality Degradation; Varies by Context
Scope: Other
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Use a hash table instead of an alist.
Architecture and Design
Use an alist which checks the uniqueness of hash keys with each entry before inserting the entry.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Use of Multiple Resources with Duplicate Identifier
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Likelihood Of Exploit
Low
Demonstrative Examples
Example 1
The following code adds data to a list and then attempts to sort the data.
(bad code)
Example Language: Python
alist = [] while (foo()): #now assume there is a string data with a key basename
queue.append(basename,data) queue.sort()
Since basename is not necessarily unique, this may not sort how one would like it to be.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Duplicate key in associative list (alist)
CERT C Secure Coding
ENV02-C
Beware of multiple environment variables with the same effective name
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product dereferences a pointer that contains a location for memory that was previously valid, but is no longer valid.
Extended Description
When a product releases memory, but it maintains a pointer to that memory, then the memory might be re-allocated at a later time. If the original pointer is accessed to read or write data, then this could cause the product to read or modify data that is in use by a different function or process. Depending on how the newly-allocated memory is used, this could lead to a denial of service, information exposure, or code execution.
Alternate Terms
Dangling pointer
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory
Scope: Confidentiality
If the expired pointer is used in a read operation, an attacker might be able to control data read in by the application.
DoS: Crash, Exit, or Restart
Scope: Availability
If the expired pointer references a memory location that is not accessible to the product, or points to a location that is "malformed" (such as NULL) or larger than expected by a read or write operation, then a crash may occur.
Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
If the expired pointer is used in a function call, or points to unexpected data in a write operation, then code execution may be possible.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Choose a language that provides automatic memory management.
Implementation
When freeing pointers, be sure to set them to NULL once they are freed. However, the utilization of multiple or complex data structures may lower the usefulness of this strategy.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Operation on a Resource after Expiration or Release
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The following code shows a simple example of a use after free error:
(bad code)
Example Language: C
char* ptr = (char*)malloc (SIZE); if (err) {
abrt = 1; free(ptr);
} ... if (abrt) {
logError("operation aborted before commit", ptr);
}
When an error occurs, the pointer is immediately freed. However, this pointer is later incorrectly used in the logError function.
Example 2
The following code shows a simple example of a double free error:
(bad code)
Example Language: C
char* ptr = (char*)malloc (SIZE); ... if (abrt) {
free(ptr);
} ... free(ptr);
Double free vulnerabilities have two common (and sometimes overlapping) causes:
Error conditions and other exceptional circumstances
Confusion over which part of the program is responsible for freeing the memory
Although some double free vulnerabilities are not much more complicated than the previous example, most are spread out across hundreds of lines of code or even different files. Programmers seem particularly susceptible to freeing global variables more than once.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: a message having an unknown message type may cause a reference to uninitialized memory resulting in a null pointer dereference (CWE-476) or dangling pointer (CWE-825), possibly crashing the system or causing heap corruption.
read of value at an offset into a structure after the offset is no longer valid
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Terminology
Many weaknesses related to pointer dereferences fall under the general term of "memory corruption" or "memory safety." As of September 2010, there is no commonly-used terminology that covers the lower-level variants.
Maintenance
There are close relationships between incorrect pointer dereferences and other weaknesses related to buffer operations. There may not be sufficient community agreement regarding these relationships. Further study is needed to determine when these relationships are chains, composites, perspective/layering, or other types of relationships. As of September 2010, most of the relationships are being captured as chains.
CWE-782: Exposed IOCTL with Insufficient Access Control
Weakness ID: 782
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product implements an IOCTL with functionality that should be restricted, but it does not properly enforce access control for the IOCTL.
Extended Description
When an IOCTL contains privileged functionality and is exposed unnecessarily, attackers may be able to access this functionality by invoking the IOCTL. Even if the functionality is benign, if the programmer has assumed that the IOCTL would only be accessed by a trusted process, there may be little or no validation of the incoming data, exposing weaknesses that would never be reachable if the attacker cannot call the IOCTL directly.
The implementations of IOCTLs will differ between operating system types and versions, so the methods of attack and prevention may vary widely.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Varies by Context
Scope: Integrity, Availability, Confidentiality
Attackers can invoke any functionality that the IOCTL offers. Depending on the functionality, the consequences may include code execution, denial-of-service, and theft of data.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
In Windows environments, use proper access control for the associated device or device namespace. See References.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Architecture and Design
Implementation
REALIZATION: This weakness is caused during implementation of an architectural security tactic.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Operating Systems
Class: Unix
(Undetermined Prevalence)
Class: Windows
(Undetermined Prevalence)
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Unauthorized user can disable keyboard or mouse by directly invoking a privileged IOCTL.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
This can be primary to many other weaknesses when the programmer assumes that the IOCTL can only be accessed by trusted parties. For example, a program or driver might not validate incoming addresses in METHOD_NEITHER IOCTLs in Windows environments (CWE-781), which could allow buffer overflow and similar attacks to take place, even when the attacker never should have been able to access the IOCTL at all.
Applicable Platform
Because IOCTL functionality is typically performing low-level actions and closely interacts with the operating system, this weakness may only appear in code that is written in low-level languages.
CWE-403: Exposure of File Descriptor to Unintended Control Sphere ('File Descriptor Leak')
Weakness ID: 403
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
A process does not close sensitive file descriptors before invoking a child process, which allows the child to perform unauthorized I/O operations using those descriptors.
Extended Description
When a new process is forked or executed, the child process inherits any open file descriptors. When the child process has fewer privileges than the parent process, this might introduce a vulnerability if the child process can access the file descriptor but does not have the privileges to access the associated file.
Alternate Terms
File descriptor leak
While this issue is frequently called a file descriptor leak, the "leak" term is often used in two different ways - exposure of a resource, or consumption of a resource. Use of this term could cause confusion.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Application Data; Modify Application Data
Scope: Confidentiality, Integrity
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
REALIZATION: This weakness is caused during implementation of an architectural security tactic.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
Class: Not Language-Specific
(Undetermined Prevalence)
Operating Systems
Class: Unix
(Undetermined Prevalence)
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Module opens a file for reading twice, allowing attackers to read files.
Affected Resources
System Process
File or Directory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
UNIX file descriptor leak
CERT C Secure Coding
FIO42-C
Ensure files are properly closed when they are no longer needed
CWE-685: Function Call With Incorrect Number of Arguments
Weakness ID: 685
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product calls a function, procedure, or routine, but the caller specifies too many arguments, or too few arguments, which may lead to undefined behavior and resultant weaknesses.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Quality Degradation
Scope: Other
Potential Mitigations
Phase(s)
Mitigation
Testing
Because this function call often produces incorrect behavior it will usually be detected during testing or normal operation of the product. During testing exercise all possible control paths will typically expose this weakness except in rare cases when the incorrect function call accidentally produces the correct results or if the provided argument type is very similar to the expected argument type.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Function Call with Incorrectly Specified Arguments
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
This problem typically occurs when the programmer makes a typo, or copy and paste errors.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
Perl
(Undetermined Prevalence)
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Other
While this weakness might be caught by the compiler in some languages, it can occur more frequently in cases in which the called function accepts variable numbers of arguments, such as format strings in C. It also can occur in languages or environments that do not require that functions always be called with the correct number of arguments, such as Perl.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
Software Fault Patterns
SFP1
Glitch in computation
CERT C Secure Coding
EXP37-C
CWE More Specific
Call functions with the correct number and type of arguments
CWE-688: Function Call With Incorrect Variable or Reference as Argument
Weakness ID: 688
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product calls a function, procedure, or routine, but the caller specifies the wrong variable or reference as one of the arguments, which may lead to undefined behavior and resultant weaknesses.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Quality Degradation
Scope: Other
Potential Mitigations
Phase(s)
Mitigation
Testing
Because this function call often produces incorrect behavior it will usually be detected during testing or normal operation of the product. During testing exercise all possible control paths will typically expose this weakness except in rare cases when the incorrect function call accidentally produces the correct results or if the provided argument type is very similar to the expected argument type.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Function Call with Incorrectly Specified Arguments
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
This problem typically occurs when the programmer makes a typo, or copy and paste errors.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
Perl
(Undetermined Prevalence)
Demonstrative Examples
Example 1
In the following Java snippet, the accessGranted() method is accidentally called with the static ADMIN_ROLES array rather than the user roles.
(bad code)
Example Language: Java
private static final String[] ADMIN_ROLES = ...; public boolean void accessGranted(String resource, String user) {
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Kernel code specifies the wrong variable in first argument, leading to resultant NULL pointer dereference.
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Other
While this weakness might be caught by the compiler in some languages, it can occur more frequently in cases in which the called function accepts variable numbers of arguments, such as format strings in C. It also can occur in loosely typed languages or environments. This might require an understanding of intended program behavior or design to determine whether the value is incorrect.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
A heap overflow condition is a buffer overflow, where the buffer that can be overwritten is allocated in the heap portion of memory, generally meaning that the buffer was allocated using a routine such as malloc().
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Buffer overflows generally lead to crashes. Other attacks leading to lack of availability are possible, including putting the program into an infinite loop.
Execute Unauthorized Code or Commands; Bypass Protection Mechanism; Modify Memory
Scope: Integrity, Confidentiality, Availability, Access Control
Buffer overflows often can be used to execute arbitrary code, which is usually outside the scope of a program's implicit security policy. Besides important user data, heap-based overflows can be used to overwrite function pointers that may be living in memory, pointing it to the attacker's code. Even in applications that do not explicitly use function pointers, the run-time will usually leave many in memory. For example, object methods in C++ are generally implemented using function pointers. Even in C programs, there is often a global offset table used by the underlying runtime.
Execute Unauthorized Code or Commands; Bypass Protection Mechanism; Other
Scope: Integrity, Confidentiality, Availability, Access Control, Other
When the consequence is arbitrary code execution, this can often be used to subvert any other security service.
Potential Mitigations
Phase(s)
Mitigation
Pre-design: Use a language or compiler that performs automatic bounds checking.
Architecture and Design
Use an abstraction library to abstract away risky APIs. Not a complete solution.
Operation; Build and Compilation
Strategy: Environment Hardening
Use automatic buffer overflow detection mechanisms that are offered by certain compilers or compiler extensions. Examples include: the Microsoft Visual Studio /GS flag, Fedora/Red Hat FORTIFY_SOURCE GCC flag, StackGuard, and ProPolice, which provide various mechanisms including canary-based detection and range/index checking.
D3-SFCV (Stack Frame Canary Validation) from D3FEND [REF-1334] discusses canary-based detection in detail.
Effectiveness: Defense in Depth
Note:
This is not necessarily a complete solution, since these mechanisms only detect certain types of overflows. In addition, the result is still a denial of service, since the typical response is to exit the application.
Operation; Build and Compilation
Strategy: Environment Hardening
Run or compile the software using features or extensions that randomly arrange the positions of a program's executable and libraries in memory. Because this makes the addresses unpredictable, it can prevent an attacker from reliably jumping to exploitable code.
Examples include Address Space Layout Randomization (ASLR) [REF-58] [REF-60] and Position-Independent Executables (PIE) [REF-64]. Imported modules may be similarly realigned if their default memory addresses conflict with other modules, in a process known as "rebasing" (for Windows) and "prelinking" (for Linux) [REF-1332] using randomly generated addresses. ASLR for libraries cannot be used in conjunction with prelink since it would require relocating the libraries at run-time, defeating the whole purpose of prelinking.
For more information on these techniques see D3-SAOR (Segment Address Offset Randomization) from D3FEND [REF-1335].
Effectiveness: Defense in Depth
Note: These techniques do not provide a complete solution. For instance, exploits frequently use a bug that discloses memory addresses in order to maximize reliability of code execution [REF-1337]. It has also been shown that a side-channel attack can bypass ASLR [REF-1333]
Implementation
Implement and perform bounds checking on input.
Implementation
Strategy: Libraries or Frameworks
Do not use dangerous functions such as gets. Look for their safe equivalent, which checks for the boundary.
Operation
Use OS-level preventative functionality. This is not a complete solution, but it provides some defense in depth.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
While buffer overflow examples can be rather complex, it is possible to have very simple, yet still exploitable, heap-based buffer overflows:
(bad code)
Example Language: C
#define BUFSIZE 256 int main(int argc, char **argv) {
The buffer is allocated heap memory with a fixed size, but there is no guarantee the string in argv[1] will not exceed this size and cause an overflow.
Example 2
This example applies an encoding procedure to an input string and stores it into a buffer.
(bad code)
Example Language: C
char * copy_input(char *user_supplied_string){
int i, dst_index; char *dst_buf = (char*)malloc(4*sizeof(char) * MAX_SIZE); if ( MAX_SIZE <= strlen(user_supplied_string) ){
die("user string too long, die evil hacker!");
} dst_index = 0; for ( i = 0; i < strlen(user_supplied_string); i++ ){
The programmer attempts to encode the ampersand character in the user-controlled string, however the length of the string is validated before the encoding procedure is applied. Furthermore, the programmer assumes encoding expansion will only expand a given character by a factor of 4, while the encoding of the ampersand expands by 5. As a result, when the encoding procedure expands the string it is possible to overflow the destination buffer if the attacker provides a string of many ampersands.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: in a web browser, an unsigned 64-bit integer is forcibly cast to a 32-bit integer (CWE-681) and potentially leading to an integer overflow (CWE-190). If an integer overflow occurs, this can cause heap memory corruption (CWE-122)
Chain: product does not handle when an input string is not NULL terminated (CWE-170), leading to buffer over-read (CWE-125) or heap-based buffer overflow (CWE-122).
Chain: machine-learning product can have a heap-based
buffer overflow (CWE-122) when some integer-oriented bounds are
calculated by using ceiling() and floor() on floating point values
(CWE-1339)
Chain: integer overflow (CWE-190) causes a negative signed value, which later bypasses a maximum-only check (CWE-839), leading to heap-based buffer overflow (CWE-122).
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
Heap-based buffer overflows are usually just as dangerous as stack-based buffer overflows.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Heap overflow
Software Fault Patterns
SFP8
Faulty Buffer Access
CERT C Secure Coding
STR31-C
CWE More Specific
Guarantee that storage for strings has sufficient space for character data and the null terminator
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 5: Buffer Overruns." Page 89. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 3, "Nonexecutable Stack", Page 76. 1st Edition. Addison Wesley. 2006.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 5, "Protection Mechanisms", Page 189. 1st Edition. Addison Wesley. 2006.
CWE-781: Improper Address Validation in IOCTL with METHOD_NEITHER I/O Control Code
Weakness ID: 781
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product defines an IOCTL that uses METHOD_NEITHER for I/O, but it does not validate or incorrectly validates the addresses that are provided.
Extended Description
When an IOCTL uses the METHOD_NEITHER option for I/O control, it is the responsibility of the IOCTL to validate the addresses that have been supplied to it. If validation is missing or incorrect, attackers can supply arbitrary memory addresses, leading to code execution or a denial of service.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; Read Memory; Execute Unauthorized Code or Commands; DoS: Crash, Exit, or Restart
Scope: Integrity, Availability, Confidentiality
An attacker may be able to access memory that belongs to another process or user. If the attacker can control the contents that the IOCTL writes, it may lead to code execution at high privilege levels. At the least, a crash can occur.
Potential Mitigations
Phase(s)
Mitigation
Implementation
If METHOD_NEITHER is required for the IOCTL, then ensure that all user-space addresses are properly validated before they are first accessed. The ProbeForRead and ProbeForWrite routines are available for this task. Also properly protect and manage the user-supplied buffers, since the I/O Manager does not do this when METHOD_NEITHER is being used. See References.
Architecture and Design
If possible, avoid using METHOD_NEITHER in the IOCTL and select methods that effectively control the buffer size, such as METHOD_BUFFERED, METHOD_IN_DIRECT, or METHOD_OUT_DIRECT.
Architecture and Design; Implementation
If the IOCTL is part of a driver that is only intended to be accessed by trusted users, then use proper access control for the associated device or device namespace. See References.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Improper Validation of Specified Index, Position, or Offset in Input
CanFollow
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Operating Systems
Windows NT
(Sometimes Prevalent)
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
chain: device driver for packet-capturing software allows access to an unintended IOCTL with resultant array index error.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Applicable Platform
Because IOCTL functionality is typically performing low-level actions and closely interacts with the operating system, this weakness may only appear in code that is written in low-level languages.
Research Gap
While this type of issue has been known since 2006, it is probably still under-studied and under-reported. Most of the focus has been on high-profile software and security products, but other kinds of system software also use drivers. Since exploitation requires the development of custom code, it requires some skill to find this weakness.
Because exploitation typically requires local privileges, it might not be a priority for active attackers. However, remote exploitation may be possible for software such as device drivers. Even when remote vectors are not available, it may be useful as the final privilege-escalation step in multi-stage remote attacks against application-layer software, or as the primary attack by a local user on a multi-user system.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product does not clean up its state or incorrectly cleans up its state when an exception is thrown, leading to unexpected state or control flow.
Extended Description
Often, when functions or loops become complicated, some level of resource cleanup is needed throughout execution. Exceptions can disturb the flow of the code and prevent the necessary cleanup from happening.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Varies by Context
Scope: Other
The code could be left in a bad state.
Potential Mitigations
Phase(s)
Mitigation
Implementation
If one breaks from a loop or function by throwing an exception, make sure that cleanup happens or that you should exit the program. Use throwing exceptions sparsely.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
REALIZATION: This weakness is caused during implementation of an architectural security tactic.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
threadLock=true; //do some stuff to truthvalue threadLock=false;
}
} catch (Exception e){
System.err.println("You did something bad"); if (something) return truthvalue;
} return truthvalue;
}
}
In this case, a thread might be left locked accidentally.
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Improper cleanup on thrown exception
The CERT Oracle Secure Coding Standard for Java (2011)
ERR03-J
Restore prior object state on method failure
The CERT Oracle Secure Coding Standard for Java (2011)
ERR05-J
Do not let checked exceptions escape from a finally block
CWE-244: Improper Clearing of Heap Memory Before Release ('Heap Inspection')
Weakness ID: 244
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
Using realloc() to resize buffers that store sensitive information can leave the sensitive information exposed to attack, because it is not removed from memory.
Extended Description
When sensitive data such as a password or an encryption key is not removed from memory, it could be exposed to an attacker using a "heap inspection" attack that reads the sensitive data using memory dumps or other methods. The realloc() function is commonly used to increase the size of a block of allocated memory. This operation often requires copying the contents of the old memory block into a new and larger block. This operation leaves the contents of the original block intact but inaccessible to the program, preventing the program from being able to scrub sensitive data from memory. If an attacker can later examine the contents of a memory dump, the sensitive data could be exposed.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory; Other
Scope: Confidentiality, Other
Be careful using vfork() and fork() in security sensitive code. The process state will not be cleaned up and will contain traces of data from past use.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Sensitive Information in Resource Not Removed Before Reuse
CanPrecede
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The following code calls realloc() on a buffer containing sensitive data:
There is an attempt to scrub the sensitive data from memory, but realloc() is used, so it could return a pointer to a different part of memory. The memory that was originally allocated for cleartext_buffer could still contain an uncleared copy of the data.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Cryptography library does not clear heap memory before release
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 08 - Memory Management (MEM)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
7 Pernicious Kingdoms
Heap Inspection
CERT C Secure Coding
MEM03-C
Clear sensitive information stored in reusable resources returned for reuse
CWE-130: Improper Handling of Length Parameter Inconsistency
Weakness ID: 130
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product parses a formatted message or structure, but it does not handle or incorrectly handles a length field that is inconsistent with the actual length of the associated data.
Extended Description
If an attacker can manipulate the length parameter associated with an input such that it is inconsistent with the actual length of the input, this can be leveraged to cause the target application to behave in unexpected, and possibly, malicious ways. One of the possible motives for doing so is to pass in arbitrarily large input to the application. Another possible motivation is the modification of application state by including invalid data for subsequent properties of the application. Such weaknesses commonly lead to attacks such as buffer overflows and execution of arbitrary code.
Alternate Terms
length manipulation
length tampering
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory; Modify Memory; Varies by Context
Scope: Confidentiality, Integrity
Potential Mitigations
Phase(s)
Mitigation
Implementation
When processing structured incoming data containing a size field followed by raw data, ensure that you identify and resolve any inconsistencies between the size field and the actual size of the data.
Implementation
Do not let the user control the size of the buffer.
Implementation
Validate that the length of the user-supplied data is consistent with the buffer size.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Improper Handling of Inconsistent Structural Elements
CanPrecede
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Sometimes Prevalent)
C++
(Sometimes Prevalent)
Class: Not Language-Specific
(Undetermined Prevalence)
Demonstrative Examples
Example 1
In the following C/C++ example the method processMessageFromSocket() will get a message from a socket, placed into a buffer, and will parse the contents of the buffer into a structure that contains the message length and the message body. A for loop is used to copy the message body into a local character string which will be passed to another method for processing.
//Ignoring possibliity that buffer > BUFFER_SIZE if (getMessage(socket, buffer, BUFFER_SIZE) > 0) {
// place contents of the buffer into message structure ExMessage *msg = recastBuffer(buffer);
// copy message body into string for processing int index; for (index = 0; index < msg->msgLength; index++) {
message[index] = msg->msgBody[index];
} message[index] = '\0';
// process message success = processMessage(message);
} return success;
}
However, the message length variable from the structure is used as the condition for ending the for loop without validating that the message length variable accurately reflects the length of the message body (CWE-606). This can result in a buffer over-read (CWE-125) by reading from memory beyond the bounds of the buffer if the message length variable indicates a length that is longer than the size of a message body (CWE-130).
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: "Heartbleed" bug receives an inconsistent length parameter (CWE-130) enabling an out-of-bounds read (CWE-126), returning memory that could include private cryptographic keys and other sensitive data.
Buffer overflow in internal string handling routine allows remote attackers to execute arbitrary commands via a length argument of zero or less, which disables the length check.
Web server allows remote attackers to cause a denial of service via an HTTP request with a content-length value that is larger than the size of the request, which prevents server from timing out the connection.
Service does not properly check the specified length of a cookie, which allows remote attackers to execute arbitrary commands via a buffer overflow, or brute force authentication by using a short cookie length.
Traffic analyzer allows remote attackers to cause a denial of service and possibly execute arbitrary code via invalid IPv4 or IPv6 prefix lengths, possibly triggering a buffer overflow.
Chat client allows remote attackers to cause a denial of service or execute arbitrary commands via a JPEG image containing a comment with an illegal field length of 1.
Server allows remote attackers to cause a denial of service and possibly execute arbitrary code via a negative Content-Length HTTP header field causing a heap-based buffer overflow.
Name services does not properly validate the length of certain packets, which allows attackers to cause a denial of service and possibly execute arbitrary code. Can overlap zero-length issues
Policy manager allows remote attackers to cause a denial of service (memory consumption and crash) and possibly execute arbitrary code via an HTTP POST request with an invalid Content-Length value.
Heap-based buffer overflow in library allows remote attackers to execute arbitrary code via a modified record length field in an SSLv2 client hello message.
When domain logons are enabled, server allows remote attackers to cause a denial of service via a SAM_UAS_CHANGE request with a length value that is larger than the number of structures that are provided.
Multiple SSH2 servers and clients do not properly handle packets or data elements with incorrect length specifiers, which may allow remote attackers to cause a denial of service or possibly execute arbitrary code.
Application does not properly validate the length of a value that is saved in a session file, which allows remote attackers to execute arbitrary code via a malicious session file (.ht), web site, or Telnet URL contained in an e-mail message, triggering a buffer overflow.
Server allows remote attackers to cause a denial of service via a remote password array with an invalid length, which triggers a heap-based buffer overflow.
Product allows remote attackers to cause a denial of service and possibly execute arbitrary code via an SMB packet that specifies a smaller buffer length than is required.
Server allows remote attackers to execute arbitrary code via a LoginExt packet for a Cleartext Password User Authentication Method (UAM) request with a PathName argument that includes an AFPName type string that is longer than the associated length field.
SVN client trusts the length field of SVN protocol URL strings, which allows remote attackers to cause a denial of service and possibly execute arbitrary code via an integer overflow that leads to a heap-based buffer overflow.
(where the weakness exists independent of other weaknesses)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
This probably overlaps other categories including zero-length issues.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product does not terminate or incorrectly terminates a string or array with a null character or equivalent terminator.
Extended Description
Null termination errors frequently occur in two different ways. An off-by-one error could cause a null to be written out of bounds, leading to an overflow. Or, a program could use a strncpy() function call incorrectly, which prevents a null terminator from being added at all. Other scenarios are possible.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory; Execute Unauthorized Code or Commands
Scope: Confidentiality, Integrity, Availability
The case of an omitted null character is the most dangerous of the possible issues. This will almost certainly result in information disclosure, and possibly a buffer overflow condition, which may be exploited to execute arbitrary code.
If a null character is omitted from a string, then most string-copying functions will read data until they locate a null character, even outside of the intended boundaries of the string. This could: cause a crash due to a segmentation fault cause sensitive adjacent memory to be copied and sent to an outsider trigger a buffer overflow when the copy is being written to a fixed-size buffer.
Modify Memory; DoS: Crash, Exit, or Restart
Scope: Integrity, Availability
Misplaced null characters may result in any number of security problems. The biggest issue is a subset of buffer overflow, and write-what-where conditions, where data corruption occurs from the writing of a null character over valid data, or even instructions. A randomly placed null character may put the system into an undefined state, and therefore make it prone to crashing. A misplaced null character may corrupt other data in memory.
Alter Execution Logic; Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability, Access Control, Other
Should the null character corrupt the process flow, or affect a flag controlling access, it may lead to logical errors which allow for the execution of arbitrary code.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Use a language that is not susceptible to these issues. However, be careful of null byte interaction errors (CWE-626) with lower-level constructs that may be written in a language that is susceptible.
Implementation
Ensure that all string functions used are understood fully as to how they append null characters. Also, be wary of off-by-one errors when appending nulls to the end of strings.
Implementation
If performance constraints permit, special code can be added that validates null-termination of string buffers, this is a rather naive and error-prone solution.
Implementation
Switch to bounded string manipulation functions. Inspect buffer lengths involved in the buffer overrun trace reported with the defect.
Implementation
Add code that fills buffers with nulls (however, the length of buffers still needs to be inspected, to ensure that the non null-terminated string is not written at the physical end of the buffer).
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
CanPrecede
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Seven Pernicious Kingdoms" (View-700)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
The following code reads from cfgfile and copies the input into inputbuf using strcpy(). The code mistakenly assumes that inputbuf will always contain a NULL terminator.
The code above will behave correctly if the data read from cfgfile is null terminated on disk as expected. But if an attacker is able to modify this input so that it does not contain the expected NULL character, the call to strcpy() will continue copying from memory until it encounters an arbitrary NULL character. This will likely overflow the destination buffer and, if the attacker can control the contents of memory immediately following inputbuf, can leave the application susceptible to a buffer overflow attack.
Example 2
In the following code, readlink() expands the name of a symbolic link stored in pathname and puts the absolute path into buf. The length of the resulting value is then calculated using strlen().
The code above will not always behave correctly as readlink() does not append a NULL byte to buf. Readlink() will stop copying characters once the maximum size of buf has been reached to avoid overflowing the buffer, this will leave the value buf not NULL terminated. In this situation, strlen() will continue traversing memory until it encounters an arbitrary NULL character further on down the stack, resulting in a length value that is much larger than the size of string. Readlink() does return the number of bytes copied, but when this return value is the same as stated buf size (in this case MAXPATH), it is impossible to know whether the pathname is precisely that many bytes long, or whether readlink() has truncated the name to avoid overrunning the buffer. In testing, vulnerabilities like this one might not be caught because the unused contents of buf and the memory immediately following it may be NULL, thereby causing strlen() to appear as if it is behaving correctly.
Example 3
While the following example is not exploitable, it provides a good example of how nulls can be omitted or misplaced, even when "safe" functions are used:
strncpy(shortString, longString, 16); printf("The last character in shortString is: %c (%1$x)\n", shortString[15]); return (0);
}
The above code gives the following output: "The last character in shortString is: n (6e)". So, the shortString array does not end in a NULL character, even though the "safe" string function strncpy() was used. The reason is that strncpy() does not impliciitly add a NULL character at the end of the string when the source is equal in length or longer than the provided size.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: product does not handle when an input string is not NULL terminated (CWE-170), leading to buffer over-read (CWE-125) or heap-based buffer overflow (CWE-122).
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 07 - Characters and Strings (STR)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
Factors: this is usually resultant from other weaknesses such as off-by-one errors, but it can be primary to boundary condition violations such as buffer overflows. In buffer overflows, it can act as an expander for assumed-immutable data.
Relationship
Overlaps missing input terminator.
Applicable Platform
Conceptually, this does not just apply to the C language; any language or representation that involves a terminator could have this type of problem.
Maintenance
As currently described, this entry is more like a category than a weakness.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Improper Null Termination
7 Pernicious Kingdoms
String Termination Error
CLASP
Miscalculated null termination
OWASP Top Ten 2004
A9
CWE More Specific
Denial of Service
CERT C Secure Coding
POS30-C
CWE More Abstract
Use the readlink() function properly
CERT C Secure Coding
STR03-C
Do not inadvertently truncate a null-terminated byte string
CERT C Secure Coding
STR32-C
Exact
Do not pass a non-null-terminated character sequence to a library function that expects a string
CWE-119: Improper Restriction of Operations within the Bounds of a Memory Buffer
Weakness ID: 119
Vulnerability Mapping:DISCOURAGEDThis CWE ID should not be used to map to real-world vulnerabilities Abstraction:
ClassClass - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product performs operations on a memory buffer, but it reads from or writes to a memory location outside the buffer's intended boundary. This may result in read or write operations on unexpected memory locations that could be linked to other variables, data structures, or internal program data.
Alternate Terms
Buffer Overflow
This term has many different meanings to different audiences. From a CWE mapping perspective, this term should be avoided where possible. Some researchers, developers, and tools intend for it to mean "write past the end of a buffer," whereas others use the same term to mean "any read or write outside the boundaries of a buffer, whether before the beginning of the buffer or after the end of the buffer." Others could mean "any action after the end of a buffer, whether it is a read or write." Since the term is commonly used for exploitation and for vulnerabilities, it further confuses things.
buffer overrun
Some prominent vendors and researchers use the term "buffer overrun," but most people use "buffer overflow." See the alternate term for "buffer overflow" for context.
memory safety
Generally used for techniques that avoid weaknesses related to memory access, such as those identified by CWE-119 and its descendants. However, the term is not formal, and there is likely disagreement between practitioners as to which weaknesses are implicitly covered by the "memory safety" term.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Execute Unauthorized Code or Commands; Modify Memory
Scope: Integrity, Confidentiality, Availability
If the memory accessible by the attacker can be effectively controlled, it may be possible to execute arbitrary code, as with a standard buffer overflow. If the attacker can overwrite a pointer's worth of memory (usually 32 or 64 bits), they can alter the intended control flow by redirecting a function pointer to their own malicious code. Even when the attacker can only modify a single byte arbitrary code execution can be possible. Sometimes this is because the same problem can be exploited repeatedly to the same effect. Other times it is because the attacker can overwrite security-critical application-specific data -- such as a flag indicating whether the user is an administrator.
Out of bounds memory access will very likely result in the corruption of relevant memory, and perhaps instructions, possibly leading to a crash. Other attacks leading to lack of availability are possible, including putting the program into an infinite loop.
Read Memory
Scope: Confidentiality
In the case of an out-of-bounds read, the attacker may have access to sensitive information. If the sensitive information contains system details, such as the current buffer's position in memory, this knowledge can be used to craft further attacks, possibly with more severe consequences.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Strategy: Language Selection
Use a language that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
For example, many languages that perform their own memory management, such as Java and Perl, are not subject to buffer overflows. Other languages, such as Ada and C#, typically provide overflow protection, but the protection can be disabled by the programmer.
Be wary that a language's interface to native code may still be subject to overflows, even if the language itself is theoretically safe.
Architecture and Design
Strategy: Libraries or Frameworks
Use a vetted library or framework that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
Examples include the Safe C String Library (SafeStr) by Messier and Viega [REF-57], and the Strsafe.h library from Microsoft [REF-56]. These libraries provide safer versions of overflow-prone string-handling functions.
Note: This is not a complete solution, since many buffer overflows are not related to strings.
Operation; Build and Compilation
Strategy: Environment Hardening
Use automatic buffer overflow detection mechanisms that are offered by certain compilers or compiler extensions. Examples include: the Microsoft Visual Studio /GS flag, Fedora/Red Hat FORTIFY_SOURCE GCC flag, StackGuard, and ProPolice, which provide various mechanisms including canary-based detection and range/index checking.
D3-SFCV (Stack Frame Canary Validation) from D3FEND [REF-1334] discusses canary-based detection in detail.
Effectiveness: Defense in Depth
Note:
This is not necessarily a complete solution, since these mechanisms only detect certain types of overflows. In addition, the result is still a denial of service, since the typical response is to exit the application.
Implementation
Consider adhering to the following rules when allocating and managing an application's memory:
Double check that the buffer is as large as specified.
When using functions that accept a number of bytes to copy, such as strncpy(), be aware that if the destination buffer size is equal to the source buffer size, it may not NULL-terminate the string.
Check buffer boundaries if accessing the buffer in a loop and make sure there is no danger of writing past the allocated space.
If necessary, truncate all input strings to a reasonable length before passing them to the copy and concatenation functions.
Operation; Build and Compilation
Strategy: Environment Hardening
Run or compile the software using features or extensions that randomly arrange the positions of a program's executable and libraries in memory. Because this makes the addresses unpredictable, it can prevent an attacker from reliably jumping to exploitable code.
Examples include Address Space Layout Randomization (ASLR) [REF-58] [REF-60] and Position-Independent Executables (PIE) [REF-64]. Imported modules may be similarly realigned if their default memory addresses conflict with other modules, in a process known as "rebasing" (for Windows) and "prelinking" (for Linux) [REF-1332] using randomly generated addresses. ASLR for libraries cannot be used in conjunction with prelink since it would require relocating the libraries at run-time, defeating the whole purpose of prelinking.
For more information on these techniques see D3-SAOR (Segment Address Offset Randomization) from D3FEND [REF-1335].
Effectiveness: Defense in Depth
Note: These techniques do not provide a complete solution. For instance, exploits frequently use a bug that discloses memory addresses in order to maximize reliability of code execution [REF-1337]. It has also been shown that a side-channel attack can bypass ASLR [REF-1333]
Operation
Strategy: Environment Hardening
Use a CPU and operating system that offers Data Execution Protection (using hardware NX or XD bits) or the equivalent techniques that simulate this feature in software, such as PaX [REF-60] [REF-61]. These techniques ensure that any instruction executed is exclusively at a memory address that is part of the code segment.
For more information on these techniques see D3-PSEP (Process Segment Execution Prevention) from D3FEND [REF-1336].
Effectiveness: Defense in Depth
Note: This is not a complete solution, since buffer overflows could be used to overwrite nearby variables to modify the software's state in dangerous ways. In addition, it cannot be used in cases in which self-modifying code is required. Finally, an attack could still cause a denial of service, since the typical response is to exit the application.
Implementation
Replace unbounded copy functions with analogous functions that support length arguments, such as strcpy with strncpy. Create these if they are not available.
Effectiveness: Moderate
Note: This approach is still susceptible to calculation errors, including issues such as off-by-one errors (CWE-193) and incorrectly calculating buffer lengths (CWE-131).
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Incorrect Access of Indexable Resource ('Range Error')
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Access of Resource Using Incompatible Type ('Type Confusion')
CanFollow
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Improper Access Control Applied to Mirrored or Aliased Memory Regions
CanFollow
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Improper Handling of Overlap Between Protected Memory Ranges
CanFollow
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Insufficient Precision or Accuracy of a Real Number
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses for Simplified Mapping of Published Vulnerabilities
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Improper Handling of Length Parameter Inconsistency
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Improper Handling of Length Parameter Inconsistency
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Seven Pernicious Kingdoms" (View-700)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Certain languages allow direct addressing of memory locations and do not automatically ensure that these locations are valid for the memory buffer that is being referenced.
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Class: Assembly
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
This example takes an IP address from a user, verifies that it is well formed and then looks up the hostname and copies it into a buffer.
This function allocates a buffer of 64 bytes to store the hostname, however there is no guarantee that the hostname will not be larger than 64 bytes. If an attacker specifies an address which resolves to a very large hostname, then the function may overwrite sensitive data or even relinquish control flow to the attacker.
Note that this example also contains an unchecked return value (CWE-252) that can lead to a NULL pointer dereference (CWE-476).
Example 2
This example applies an encoding procedure to an input string and stores it into a buffer.
(bad code)
Example Language: C
char * copy_input(char *user_supplied_string){
int i, dst_index; char *dst_buf = (char*)malloc(4*sizeof(char) * MAX_SIZE); if ( MAX_SIZE <= strlen(user_supplied_string) ){
die("user string too long, die evil hacker!");
} dst_index = 0; for ( i = 0; i < strlen(user_supplied_string); i++ ){
The programmer attempts to encode the ampersand character in the user-controlled string, however the length of the string is validated before the encoding procedure is applied. Furthermore, the programmer assumes encoding expansion will only expand a given character by a factor of 4, while the encoding of the ampersand expands by 5. As a result, when the encoding procedure expands the string it is possible to overflow the destination buffer if the attacker provides a string of many ampersands.
Example 3
The following example asks a user for an offset into an array to select an item.
(bad code)
Example Language: C
int main (int argc, char **argv) {
char *items[] = {"boat", "car", "truck", "train"}; int index = GetUntrustedOffset(); printf("You selected %s\n", items[index-1]);
}
The programmer allows the user to specify which element in the list to select, however an attacker can provide an out-of-bounds offset, resulting in a buffer over-read (CWE-126).
Example 4
In the following code, the method retrieves a value from an array at a specific array index location that is given as an input parameter to the method
(bad code)
Example Language: C
int getValueFromArray(int *array, int len, int index) {
int value;
// check that the array index is less than the maximum
// length of the array if (index < len) {
// get the value at the specified index of the array value = array[index];
} // if array index is invalid then output error message // and return value indicating error else {
printf("Value is: %d\n", array[index]); value = -1;
}
return value;
}
However, this method only verifies that the given array index is less than the maximum length of the array but does not check for the minimum value (CWE-839). This will allow a negative value to be accepted as the input array index, which will result in a out of bounds read (CWE-125) and may allow access to sensitive memory. The input array index should be checked to verify that is within the maximum and minimum range required for the array (CWE-129). In this example the if statement should be modified to include a minimum range check, as shown below.
(good code)
Example Language: C
...
// check that the array index is within the correct
// range of values for the array if (index >= 0 && index < len) {
...
Example 5
Windows provides the _mbs family of functions to perform various operations on multibyte strings. When these functions are passed a malformed multibyte string, such as a string containing a valid leading byte followed by a single null byte, they can read or write past the end of the string buffer causing a buffer overflow. The following functions all pose a risk of buffer overflow: _mbsinc _mbsdec _mbsncat _mbsncpy _mbsnextc _mbsnset _mbsrev _mbsset _mbsstr _mbstok _mbccpy _mbslen
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: machine-learning product can have a heap-based
buffer overflow (CWE-122) when some integer-oriented bounds are
calculated by using ceiling() and floor() on floating point values
(CWE-1339)
Chain: integer overflow in securely-coded mail program leads to buffer overflow. In 2005, this was regarded as unrealistic to exploit, but in 2020, it was rediscovered to be easier to exploit due to evolutions of the technology.
chain: unchecked message size metadata allows integer overflow (CWE-190) leading to buffer overflow (CWE-119).
Detection
Methods
Method
Details
Automated Static Analysis
This weakness can often be detected using automated static analysis tools. Many modern tools use data flow analysis or constraint-based techniques to minimize the number of false positives.
Automated static analysis generally does not account for environmental considerations when reporting out-of-bounds memory operations. This can make it difficult for users to determine which warnings should be investigated first. For example, an analysis tool might report buffer overflows that originate from command line arguments in a program that is not expected to run with setuid or other special privileges.
Effectiveness: High
Note:Detection techniques for buffer-related errors are more mature than for most other weakness types.
Automated Dynamic Analysis
This weakness can be detected using dynamic tools and techniques that interact with the software using large test suites with many diverse inputs, such as fuzz testing (fuzzing), robustness testing, and fault injection. The software's operation may slow down, but it should not become unstable, crash, or generate incorrect results.
Automated Static Analysis - Binary or Bytecode
According to SOAR, the following detection techniques may be useful:
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
SEI CERT C Coding Standard - Guidelines 07. Characters and Strings (STR)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2021 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2020 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2023 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2024 CWE Top 25 Most Dangerous Software Weaknesses
Vulnerability Mapping Notes
Usage
DISCOURAGED
(this CWE ID should not be used to map to real-world vulnerabilities)
Reason
Frequent Misuse
Rationale
CWE-119 is commonly misused in low-information vulnerability reports when lower-level CWEs could be used instead, or when more details about the vulnerability are available.
Comments
Look at CWE-119's children and consider mapping to CWEs such as CWE-787: Out-of-bounds Write, CWE-125: Out-of-bounds Read, or others.
Notes
Applicable Platform
It is possible in any programming languages without memory management support to attempt an operation outside of the bounds of a memory buffer, but the consequences will vary widely depending on the language, platform, and chip architecture.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
OWASP Top Ten 2004
A5
Exact
Buffer Overflows
CERT C Secure Coding
ARR00-C
Understand how arrays work
CERT C Secure Coding
ARR30-C
CWE More Abstract
Do not form or use out-of-bounds pointers or array subscripts
CERT C Secure Coding
ARR38-C
CWE More Abstract
Guarantee that library functions do not form invalid pointers
CERT C Secure Coding
ENV01-C
Do not make assumptions about the size of an environment variable
CERT C Secure Coding
EXP39-C
Imprecise
Do not access a variable through a pointer of an incompatible type
CERT C Secure Coding
FIO37-C
Do not assume character data has been read
CERT C Secure Coding
STR31-C
CWE More Abstract
Guarantee that storage for strings has sufficient space for character data and the null terminator
CERT C Secure Coding
STR32-C
CWE More Abstract
Do not pass a non-null-terminated character sequence to a library function that expects a string
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 5, "Memory Corruption", Page 167. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses a reference count to manage a resource, but it does not update or incorrectly updates the reference count.
Extended Description
Reference counts can be used when tracking how many objects contain a reference to a particular resource, such as in memory management or garbage collection. When the reference count reaches zero, the resource can be de-allocated or reused because there are no more objects that use it. If the reference count accidentally reaches zero, then the resource might be released too soon, even though it is still in use. If all objects no longer use the resource, but the reference count is not zero, then the resource might not ever be released.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
An adversary that can cause a resource counter to become inaccurate may be able to create situations where resources are not accounted for and not released, thus causing resources to become scarce for future needs.
DoS: Crash, Exit, or Restart
Scope: AvailabilityLikelihood: Low
An adversary that can cause a resource counter to become inaccurate may be able to force an error that causes the product to crash or exit out of its current operation.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Improper Control of a Resource Through its Lifetime
CanPrecede
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Operation on a Resource after Expiration or Release
CanPrecede
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Sometimes Prevalent)
C++
(Sometimes Prevalent)
Class: Not Language-Specific
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
chain/composite: use of incorrect data type for a reference counter allows an overflow of the counter, leading to a free of memory that is still in use.
Race condition causes reference counter to be decremented prematurely, leading to the destruction of still-active object and an invalid pointer dereference.
improper reference counting leads to use-after-free
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses untrusted input when calculating or using an array index, but the product does not validate or incorrectly validates the index to ensure the index references a valid position within the array.
Alternate Terms
out-of-bounds array index
index-out-of-range
array index underflow
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
DoS: Crash, Exit, or Restart
Scope: Integrity, Availability
Use of an index that is outside the bounds of an array will very likely result in the corruption of relevant memory and perhaps instructions, leading to a crash, if the values are outside of the valid memory area.
Modify Memory
Scope: Integrity
If the memory corrupted is data, rather than instructions, the system will continue to function with improper values.
Modify Memory; Read Memory
Scope: Confidentiality, Integrity
Use of an index that is outside the bounds of an array can also trigger out-of-bounds read or write operations, or operations on the wrong objects; i.e., "buffer overflows" are not always the result. This may result in the exposure or modification of sensitive data.
Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
If the memory accessible by the attacker can be effectively controlled, it may be possible to execute arbitrary code, as with a standard buffer overflow and possibly without the use of large inputs if a precise index can be controlled.
DoS: Crash, Exit, or Restart; Execute Unauthorized Code or Commands; Read Memory; Modify Memory
Scope: Integrity, Availability, Confidentiality
A single fault could allow either an overflow (CWE-788) or underflow (CWE-786) of the array index. What happens next will depend on the type of operation being performed out of bounds, but can expose sensitive information, cause a system crash, or possibly lead to arbitrary code execution.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Strategy: Input Validation
Use an input validation framework such as Struts or the OWASP ESAPI Validation API. Note that using a framework does not automatically address all input validation problems; be mindful of weaknesses that could arise from misusing the framework itself (CWE-1173).
Architecture and Design
For any security checks that are performed on the client side, ensure that these checks are duplicated on the server side, in order to avoid CWE-602. Attackers can bypass the client-side checks by modifying values after the checks have been performed, or by changing the client to remove the client-side checks entirely. Then, these modified values would be submitted to the server.
Even though client-side checks provide minimal benefits with respect to server-side security, they are still useful. First, they can support intrusion detection. If the server receives input that should have been rejected by the client, then it may be an indication of an attack. Second, client-side error-checking can provide helpful feedback to the user about the expectations for valid input. Third, there may be a reduction in server-side processing time for accidental input errors, although this is typically a small savings.
Requirements
Strategy: Language Selection
Use a language that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
For example, Ada allows the programmer to constrain the values of a variable and languages such as Java and Ruby will allow the programmer to handle exceptions when an out-of-bounds index is accessed.
Operation; Build and Compilation
Strategy: Environment Hardening
Run or compile the software using features or extensions that randomly arrange the positions of a program's executable and libraries in memory. Because this makes the addresses unpredictable, it can prevent an attacker from reliably jumping to exploitable code.
Examples include Address Space Layout Randomization (ASLR) [REF-58] [REF-60] and Position-Independent Executables (PIE) [REF-64]. Imported modules may be similarly realigned if their default memory addresses conflict with other modules, in a process known as "rebasing" (for Windows) and "prelinking" (for Linux) [REF-1332] using randomly generated addresses. ASLR for libraries cannot be used in conjunction with prelink since it would require relocating the libraries at run-time, defeating the whole purpose of prelinking.
For more information on these techniques see D3-SAOR (Segment Address Offset Randomization) from D3FEND [REF-1335].
Effectiveness: Defense in Depth
Note: These techniques do not provide a complete solution. For instance, exploits frequently use a bug that discloses memory addresses in order to maximize reliability of code execution [REF-1337]. It has also been shown that a side-channel attack can bypass ASLR [REF-1333]
Operation
Strategy: Environment Hardening
Use a CPU and operating system that offers Data Execution Protection (using hardware NX or XD bits) or the equivalent techniques that simulate this feature in software, such as PaX [REF-60] [REF-61]. These techniques ensure that any instruction executed is exclusively at a memory address that is part of the code segment.
For more information on these techniques see D3-PSEP (Process Segment Execution Prevention) from D3FEND [REF-1336].
Effectiveness: Defense in Depth
Note: This is not a complete solution, since buffer overflows could be used to overwrite nearby variables to modify the software's state in dangerous ways. In addition, it cannot be used in cases in which self-modifying code is required. Finally, an attack could still cause a denial of service, since the typical response is to exit the application.
Implementation
Strategy: Input Validation
Assume all input is malicious. Use an "accept known good" input validation strategy, i.e., use a list of acceptable inputs that strictly conform to specifications. Reject any input that does not strictly conform to specifications, or transform it into something that does.
When performing input validation, consider all potentially relevant properties, including length, type of input, the full range of acceptable values, missing or extra inputs, syntax, consistency across related fields, and conformance to business rules. As an example of business rule logic, "boat" may be syntactically valid because it only contains alphanumeric characters, but it is not valid if the input is only expected to contain colors such as "red" or "blue."
Do not rely exclusively on looking for malicious or malformed inputs. This is likely to miss at least one undesirable input, especially if the code's environment changes. This can give attackers enough room to bypass the intended validation. However, denylists can be useful for detecting potential attacks or determining which inputs are so malformed that they should be rejected outright.
When accessing a user-controlled array index, use a stringent range of values that are within the target array. Make sure that you do not allow negative values to be used. That is, verify the minimum as well as the maximum of the range of acceptable values.
Implementation
Be especially careful to validate all input when invoking code that crosses language boundaries, such as from an interpreted language to native code. This could create an unexpected interaction between the language boundaries. Ensure that you are not violating any of the expectations of the language with which you are interfacing. For example, even though Java may not be susceptible to buffer overflows, providing a large argument in a call to native code might trigger an overflow.
Architecture and Design; Operation
Strategy: Environment Hardening
Run your code using the lowest privileges that are required to accomplish the necessary tasks [REF-76]. If possible, create isolated accounts with limited privileges that are only used for a single task. That way, a successful attack will not immediately give the attacker access to the rest of the software or its environment. For example, database applications rarely need to run as the database administrator, especially in day-to-day operations.
Architecture and Design; Operation
Strategy: Sandbox or Jail
Run the code in a "jail" or similar sandbox environment that enforces strict boundaries between the process and the operating system. This may effectively restrict which files can be accessed in a particular directory or which commands can be executed by the software.
OS-level examples include the Unix chroot jail, AppArmor, and SELinux. In general, managed code may provide some protection. For example, java.io.FilePermission in the Java SecurityManager allows the software to specify restrictions on file operations.
This may not be a feasible solution, and it only limits the impact to the operating system; the rest of the application may still be subject to compromise.
Be careful to avoid CWE-243 and other weaknesses related to jails.
Effectiveness: Limited
Note: The effectiveness of this mitigation depends on the prevention capabilities of the specific sandbox or jail being used and might only help to reduce the scope of an attack, such as restricting the attacker to certain system calls or limiting the portion of the file system that can be accessed.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Improper Validation of Specified Index, Position, or Offset in Input
CanPrecede
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
CanPrecede
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Class: Not Language-Specific
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
In the code snippet below, an untrusted integer value is used to reference an object in an array.
(bad code)
Example Language: Java
public String getValue(int index) {
return array[index];
}
If index is outside of the range of the array, this may result in an ArrayIndexOutOfBounds Exception being raised.
Example 2
The following example takes a user-supplied value to allocate an array of objects and then operates on the array.
(bad code)
Example Language: Java
private void buildList ( int untrustedListSize ){
if ( 0 > untrustedListSize ){
die("Negative value supplied for list size, die evil hacker!");
} Widget[] list = new Widget [ untrustedListSize ]; list[0] = new Widget();
}
This example attempts to build a list from a user-specified value, and even checks to ensure a non-negative value is supplied. If, however, a 0 value is provided, the code will build an array of size 0 and then try to store a new Widget in the first location, causing an exception to be thrown.
Example 3
In the following code, the method retrieves a value from an array at a specific array index location that is given as an input parameter to the method
(bad code)
Example Language: C
int getValueFromArray(int *array, int len, int index) {
int value;
// check that the array index is less than the maximum
// length of the array if (index < len) {
// get the value at the specified index of the array value = array[index];
} // if array index is invalid then output error message
// and return value indicating error else {
printf("Value is: %d\n", array[index]); value = -1;
}
return value;
}
However, this method only verifies that the given array index is less than the maximum length of the array but does not check for the minimum value (CWE-839). This will allow a negative value to be accepted as the input array index, which will result in a out of bounds read (CWE-125) and may allow access to sensitive memory. The input array index should be checked to verify that is within the maximum and minimum range required for the array (CWE-129). In this example the if statement should be modified to include a minimum range check, as shown below.
(good code)
Example Language: C
...
// check that the array index is within the correct
// range of values for the array if (index >= 0 && index < len) {
...
Example 4
The following example retrieves the sizes of messages for a pop3 mail server. The message sizes are retrieved from a socket that returns in a buffer the message number and the message size, the message number (num) and size (size) are extracted from the buffer and the message size is placed into an array using the message number for the array index.
(bad code)
Example Language: C
/* capture the sizes of all messages */ int getsizes(int sock, int count, int *sizes) {
... char buf[BUFFER_SIZE]; int ok; int num, size;
// read values from socket and added to sizes array while ((ok = gen_recv(sock, buf, sizeof(buf))) == 0) {
// continue read from socket until buf only contains '.' if (DOTLINE(buf))
break;
else if (sscanf(buf, "%d %d", &num, &size) == 2)
sizes[num - 1] = size;
}
...
}
In this example the message number retrieved from the buffer could be a value that is outside the allowable range of indices for the array and could possibly be a negative number. Without proper validation of the value to be used for the array index an array overflow could occur and could potentially lead to unauthorized access to memory addresses and system crashes. The value of the array index should be validated to ensure that it is within the allowable range of indices for the array as in the following code.
(good code)
Example Language: C
/* capture the sizes of all messages */ int getsizes(int sock, int count, int *sizes) {
... char buf[BUFFER_SIZE]; int ok; int num, size;
// read values from socket and added to sizes array while ((ok = gen_recv(sock, buf, sizeof(buf))) == 0) {
// continue read from socket until buf only contains '.' if (DOTLINE(buf))
break;
else if (sscanf(buf, "%d %d", &num, &size) == 2) {
if (num > 0 && num <= (unsigned)count)
sizes[num - 1] = size;
else
/* warn about possible attempt to induce buffer overflow */ report(stderr, "Warning: ignoring bogus data for message sizes returned by server.\n");
}
}
...
}
Example 5
In the following example the method displayProductSummary is called from a Web service servlet to retrieve product summary information for display to the user. The servlet obtains the integer value of the product number from the user and passes it to the displayProductSummary method. The displayProductSummary method passes the integer value of the product number to the getProductSummary method which obtains the product summary from the array object containing the project summaries using the integer value of the product number as the array index.
(bad code)
Example Language: Java
// Method called from servlet to obtain product information public String displayProductSummary(int index) {
String productSummary = new String("");
try {
String productSummary = getProductSummary(index);
} catch (Exception ex) {...}
return productSummary;
}
public String getProductSummary(int index) {
return products[index];
}
In this example the integer value used as the array index that is provided by the user may be outside the allowable range of indices for the array which may provide unexpected results or cause the application to fail. The integer value used for the array index should be validated to ensure that it is within the allowable range of indices for the array as in the following code.
(good code)
Example Language: Java
// Method called from servlet to obtain product information public String displayProductSummary(int index) {
String productSummary = new String("");
try {
String productSummary = getProductSummary(index);
} catch (Exception ex) {...}
return productSummary;
}
public String getProductSummary(int index) {
String productSummary = "";
if ((index >= 0) && (index < MAX_PRODUCTS)) {
productSummary = products[index];
} else {
System.err.println("index is out of bounds"); throw new IndexOutOfBoundsException();
}
return productSummary;
}
An alternative in Java would be to use one of the collection objects such as ArrayList that will automatically generate an exception if an attempt is made to access an array index that is out of bounds.
(good code)
Example Language: Java
ArrayList productArray = new ArrayList(MAX_PRODUCTS); ... try {
The following example asks a user for an offset into an array to select an item.
(bad code)
Example Language: C
int main (int argc, char **argv) {
char *items[] = {"boat", "car", "truck", "train"}; int index = GetUntrustedOffset(); printf("You selected %s\n", items[index-1]);
}
The programmer allows the user to specify which element in the list to select, however an attacker can provide an out-of-bounds offset, resulting in a buffer over-read (CWE-126).
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: array index error (CWE-129) leads to deadlock (CWE-833)
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
The most common condition situation leading to an out-of-bounds array index is the use of loop index variables as buffer indexes. If the end condition for the loop is subject to a flaw, the index can grow or shrink unbounded, therefore causing a buffer overflow or underflow. Another common situation leading to this condition is the use of a function's return value, or the resulting value of a calculation directly as an index in to a buffer.
Detection
Methods
Method
Details
Automated Static Analysis
This weakness can often be detected using automated static analysis tools. Many modern tools use data flow analysis or constraint-based techniques to minimize the number of false positives.
Automated static analysis generally does not account for environmental considerations when reporting out-of-bounds memory operations. This can make it difficult for users to determine which warnings should be investigated first. For example, an analysis tool might report array index errors that originate from command line arguments in a program that is not expected to run with setuid or other special privileges.
Effectiveness: High
Note:This is not a perfect solution, since 100% accuracy and coverage are not feasible.
Automated Dynamic Analysis
This weakness can be detected using dynamic tools and techniques that interact with the software using large test suites with many diverse inputs, such as fuzz testing (fuzzing), robustness testing, and fault injection. The software's operation may slow down, but it should not become unstable, crash, or generate incorrect results.
Black Box
Black box methods might not get the needed code coverage within limited time constraints, and a dynamic test might not produce any noticeable side effects even if it is successful.
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 06 - Arrays and the STL (ARR)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
This weakness can precede uncontrolled memory allocation (CWE-789) in languages that automatically expand an array when an index is used that is larger than the size of the array, such as JavaScript.
Theoretical
An improperly validated array index might lead directly to the always-incorrect behavior of "access of array using out-of-bounds index."
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Unchecked array indexing
PLOVER
INDEX - Array index overflow
CERT C Secure Coding
ARR00-C
Understand how arrays work
CERT C Secure Coding
ARR30-C
CWE More Specific
Do not form or use out-of-bounds pointers or array subscripts
CERT C Secure Coding
ARR38-C
Do not add or subtract an integer to a pointer if the resulting value does not refer to a valid array element
CERT C Secure Coding
INT32-C
Ensure that operations on signed integers do not result in overflow
SEI CERT Perl Coding Standard
IDS32-PL
Imprecise
Validate any integer that is used as an array index
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product manages a group of objects or resources and performs a separate memory allocation for each object, but it does not properly limit the total amount of memory that is consumed by all of the combined objects.
Extended Description
While the product might limit the amount of memory that is allocated in a single operation for a single object (such as a malloc of an array), if an attacker can cause multiple objects to be allocated in separate operations, then this might cause higher total memory consumption than the developer intended, leading to a denial of service.
Alternate Terms
Stack Exhaustion
When a weakness allocates excessive memory on the stack, it is often described as "stack exhaustion," which is a technical impact of the weakness. This technical impact is often encountered as a consequence of CWE-789 and/or CWE-1325.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
DoS: Resource Consumption (Memory)
Scope: Availability
Not controlling memory allocation can result in a request for too much system memory, possibly leading to a crash of the application due to out-of-memory conditions, or the consumption of a large amount of memory on the system.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Ensure multiple allocations of the same kind of object are properly tracked - possibly across multiple sessions, requests, or messages. Define an appropriate strategy for handling requests that exceed the limit, and consider supporting a configuration option so that the administrator can extend the amount of memory to be used if necessary.
Operation
Run the program using system-provided resource limits for memory. This might still cause the program to crash or exit, but the impact to the rest of the system will be minimized.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Allocation of Resources Without Limits or Throttling
PeerOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Class: Not Language-Specific
(Undetermined Prevalence)
Demonstrative Examples
Example 1
This example contains a small allocation of stack memory. When the program was first constructed, the number of times this memory was allocated was probably inconsequential and presented no problem. Over time, as the number of objects in the database grow, the number of allocations will grow - eventually consuming the available stack, i.e. "stack exhaustion." An attacker who is able to add elements to the database could cause stack exhaustion more rapidly than assumed by the developer.
(bad code)
Example Language: C
// Gets the size from the number of objects in a database, which over time can conceivably get very large
int end_limit = get_nmbr_obj_from_db();
int i;
int *base = NULL;
int *p =base;
for (i = 0; i < end_limit; i++)
{
*p = alloca(sizeof(int *)); // Allocate memory on the stack
p = *p; // // Point to the next location to be saved
}
Since this uses alloca(), it allocates memory directly on the stack. If end_limit is large enough, then the stack can be entirely consumed.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: an integer overflow (CWE-190) in the image size calculation causes an infinite loop (CWE-835) which sequentially allocates buffers without limits (CWE-1325) until the stack is full.
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
An integer value is specified to be shifted by a negative amount or an amount greater than or equal to the number of bits contained in the value causing an unexpected or indeterminate result.
Extended Description
Specifying a value to be shifted by a negative amount is undefined in various languages. Various computer architectures implement this action in different ways. The compilers and interpreters when generating code to accomplish a shift generally do not do a check for this issue.
Specifying an over-shift, a shift greater than or equal to the number of bits contained in a value to be shifted, produces a result which varies by architecture and compiler. In some languages, this action is specifically listed as producing an undefined result.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
DoS: Crash, Exit, or Restart
Scope: Integrity
Potential Mitigations
Phase(s)
Mitigation
Implementation
Implicitly or explicitly add checks and mitigation for negative or over-shift values.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Adding shifts without properly verifying the size and sign of the shift amount.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
JavaScript
(Undetermined Prevalence)
Operating Systems
Class: Not OS-Specific
(Undetermined Prevalence)
Technologies
Class: Not Technology-Specific
(Undetermined Prevalence)
Demonstrative Examples
Example 1
A negative shift amount for an x86 or x86_64 shift instruction will produce the number of bits to be shifted by taking a 2's-complement of the shift amount and effectively masking that amount to the lowest 6 bits for a 64 bit shift instruction.
(bad code)
Example Language: C
unsigned int r = 1 << -5;
The example above ends up with a shift amount of -5. The hexadecimal value is FFFFFFFFFFFFFFFD which, when bits above the 6th bit are masked off, the shift amount becomes a binary shift value of 111101 which is 61 decimal. A shift of 61 produces a very different result than -5. The previous example is a very simple version of the following code which is probably more realistic of what happens in a real system.
(bad code)
Example Language: C
int choose_bit(int reg_bit, int bit_number_from_elsewhere)
{
if (NEED_TO_SHIFT)
{
reg_bit -= bit_number_from_elsewhere;
}
return reg_bit;
}
unsigned int handle_io_register(unsigned int *r)
{
int choose_bit(int reg_bit, int bit_number_from_elsewhere)
{
if (NEED_TO_SHIFT)
{
reg_bit -= bit_number_from_elsewhere;
}
return reg_bit;
}
unsigned int handle_io_register(unsigned int *r)
{
int the_bit_number = choose_bit(5, 10);
if ((the_bit_number > 0) && (the_bit_number < 63))
{
unsigned int the_bit = 1 << the_bit_number;
*r |= the_bit;
}
return the_bit;
}
Note that the good example not only checks for negative shifts and disallows them, but it also checks for over-shifts. No bit operation is done if the shift is out of bounds. Depending on the program, perhaps an error message should be logged.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
LED driver overshifts under certain conditions resulting in a DoS.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The code does not explicitly delimit a block that is intended to contain 2 or more statements, creating a logic error.
Extended Description
In some languages, braces (or other delimiters) are optional for blocks. When the delimiter is omitted, it is possible to insert a logic error in which a statement is thought to be in a block but is not. In some cases, the logic error can have security implications.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Alter Execution Logic
Scope: Confidentiality, Integrity, Availability
This is a general logic error which will often lead to obviously-incorrect behaviors that are quickly noticed and fixed. In lightly tested or untested code, this error may be introduced it into a production environment and provide additional attack vectors by creating a control flow path leading to an unexpected state in the application. The consequences will depend on the types of behaviors that are being incorrectly executed.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Always use explicit block delimitation and use static-analysis technologies to enforce this practice.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Sometimes Prevalent)
C++
(Sometimes Prevalent)
Likelihood Of Exploit
Low
Demonstrative Examples
Example 1
In this example, the programmer has indented the statements to call Do_X() and Do_Y(), as if the intention is that these functions are only called when the condition is true. However, because there are no braces to signify the block, Do_Y() will always be executed, even if the condition is false.
(bad code)
Example Language: C
if (condition==true)
Do_X(); Do_Y();
This might not be what the programmer intended. When the condition is critical for security, such as in making a security decision or detecting a critical error, this may produce a vulnerability.
Example 2
In this example, the programmer has indented the Do_Y() statement as if the intention is that the function should be associated with the preceding conditional and should only be called when the condition is true. However, because Do_X() was called on the same line as the conditional and there are no braces to signify the block, Do_Y() will always be executed, even if the condition is false.
(bad code)
Example Language: C
if (condition==true) Do_X();
Do_Y();
This might not be what the programmer intended. When the condition is critical for security, such as in making a security decision or detecting a critical error, this may produce a vulnerability.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
incorrect indentation of "goto" statement makes it more difficult to detect an incorrect goto (Apple's "goto fail")
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Indirect
(where the weakness is a quality issue that might indirectly make it easier to introduce security-relevant weaknesses or make them more difficult to detect)
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Comprehensive Categorization: Insufficient Control Flow Management
Vulnerability Mapping Notes
Usage
ALLOWED
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product does not correctly calculate the size to be used when allocating a buffer, which could lead to a buffer overflow.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
DoS: Crash, Exit, or Restart; Execute Unauthorized Code or Commands; Read Memory; Modify Memory
Scope: Integrity, Availability, Confidentiality
If the incorrect calculation is used in the context of memory allocation, then the software may create a buffer that is smaller or larger than expected. If the allocated buffer is smaller than expected, this could lead to an out-of-bounds read or write (CWE-119), possibly causing a crash, allowing arbitrary code execution, or exposing sensitive data.
Potential Mitigations
Phase(s)
Mitigation
Implementation
When allocating a buffer for the purpose of transforming, converting, or encoding an input, allocate enough memory to handle the largest possible encoding. For example, in a routine that converts "&" characters to "&" for HTML entity encoding, the output buffer needs to be at least 5 times as large as the input buffer.
Implementation
Understand the programming language's underlying representation and how it interacts with numeric calculation (CWE-681). Pay close attention to byte size discrepancies, precision, signed/unsigned distinctions, truncation, conversion and casting between types, "not-a-number" calculations, and how the language handles numbers that are too large or too small for its underlying representation. [REF-7]
Also be careful to account for 32-bit, 64-bit, and other potential differences that may affect the numeric representation.
Implementation
Strategy: Input Validation
Perform input validation on any numeric input by ensuring that it is within the expected range. Enforce that the input meets both the minimum and maximum requirements for the expected range.
Architecture and Design
For any security checks that are performed on the client side, ensure that these checks are duplicated on the server side, in order to avoid CWE-602. Attackers can bypass the client-side checks by modifying values after the checks have been performed, or by changing the client to remove the client-side checks entirely. Then, these modified values would be submitted to the server.
Implementation
When processing structured incoming data containing a size field followed by raw data, identify and resolve any inconsistencies between the size field and the actual size of the data (CWE-130).
Implementation
When allocating memory that uses sentinels to mark the end of a data structure - such as NUL bytes in strings - make sure you also include the sentinel in your calculation of the total amount of memory that must be allocated.
Implementation
Replace unbounded copy functions with analogous functions that support length arguments, such as strcpy with strncpy. Create these if they are not available.
Effectiveness: Moderate
Note: This approach is still susceptible to calculation errors, including issues such as off-by-one errors (CWE-193) and incorrectly calculating buffer lengths (CWE-131). Additionally, this only addresses potential overflow issues. Resource consumption / exhaustion issues are still possible.
Implementation
Use sizeof() on the appropriate data type to avoid CWE-467.
Implementation
Use the appropriate type for the desired action. For example, in C/C++, only use unsigned types for values that could never be negative, such as height, width, or other numbers related to quantity. This will simplify validation and will reduce surprises related to unexpected casting.
Architecture and Design
Strategy: Libraries or Frameworks
Use a vetted library or framework that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
Use libraries or frameworks that make it easier to handle numbers without unexpected consequences, or buffer allocation routines that automatically track buffer size.
Examples include safe integer handling packages such as SafeInt (C++) or IntegerLib (C or C++). [REF-106]
Operation; Build and Compilation
Strategy: Environment Hardening
Use automatic buffer overflow detection mechanisms that are offered by certain compilers or compiler extensions. Examples include: the Microsoft Visual Studio /GS flag, Fedora/Red Hat FORTIFY_SOURCE GCC flag, StackGuard, and ProPolice, which provide various mechanisms including canary-based detection and range/index checking.
D3-SFCV (Stack Frame Canary Validation) from D3FEND [REF-1334] discusses canary-based detection in detail.
Effectiveness: Defense in Depth
Note:
This is not necessarily a complete solution, since these mechanisms only detect certain types of overflows. In addition, the result is still a denial of service, since the typical response is to exit the application.
Operation; Build and Compilation
Strategy: Environment Hardening
Run or compile the software using features or extensions that randomly arrange the positions of a program's executable and libraries in memory. Because this makes the addresses unpredictable, it can prevent an attacker from reliably jumping to exploitable code.
Examples include Address Space Layout Randomization (ASLR) [REF-58] [REF-60] and Position-Independent Executables (PIE) [REF-64]. Imported modules may be similarly realigned if their default memory addresses conflict with other modules, in a process known as "rebasing" (for Windows) and "prelinking" (for Linux) [REF-1332] using randomly generated addresses. ASLR for libraries cannot be used in conjunction with prelink since it would require relocating the libraries at run-time, defeating the whole purpose of prelinking.
For more information on these techniques see D3-SAOR (Segment Address Offset Randomization) from D3FEND [REF-1335].
Effectiveness: Defense in Depth
Note: These techniques do not provide a complete solution. For instance, exploits frequently use a bug that discloses memory addresses in order to maximize reliability of code execution [REF-1337]. It has also been shown that a side-channel attack can bypass ASLR [REF-1333]
Operation
Strategy: Environment Hardening
Use a CPU and operating system that offers Data Execution Protection (using hardware NX or XD bits) or the equivalent techniques that simulate this feature in software, such as PaX [REF-60] [REF-61]. These techniques ensure that any instruction executed is exclusively at a memory address that is part of the code segment.
For more information on these techniques see D3-PSEP (Process Segment Execution Prevention) from D3FEND [REF-1336].
Effectiveness: Defense in Depth
Note: This is not a complete solution, since buffer overflows could be used to overwrite nearby variables to modify the software's state in dangerous ways. In addition, it cannot be used in cases in which self-modifying code is required. Finally, an attack could still cause a denial of service, since the typical response is to exit the application.
Implementation
Strategy: Compilation or Build Hardening
Examine compiler warnings closely and eliminate problems with potential security implications, such as signed / unsigned mismatch in memory operations, or use of uninitialized variables. Even if the weakness is rarely exploitable, a single failure may lead to the compromise of the entire system.
Architecture and Design; Operation
Strategy: Environment Hardening
Run your code using the lowest privileges that are required to accomplish the necessary tasks [REF-76]. If possible, create isolated accounts with limited privileges that are only used for a single task. That way, a successful attack will not immediately give the attacker access to the rest of the software or its environment. For example, database applications rarely need to run as the database administrator, especially in day-to-day operations.
Architecture and Design; Operation
Strategy: Sandbox or Jail
Run the code in a "jail" or similar sandbox environment that enforces strict boundaries between the process and the operating system. This may effectively restrict which files can be accessed in a particular directory or which commands can be executed by the software.
OS-level examples include the Unix chroot jail, AppArmor, and SELinux. In general, managed code may provide some protection. For example, java.io.FilePermission in the Java SecurityManager allows the software to specify restrictions on file operations.
This may not be a feasible solution, and it only limits the impact to the operating system; the rest of the application may still be subject to compromise.
Be careful to avoid CWE-243 and other weaknesses related to jails.
Effectiveness: Limited
Note: The effectiveness of this mitigation depends on the prevention capabilities of the specific sandbox or jail being used and might only help to reduce the scope of an attack, such as restricting the attacker to certain system calls or limiting the portion of the file system that can be accessed.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
The following code allocates memory for a maximum number of widgets. It then gets a user-specified number of widgets, making sure that the user does not request too many. It then initializes the elements of the array using InitializeWidget(). Because the number of widgets can vary for each request, the code inserts a NULL pointer to signify the location of the last widget.
(bad code)
Example Language: C
int i; unsigned int numWidgets; Widget **WidgetList;
However, this code contains an off-by-one calculation error (CWE-193). It allocates exactly enough space to contain the specified number of widgets, but it does not include the space for the NULL pointer. As a result, the allocated buffer is smaller than it is supposed to be (CWE-131). So if the user ever requests MAX_NUM_WIDGETS, there is an out-of-bounds write (CWE-787) when the NULL is assigned. Depending on the environment and compilation settings, this could cause memory corruption.
Example 2
The following image processing code allocates a table for images.
This code intends to allocate a table of size num_imgs, however as num_imgs grows large, the calculation determining the size of the list will eventually overflow (CWE-190). This will result in a very small list to be allocated instead. If the subsequent code operates on the list as if it were num_imgs long, it may result in many types of out-of-bounds problems (CWE-119).
Example 3
This example applies an encoding procedure to an input string and stores it into a buffer.
(bad code)
Example Language: C
char * copy_input(char *user_supplied_string){
int i, dst_index; char *dst_buf = (char*)malloc(4*sizeof(char) * MAX_SIZE); if ( MAX_SIZE <= strlen(user_supplied_string) ){
die("user string too long, die evil hacker!");
} dst_index = 0; for ( i = 0; i < strlen(user_supplied_string); i++ ){
The programmer attempts to encode the ampersand character in the user-controlled string, however the length of the string is validated before the encoding procedure is applied. Furthermore, the programmer assumes encoding expansion will only expand a given character by a factor of 4, while the encoding of the ampersand expands by 5. As a result, when the encoding procedure expands the string it is possible to overflow the destination buffer if the attacker provides a string of many ampersands.
Example 4
The following code is intended to read an incoming packet from a socket and extract one or more headers.
(bad code)
Example Language: C
DataPacket *packet; int numHeaders; PacketHeader *headers;
The code performs a check to make sure that the packet does not contain too many headers. However, numHeaders is defined as a signed int, so it could be negative. If the incoming packet specifies a value such as -3, then the malloc calculation will generate a negative number (say, -300 if each header can be a maximum of 100 bytes). When this result is provided to malloc(), it is first converted to a size_t type. This conversion then produces a large value such as 4294966996, which may cause malloc() to fail or to allocate an extremely large amount of memory (CWE-195). With the appropriate negative numbers, an attacker could trick malloc() into using a very small positive number, which then allocates a buffer that is much smaller than expected, potentially leading to a buffer overflow.
Example 5
The following code attempts to save three different identification numbers into an array. The array is allocated from memory using a call to malloc().
(bad code)
Example Language: C
int *id_sequence;
/* Allocate space for an array of three ids. */
id_sequence = (int*) malloc(3); if (id_sequence == NULL) exit(1);
The problem with the code above is the value of the size parameter used during the malloc() call. It uses a value of '3' which by definition results in a buffer of three bytes to be created. However the intention was to create a buffer that holds three ints, and in C, each int requires 4 bytes worth of memory, so an array of 12 bytes is needed, 4 bytes for each int. Executing the above code could result in a buffer overflow as 12 bytes of data is being saved into 3 bytes worth of allocated space. The overflow would occur during the assignment of id_sequence[0] and would continue with the assignment of id_sequence[1] and id_sequence[2].
The malloc() call could have used '3*sizeof(int)' as the value for the size parameter in order to allocate the correct amount of space required to store the three ints.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Font rendering library does not properly
handle assigning a signed short value to an unsigned
long (CWE-195), leading to an integer wraparound
(CWE-190), causing too small of a buffer (CWE-131),
leading to an out-of-bounds write
(CWE-787).
Chain: integer truncation (CWE-197) causes small buffer allocation (CWE-131) leading to out-of-bounds write (CWE-787) in kernel pool, as exploited in the wild per CISA KEV.
Chain: Language interpreter calculates wrong buffer size (CWE-131) by using "size = ptr ? X : Y" instead of "size = (ptr ? X : Y)" expression.
Detection
Methods
Method
Details
Automated Static Analysis
This weakness can often be detected using automated static analysis tools. Many modern tools use data flow analysis or constraint-based techniques to minimize the number of false positives.
Automated static analysis generally does not account for environmental considerations when reporting potential errors in buffer calculations. This can make it difficult for users to determine which warnings should be investigated first. For example, an analysis tool might report buffer overflows that originate from command line arguments in a program that is not expected to run with setuid or other special privileges.
Effectiveness: High
Note:Detection techniques for buffer-related errors are more mature than for most other weakness types.
Automated Dynamic Analysis
This weakness can be detected using dynamic tools and techniques that interact with the software using large test suites with many diverse inputs, such as fuzz testing (fuzzing), robustness testing, and fault injection. The software's operation may slow down, but it should not become unstable, crash, or generate incorrect results.
Effectiveness: Moderate
Note:Without visibility into the code, black box methods may not be able to sufficiently distinguish this weakness from others, requiring follow-up manual methods to diagnose the underlying problem.
Manual Analysis
Manual analysis can be useful for finding this weakness, but it might not achieve desired code coverage within limited time constraints. This becomes difficult for weaknesses that must be considered for all inputs, since the attack surface can be too large.
Manual Analysis
This weakness can be detected using tools and techniques that require manual (human) analysis, such as penetration testing, threat modeling, and interactive tools that allow the tester to record and modify an active session.
Specifically, manual static analysis is useful for evaluating the correctness of allocation calculations. This can be useful for detecting overflow conditions (CWE-190) or similar weaknesses that might have serious security impacts on the program.
Effectiveness: High
Note:These may be more effective than strictly automated techniques. This is especially the case with weaknesses that are related to design and business rules.
Automated Static Analysis - Binary or Bytecode
According to SOAR, the following detection techniques may be useful:
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 08 - Memory Management (MEM)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Maintenance
This is a broad category. Some examples include:
simple math errors,
incorrectly updating parallel counters,
not accounting for size differences when "transforming" one input to another format (e.g. URL canonicalization or other transformation that can generate a result that's larger than the original input, i.e. "expansion").
This level of detail is rarely available in public reports, so it is difficult to find good examples.
Maintenance
This weakness may be a composite or a chain. It also may contain layering or perspective differences.
This issue may be associated with many different types of incorrect calculations (CWE-682), although the integer overflow (CWE-190) is probably the most prevalent. This can be primary to resource consumption problems (CWE-400), including uncontrolled memory allocation (CWE-789). However, its relationship with out-of-bounds buffer access (CWE-119) must also be considered.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Other length calculation error
CERT C Secure Coding
INT30-C
Imprecise
Ensure that unsigned integer operations do not wrap
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 5: Buffer Overruns." Page 89. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 8, "Incrementing Pointers Incorrectly", Page 401. 1st Edition. Addison Wesley. 2006.
CWE-135: Incorrect Calculation of Multi-Byte String Length
Weakness ID: 135
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product does not correctly calculate the length of strings that can contain wide or multi-byte characters.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
This weakness may lead to a buffer overflow. Buffer overflows often can be used to execute arbitrary code, which is usually outside the scope of a program's implicit security policy. This can often be used to subvert any other security service.
Out of bounds memory access will very likely result in the corruption of relevant memory, and perhaps instructions, possibly leading to a crash. Other attacks leading to lack of availability are possible, including putting the program into an infinite loop.
Read Memory
Scope: Confidentiality
In the case of an out-of-bounds read, the attacker may have access to sensitive information. If the sensitive information contains system details, such as the current buffer's position in memory, this knowledge can be used to craft further attacks, possibly with more severe consequences.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Strategy: Input Validation
Always verify the length of the string unit character.
Implementation
Strategy: Libraries or Frameworks
Use length computing functions (e.g. strlen, wcslen, etc.) appropriately with their equivalent type (e.g.: byte, wchar_t, etc.)
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
There are several ways in which improper string length checking may result in an exploitable condition. All of these, however, involve the introduction of buffer overflow conditions in order to reach an exploitable state.
The first of these issues takes place when the output of a wide or multi-byte character string, string-length function is used as a size for the allocation of memory. While this will result in an output of the number of characters in the string, note that the characters are most likely not a single byte, as they are with standard character strings. So, using the size returned as the size sent to new or malloc and copying the string to this newly allocated memory will result in a buffer overflow.
Another common way these strings are misused involves the mixing of standard string and wide or multi-byte string functions on a single string. Invariably, this mismatched information will result in the creation of a possibly exploitable buffer overflow condition.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The following example would be exploitable if any of the commented incorrect malloc calls were used.
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
The CERT Oracle Secure Coding Standard for Java (2011) Chapter 14 - Input Output (FIO)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Improper string length checking
The CERT Oracle Secure Coding Standard for Java (2011)
FIO10-J
Ensure the array is filled when using read() to fill an array
CWE-681: Incorrect Conversion between Numeric Types
Weakness ID: 681
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
When converting from one data type to another, such as long to integer, data can be omitted or translated in a way that produces unexpected values. If the resulting values are used in a sensitive context, then dangerous behaviors may occur.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Unexpected State; Quality Degradation
Scope: Other, Integrity
The program could wind up using the wrong number and generate incorrect results. If the number is used to allocate resources or make a security decision, then this could introduce a vulnerability.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Avoid making conversion between numeric types. Always check for the allowed ranges.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
Class: Not Language-Specific
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
In the following Java example, a float literal is cast to an integer, thus causing a loss of precision.
(bad code)
Example Language: Java
int i = (int) 33457.8f;
Example 2
This code adds a float and an integer together, casting the result to an integer.
Normally, PHP will preserve the precision of this operation, making $result = 4.8345. After the cast to int, it is reasonable to expect PHP to follow rounding convention and set $result = 5. However, the explicit cast to int always rounds DOWN, so the final value of $result is 4. This behavior may have unintended consequences.
Example 3
In this example the variable amount can hold a negative value when it is returned. Because the function is declared to return an unsigned int, amount will be implicitly converted to unsigned.
(bad code)
Example Language: C
unsigned int readdata () {
int amount = 0; ... if (result == ERROR) amount = -1; ... return amount;
}
If the error condition in the code above is met, then the return value of readdata() will be 4,294,967,295 on a system that uses 32-bit integers.
Example 4
In this example, depending on the return value of accecssmainframe(), the variable amount can hold a negative value when it is returned. Because the function is declared to return an unsigned value, amount will be implicitly cast to an unsigned number.
If the return value of accessmainframe() is -1, then the return value of readdata() will be 4,294,967,295 on a system that uses 32-bit integers.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: in a web browser, an unsigned 64-bit integer is forcibly cast to a 32-bit integer (CWE-681) and potentially leading to an integer overflow (CWE-190). If an integer overflow occurs, this can cause heap memory corruption (CWE-122)
Chain: signed short width value in image processor is sign extended during conversion to unsigned int, which leads to integer overflow and heap-based buffer overflow.
Size of a particular type changes for 64-bit platforms, leading to an integer truncation in document processor causes incorrect index to be generated.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 05 - Floating Point Arithmetic (FLP)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CERT C Secure Coding
FLP34-C
CWE More Abstract
Ensure that floating point conversions are within range of the new type
CERT C Secure Coding
INT15-C
Use intmax_t or uintmax_t for formatted IO on programmer-defined integer types
CERT C Secure Coding
INT31-C
CWE More Abstract
Ensure that integer conversions do not result in lost or misinterpreted data
CERT C Secure Coding
INT35-C
Evaluate integer expressions in a larger size before comparing or assigning to that size
The CERT Oracle Secure Coding Standard for Java (2011)
NUM12-J
Ensure conversions of numeric types to narrower types do not result in lost or misinterpreted data
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
In C and C++, one may often accidentally refer to the wrong memory due to the semantics of when math operations are implicitly scaled.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory; Modify Memory
Scope: Confidentiality, Integrity
Incorrect pointer scaling will often result in buffer overflow conditions. Confidentiality can be compromised if the weakness is in the context of a buffer over-read or under-read.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Use a platform with high-level memory abstractions.
Implementation
Always use array indexing instead of direct pointer manipulation.
Architecture and Design
Use technologies for preventing buffer overflows.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Programmers may try to index from a pointer by adding a number of bytes. This is incorrect because C and C++ implicitly scale the operand by the size of the data type.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
This example attempts to calculate the position of the second byte of a pointer.
(bad code)
Example Language: C
int *p = x; char * second_char = (char *)(p + 1);
In this example, second_char is intended to point to the second byte of p. But, adding 1 to p actually adds sizeof(int) to p, giving a result that is incorrect (3 bytes off on 32-bit platforms). If the resulting memory address is read, this could potentially be an information leak. If it is a write, it could be a security-critical write to unauthorized memory-- whether or not it is a buffer overflow. Note that the above code may also be wrong in other ways, particularly in a little endian environment.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C Secure Coding Standard (2008) Chapter 4 - Expressions (EXP)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Unintentional pointer scaling
CERT C Secure Coding
ARR39-C
Exact
Do not add or subtract a scaled integer to a pointer
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 6, "Pointer Arithmetic", Page 277. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID could be used to map to real-world vulnerabilities in limited situations requiring careful review
(with careful review of mapping notes)
Abstraction:
ClassClass - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product does not correctly convert an object, resource, or structure from one type to a different type.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Other
Scope: Other
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Improper Control of a Resource Through its Lifetime
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Attempt to Access Child of a Non-structure Pointer
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Access of Resource Using Incompatible Type ('Type Confusion')
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Incorrect Parsing of Numbers with Different Radices
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses for Simplified Mapping of Published Vulnerabilities
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Access of Resource Using Incompatible Type ('Type Confusion')
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Class: Not Language-Specific
(Undetermined Prevalence)
Demonstrative Examples
Example 1
In this example, depending on the return value of accecssmainframe(), the variable amount can hold a negative value when it is returned. Because the function is declared to return an unsigned value, amount will be implicitly cast to an unsigned number.
If the return value of accessmainframe() is -1, then the return value of readdata() will be 4,294,967,295 on a system that uses 32-bit integers.
Example 2
The following code uses a union to support the representation of different types of messages. It formats messages differently, depending on their type.
buf.msgType = NAME_TYPE; buf.name = defaultMessage; printf("Pointer of buf.name is %p\n", buf.name); /* This particular value for nameID is used to make the code architecture-independent. If coming from untrusted input, it could be any value. */
buf.nameID = (int)(defaultMessage + 1); printf("Pointer of buf.name is now %p\n", buf.name); if (buf.msgType == NAME_TYPE) {
printf("Message: %s\n", buf.name);
} else {
printf("Message: Use ID %d\n", buf.nameID);
}
}
The code intends to process the message as a NAME_TYPE, and sets the default message to "Hello World." However, since both buf.name and buf.nameID are part of the same union, they can act as aliases for the same memory location, depending on memory layout after compilation.
As a result, modification of buf.nameID - an int - can effectively modify the pointer that is stored in buf.name - a string.
Execution of the program might generate output such as:
Pointer of name is 10830
Pointer of name is now 10831
Message: ello World
Notice how the pointer for buf.name was changed, even though buf.name was not explicitly modified.
In this case, the first "H" character of the message is omitted. However, if an attacker is able to fully control the value of buf.nameID, then buf.name could contain an arbitrary pointer, leading to out-of-bounds reads or writes.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: in a web browser, an unsigned 64-bit integer is forcibly cast to a 32-bit integer (CWE-681) and potentially leading to an integer overflow (CWE-190). If an integer overflow occurs, this can cause heap memory corruption (CWE-122)
Chain: data visualization program written in PHP uses the "!=" operator instead of the type-strict "!==" operator (CWE-480) when validating hash values, potentially leading to an incorrect type conversion (CWE-704)
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Note: this date reflects when the entry was first published. Draft versions of this entry were provided to members of the CWE community and modified between Draft 9 and 1.0.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
Integer coercion refers to a set of flaws pertaining to the type casting, extension, or truncation of primitive data types.
Extended Description
Several flaws fall under the category of integer coercion errors. For the most part, these errors in and of themselves result only in availability and data integrity issues. However, in some circumstances, they may result in other, more complicated security related flaws, such as buffer overflow conditions.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Integer coercion often leads to undefined states of execution resulting in infinite loops or crashes.
Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
In some cases, integer coercion errors can lead to exploitable buffer overflow conditions, resulting in the execution of arbitrary code.
Other
Scope: Integrity, Other
Integer coercion errors result in an incorrect value being stored for the variable in question.
Potential Mitigations
Phase(s)
Mitigation
Requirements
A language which throws exceptions on ambiguous data casts might be chosen.
Architecture and Design
Design objects and program flow such that multiple or complex casts are unnecessary
Implementation
Ensure that any data type casting that you must used is entirely understood in order to reduce the plausibility of error in use.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
The following code is intended to read an incoming packet from a socket and extract one or more headers.
(bad code)
Example Language: C
DataPacket *packet; int numHeaders; PacketHeader *headers;
The code performs a check to make sure that the packet does not contain too many headers. However, numHeaders is defined as a signed int, so it could be negative. If the incoming packet specifies a value such as -3, then the malloc calculation will generate a negative number (say, -300 if each header can be a maximum of 100 bytes). When this result is provided to malloc(), it is first converted to a size_t type. This conversion then produces a large value such as 4294966996, which may cause malloc() to fail or to allocate an extremely large amount of memory (CWE-195). With the appropriate negative numbers, an attacker could trick malloc() into using a very small positive number, which then allocates a buffer that is much smaller than expected, potentially leading to a buffer overflow.
Example 2
The following code reads a maximum size and performs validation on that size. It then performs a strncpy, assuming it will not exceed the boundaries of the array. While the use of "short s" is forced in this particular example, short int's are frequently used within real-world code, such as code that processes structured data.
(bad code)
Example Language: C
int GetUntrustedInt () {
return(0x0000FFFF);
}
void main (int argc, char **argv) {
char path[256]; char *input; int i; short s; unsigned int sz;
i = GetUntrustedInt(); s = i; /* s is -1 so it passes the safety check - CWE-697 */ if (s > 256) {
DiePainfully("go away!\n");
}
/* s is sign-extended and saved in sz */ sz = s;
/* output: i=65535, s=-1, sz=4294967295 - your mileage may vary */ printf("i=%d, s=%d, sz=%u\n", i, s, sz);
input = GetUserInput("Enter pathname:");
/* strncpy interprets s as unsigned int, so it's treated as MAX_INT (CWE-195), enabling buffer overflow (CWE-119) */ strncpy(path, input, s); path[255] = '\0'; /* don't want CWE-170 */ printf("Path is: %s\n", path);
}
This code first exhibits an example of CWE-839, allowing "s" to be a negative number. When the negative short "s" is converted to an unsigned integer, it becomes an extremely large positive integer. When this converted integer is used by strncpy() it will lead to a buffer overflow (CWE-119).
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: integer coercion error (CWE-192) prevents a return value from indicating an error, leading to out-of-bounds write (CWE-787)
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Maintenance
Within C, it might be that "coercion" is semantically different than "casting", possibly depending on whether the programmer directly specifies the conversion, or if the compiler does it implicitly. This has implications for the presentation of this entry and others, such as CWE-681, and whether there is enough of a difference for these entries to be split.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Integer coercion error
CERT C Secure Coding
INT02-C
Understand integer conversion rules
CERT C Secure Coding
INT05-C
Do not use input functions to convert character data if they cannot handle all possible inputs
CERT C Secure Coding
INT31-C
Exact
Ensure that integer conversions do not result in lost or misinterpreted data
References
[REF-44]
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 7: Integer Overflows." Page 119. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 6, "Sign Extension", Page 248. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product performs a calculation that can
produce an integer overflow or wraparound when the logic
assumes that the resulting value will always be larger than
the original value. This occurs when an integer value is
incremented to a value that is too large to store in the
associated representation. When this occurs, the value may
become a very small or negative number.
Alternate Terms
Overflow
The terms "overflow" and "wraparound" are
used interchangeably by some people, but they can have
more precise distinctions by others. See Terminology
Notes.
Wraparound
The terms "overflow" and "wraparound" are
used interchangeably by some people, but they can have
more precise distinctions by others. See Terminology
Notes.
wrap, wrap-around, wrap around
Alternate spellings of "wraparound"
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
This weakness can generally lead to undefined behavior and therefore crashes. When the calculated result is used for resource allocation, this weakness can cause too many (or too few) resources to be allocated, possibly enabling crashes if the product requests more resources than can be provided.
Modify Memory
Scope: Integrity
If the value in question is important to data (as opposed to flow), simple data corruption has occurred. Also, if the overflow/wraparound results in other conditions such as buffer overflows, further memory corruption may occur.
Execute Unauthorized Code or Commands; Bypass Protection Mechanism
Scope: Confidentiality, Availability, Access Control
This weakness can sometimes trigger buffer overflows, which can be used to execute arbitrary code. This is usually outside the scope of the product's implicit security policy.
Alter Execution Logic; DoS: Crash, Exit, or Restart; DoS: Resource Consumption (CPU)
Scope: Availability, Other
If the overflow/wraparound occurs in a loop index variable, this could cause the loop to terminate at the wrong time - too early, too late, or not at all (i.e., infinite loops). With too many iterations, some loops could consume too many resources such as memory, file handles, etc., possibly leading to a crash or other DoS.
Bypass Protection Mechanism
Scope: Access Control
If integer values are used in security-critical decisions, such as calculating quotas or allocation limits, integer overflows can be used to cause an incorrect security decision.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Ensure that all protocols are strictly defined, such that all out-of-bounds behavior can be identified simply, and require strict conformance to the protocol.
Requirements
Strategy: Language Selection
Use a language that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
If possible, choose a language or compiler that performs automatic bounds checking.
Architecture and Design
Strategy: Libraries or Frameworks
Use a vetted library or framework that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
Use libraries or frameworks that make it easier to handle numbers without unexpected consequences.
Examples include safe integer handling packages such as SafeInt (C++) or IntegerLib (C or C++). [REF-106]
Implementation
Strategy: Input Validation
Perform input validation on any numeric input by ensuring that it is within the expected range. Enforce that the input meets both the minimum and maximum requirements for the expected range.
Use unsigned integers where possible. This makes it easier to perform validation for integer overflows. When signed integers are required, ensure that the range check includes minimum values as well as maximum values.
Implementation
Understand the programming language's underlying representation and how it interacts with numeric calculation (CWE-681). Pay close attention to byte size discrepancies, precision, signed/unsigned distinctions, truncation, conversion and casting between types, "not-a-number" calculations, and how the language handles numbers that are too large or too small for its underlying representation. [REF-7]
Also be careful to account for 32-bit, 64-bit, and other potential differences that may affect the numeric representation.
Architecture and Design
For any security checks that are performed on the client side, ensure that these checks are duplicated on the server side, in order to avoid CWE-602. Attackers can bypass the client-side checks by modifying values after the checks have been performed, or by changing the client to remove the client-side checks entirely. Then, these modified values would be submitted to the server.
Implementation
Strategy: Compilation or Build Hardening
Examine compiler warnings closely and eliminate problems with potential security implications, such as signed / unsigned mismatch in memory operations, or use of uninitialized variables. Even if the weakness is rarely exploitable, a single failure may lead to the compromise of the entire system.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Chain - a Compound Element that is a sequence of two or more separate weaknesses that can be closely linked together within software. One weakness, X, can directly create the conditions that are necessary to cause another weakness, Y, to enter a vulnerable condition. When this happens, CWE refers to X as "primary" to Y, and Y is "resultant" from X. Chains can involve more than two weaknesses, and in some cases, they might have a tree-like structure.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Insufficient Precision or Accuracy of a Real Number
CanPrecede
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Relevant to the view "Seven Pernicious Kingdoms" (View-700)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
This weakness may become security critical when determining the offset or size in behaviors such as memory allocation, copying, and concatenation.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
Class: Not Language-Specific
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
The following image processing code allocates a table for images.
This code intends to allocate a table of size num_imgs, however as num_imgs grows large, the calculation determining the size of the list will eventually overflow (CWE-190). This will result in a very small list to be allocated instead. If the subsequent code operates on the list as if it were num_imgs long, it may result in many types of out-of-bounds problems (CWE-119).
Example 2
The following code excerpt from OpenSSH 3.3 demonstrates a classic case of integer overflow:
(bad code)
Example Language: C
nresp = packet_get_int(); if (nresp > 0) {
response = xmalloc(nresp*sizeof(char*)); for (i = 0; i < nresp; i++) response[i] = packet_get_string(NULL);
}
If nresp has the value 1073741824 and sizeof(char*) has its typical value of 4, then the result of the operation nresp*sizeof(char*) overflows, and the argument to xmalloc() will be 0. Most malloc() implementations will happily allocate a 0-byte buffer, causing the subsequent loop iterations to overflow the heap buffer response.
Example 3
Integer overflows can be complicated and difficult to detect. The following example is an attempt to show how an integer overflow may lead to undefined looping behavior:
(bad code)
Example Language: C
short int bytesRec = 0; char buf[SOMEBIGNUM];
while(bytesRec < MAXGET) {
bytesRec += getFromInput(buf+bytesRec);
}
In the above case, it is entirely possible that bytesRec may overflow, continuously creating a lower number than MAXGET and also overwriting the first MAXGET-1 bytes of buf.
Example 4
In this example the method determineFirstQuarterRevenue is used to determine the first quarter revenue for an accounting/business application. The method retrieves the monthly sales totals for the first three months of the year, calculates the first quarter sales totals from the monthly sales totals, calculates the first quarter revenue based on the first quarter sales, and finally saves the first quarter revenue results to the database.
// Variable for sales revenue for the quarter float quarterRevenue = 0.0f;
short JanSold = getMonthlySales(JAN); /* Get sales in January */ short FebSold = getMonthlySales(FEB); /* Get sales in February */ short MarSold = getMonthlySales(MAR); /* Get sales in March */
// Calculate quarterly total short quarterSold = JanSold + FebSold + MarSold;
// Calculate the total revenue for the quarter quarterRevenue = calculateRevenueForQuarter(quarterSold);
saveFirstQuarterRevenue(quarterRevenue);
return 0;
}
However, in this example the primitive type short int is used for both the monthly and the quarterly sales variables. In C the short int primitive type has a maximum value of 32768. This creates a potential integer overflow if the value for the three monthly sales adds up to more than the maximum value for the short int primitive type. An integer overflow can lead to data corruption, unexpected behavior, infinite loops and system crashes. To correct the situation the appropriate primitive type should be used, as in the example below, and/or provide some validation mechanism to ensure that the maximum value for the primitive type is not exceeded.
... // Calculate quarterly total long quarterSold = JanSold + FebSold + MarSold;
// Calculate the total revenue for the quarter quarterRevenue = calculateRevenueForQuarter(quarterSold);
...
}
Note that an integer overflow could also occur if the quarterSold variable has a primitive type long but the method calculateRevenueForQuarter has a parameter of type short.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Font rendering library does not properly
handle assigning a signed short value to an unsigned
long (CWE-195), leading to an integer wraparound
(CWE-190), causing too small of a buffer (CWE-131),
leading to an out-of-bounds write
(CWE-787).
Chain: in a web browser, an unsigned 64-bit integer is forcibly cast to a 32-bit integer (CWE-681) and potentially leading to an integer overflow (CWE-190). If an integer overflow occurs, this can cause heap memory corruption (CWE-122)
Chain: Python library does not limit the resources used to process images that specify a very large number of bands (CWE-1284), leading to excessive memory consumption (CWE-789) or an integer overflow (CWE-190).
Chain: integer overflow (CWE-190) causes a negative signed value, which later bypasses a maximum-only check (CWE-839), leading to heap-based buffer overflow (CWE-122).
Chain: integer overflow in securely-coded mail program leads to buffer overflow. In 2005, this was regarded as unrealistic to exploit, but in 2020, it was rediscovered to be easier to exploit due to evolutions of the technology.
Chain: an integer overflow (CWE-190) in the image size calculation causes an infinite loop (CWE-835) which sequentially allocates buffers without limits (CWE-1325) until the stack is full.
Detection
Methods
Method
Details
Automated Static Analysis
This weakness can often be detected using automated static analysis tools. Many modern tools use data flow analysis or constraint-based techniques to minimize the number of false positives.
Effectiveness: High
Black Box
Sometimes, evidence of this weakness can be detected using dynamic tools and techniques that interact with the product using large test suites with many diverse inputs, such as fuzz testing (fuzzing), robustness testing, and fault injection. The product's operation may slow down, but it should not become unstable, crash, or generate incorrect results.
Effectiveness: Moderate
Note:Without visibility into the code, black box methods may not be able to sufficiently distinguish this weakness from others, requiring follow-up manual methods to diagnose the underlying problem.
Manual Analysis
This weakness can be detected using tools and techniques that require manual (human) analysis, such as penetration testing, threat modeling, and interactive tools that allow the tester to record and modify an active session.
Specifically, manual static analysis is useful for evaluating the correctness of allocation calculations. This can be useful for detecting overflow conditions (CWE-190) or similar weaknesses that might have serious security impacts on the program.
Effectiveness: High
Note:These may be more effective than strictly automated techniques. This is especially the case with weaknesses that are related to design and business rules.
Automated Static Analysis - Binary or Bytecode
According to SOAR, the following detection techniques may be useful:
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 08 - Memory Management (MEM)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
SEI CERT C Coding Standard - Guidelines 08. Memory Management (MEM)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2019 CWE Top 25 Most Dangerous Software Errors
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2021 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2020 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2023 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2024 CWE Top 25 Most Dangerous Software Weaknesses
Vulnerability Mapping Notes
Usage
ALLOWED
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Be careful of terminology problems with "overflow," "underflow," and "wraparound" - see Terminology Notes. Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Integer Underflow (Wrap or Wraparound). Consider CWE-191 when the result is less than the minimum value that can be represented (sometimes called "underflows").
Notes
Relationship
Integer overflows can be primary to buffer overflows when they cause less memory to be allocated than expected.
Terminology
"Integer overflow" is
sometimes used to cover several types of errors, including
signedness errors, or buffer overflows that involve
manipulation of integer data types instead of
characters. Part of the confusion results from the fact
that 0xffffffff is -1 in a signed context. Other confusion
also arises because of the role that integer overflows
have in chains.
A "wraparound" is a well-defined, standard
behavior that follows specific rules for how to handle
situations when the intended numeric value is too large or
too small to be represented, as specified in standards
such as C11.
"Overflow" is sometimes conflated with
"wraparound" but typically indicates a non-standard or
undefined behavior.
The "overflow" term is sometimes used to indicate
cases where either the maximum or the minimum is exceeded,
but others might only use "overflow" to indicate exceeding
the maximum while using "underflow" for exceeding the
minimum.
Some people use "overflow" to mean any value
outside the representable range - whether greater than the
maximum, or less than the minimum - but CWE uses
"underflow" for cases in which the intended result is less
than the minimum.
See [REF-1440] for additional explanation of the
ambiguity of terminology.
Other
While there may be circumstances in
which the logic intentionally relies on wrapping - such as
with modular arithmetic in timers or counters - it can
have security consequences if the wrap is unexpected.
This is especially the case if the integer overflow can be
triggered using user-supplied inputs.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Integer overflow (wrap or wraparound)
7 Pernicious Kingdoms
Integer Overflow
CLASP
Integer overflow
CERT C Secure Coding
INT18-C
CWE More Abstract
Evaluate integer expressions in a larger size before comparing or assigning to that size
CERT C Secure Coding
INT30-C
CWE More Abstract
Ensure that unsigned integer operations do not wrap
CERT C Secure Coding
INT32-C
Imprecise
Ensure that operations on signed integers do not result in overflow
CERT C Secure Coding
INT35-C
Evaluate integer expressions in a larger size before comparing or assigning to that size
CERT C Secure Coding
MEM07-C
CWE More Abstract
Ensure that the arguments to calloc(), when multiplied, do not wrap
Yves Younan. "An overview of common programming security vulnerabilities and possible solutions". Student thesis section 5.4.3. 2003-08.
<http://fort-knox.org/thesis.pdf>.
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 6, "Signed Integer Boundaries", Page 220. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product subtracts one value from another, such that the result is less than the minimum allowable integer value, which produces a value that is not equal to the correct result.
Extended Description
This can happen in signed and unsigned cases.
Alternate Terms
Integer underflow
"Integer underflow" is sometimes used to identify signedness errors in which an originally positive number becomes negative as a result of subtraction. However, there are cases of bad subtraction in which unsigned integers are involved, so it's not always a signedness issue.
"Integer underflow" is occasionally used to describe array index errors in which the index is negative.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
This weakness will generally lead to undefined behavior and therefore crashes. In the case of overflows involving loop index variables, the likelihood of infinite loops is also high.
Modify Memory
Scope: Integrity
If the value in question is important to data (as opposed to flow), simple data corruption has occurred. Also, if the wrap around results in other conditions such as buffer overflows, further memory corruption may occur.
Execute Unauthorized Code or Commands; Bypass Protection Mechanism
Scope: Confidentiality, Availability, Access Control
This weakness can sometimes trigger buffer overflows which can be used to execute arbitrary code. This is usually outside the scope of a program's implicit security policy.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The following example subtracts from a 32 bit signed integer.
(bad code)
Example Language: C
#include <stdio.h> #include <stdbool.h> main (void) {
int i; i = -2147483648; i = i - 1; return 0;
}
The example has an integer underflow. The value of i is already at the lowest negative value possible, so after subtracting 1, the new value of i is 2147483647.
Example 2
This code performs a stack allocation based on a length calculation.
(bad code)
Example Language: C
int a = 5, b = 6;
size_t len = a - b;
char buf[len]; // Just blows up the stack
}
Since a and b are declared as signed ints, the "a - b" subtraction gives a negative result (-1). However, since len is declared to be unsigned, len is cast to an extremely large positive number (on 32-bit systems - 4294967295). As a result, the buffer buf[len] declaration uses an extremely large size to allocate on the stack, very likely more than the entire computer's memory space.
Miscalculations usually will not be so obvious. The calculation will either be complicated or the result of an attacker's input to attain the negative value.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Malformed icon causes integer underflow in loop counter variable.
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Integer underflow (wrap or wraparound)
Software Fault Patterns
SFP1
Glitch in computation
CERT C Secure Coding
INT30-C
Imprecise
Ensure that unsigned integer operations do not wrap
CERT C Secure Coding
INT32-C
Imprecise
Ensure that operations on signed integers do not result in overflow
References
[REF-44]
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 7: Integer Overflows." Page 119. McGraw-Hill. 2010.
CWE-789: Memory Allocation with Excessive Size Value
Weakness ID: 789
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product allocates memory based on an untrusted, large size value, but it does not ensure that the size is within expected limits, allowing arbitrary amounts of memory to be allocated.
Alternate Terms
Stack Exhaustion
When a weakness allocates excessive memory on the stack, it is often described as "stack exhaustion," which is a technical impact of the weakness. This technical impact is often encountered as a consequence of CWE-789 and/or CWE-1325.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
DoS: Resource Consumption (Memory)
Scope: Availability
Not controlling memory allocation can result in a request for too much system memory, possibly leading to a crash of the application due to out-of-memory conditions, or the consumption of a large amount of memory on the system.
Potential Mitigations
Phase(s)
Mitigation
Implementation; Architecture and Design
Perform adequate input validation against any value that influences the amount of memory that is allocated. Define an appropriate strategy for handling requests that exceed the limit, and consider supporting a configuration option so that the administrator can extend the amount of memory to be used if necessary.
Operation
Run your program using system-provided resource limits for memory. This might still cause the program to crash or exit, but the impact to the rest of the system will be minimized.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Allocation of Resources Without Limits or Throttling
PeerOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Improper Validation of Specified Quantity in Input
CanPrecede
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Class: Not Language-Specific
(Undetermined Prevalence)
Demonstrative Examples
Example 1
Consider the following code, which accepts an untrusted size value and allocates a buffer to contain a string of the given size.
(bad code)
Example Language: C
unsigned int size = GetUntrustedInt(); /* ignore integer overflow (CWE-190) for this example */
This will cause 305,419,896 bytes (over 291 megabytes) to be allocated for the string.
Example 2
Consider the following code, which accepts an untrusted size value and uses the size as an initial capacity for a HashMap.
(bad code)
Example Language: Java
unsigned int size = GetUntrustedInt(); HashMap list = new HashMap(size);
The HashMap constructor will verify that the initial capacity is not negative, however there is no check in place to verify that sufficient memory is present. If the attacker provides a large enough value, the application will run into an OutOfMemoryError.
Example 3
This code performs a stack allocation based on a length calculation.
(bad code)
Example Language: C
int a = 5, b = 6;
size_t len = a - b;
char buf[len]; // Just blows up the stack
}
Since a and b are declared as signed ints, the "a - b" subtraction gives a negative result (-1). However, since len is declared to be unsigned, len is cast to an extremely large positive number (on 32-bit systems - 4294967295). As a result, the buffer buf[len] declaration uses an extremely large size to allocate on the stack, very likely more than the entire computer's memory space.
Miscalculations usually will not be so obvious. The calculation will either be complicated or the result of an attacker's input to attain the negative value.
Example 4
This example shows a typical attempt to parse a string with an error resulting from a difference in assumptions between the caller to a function and the function's action.
(bad code)
Example Language: C
int proc_msg(char *s, int msg_len)
{
// Note space at the end of the string - assume all strings have preamble with space
int pre_len = sizeof("preamble: ");
char buf[pre_len - msg_len]; ... Do processing here if we get this far
}
char *s = "preamble: message\n";
char *sl = strchr(s, ':'); // Number of characters up to ':' (not including space)
int jnklen = sl == NULL ? 0 : sl - s; // If undefined pointer, use zero length
int ret_val = proc_msg ("s", jnklen); // Violate assumption of preamble length, end up with negative value, blow out stack
The buffer length ends up being -1, resulting in a blown out stack. The space character after the colon is included in the function calculation, but not in the caller's calculation. This, unfortunately, is not usually so obvious but exists in an obtuse series of calculations.
Example 5
The following code obtains an untrusted number that is used as an index into an array of messages.
(bad code)
Example Language: Perl
my $num = GetUntrustedNumber(); my @messages = ();
$messages[$num] = "Hello World";
The index is not validated at all (CWE-129), so it might be possible for an attacker to modify an element in @messages that was not intended. If an index is used that is larger than the current size of the array, the Perl interpreter automatically expands the array so that the large index works.
If $num is a large value such as 2147483648 (1<<31), then the assignment to $messages[$num] would attempt to create a very large array, then eventually produce an error message such as:
Out of memory during array extend
This memory exhaustion will cause the Perl program to exit, possibly a denial of service. In addition, the lack of memory could also prevent many other programs from successfully running on the system.
Example 6
This example shows a typical attempt to parse a string with an error resulting from a difference in assumptions between the caller to a function and the function's action. The buffer length ends up being -1 resulting in a blown out stack. The space character after the colon is included in the function calculation, but not in the caller's calculation. This, unfortunately, is not usually so obvious but exists in an obtuse series of calculations.
(bad code)
Example Language: C
int proc_msg(char *s, int msg_len)
{
int pre_len = sizeof("preamble: "); // Note space at the end of the string - assume all strings have preamble with space
char buf[pre_len - msg_len];
... Do processing here and set status
return status;
}
char *s = "preamble: message\n";
char *sl = strchr(s, ':'); // Number of characters up to ':' (not including space)
int jnklen = sl == NULL ? 0 : sl - s; // If undefined pointer, use zero length
int ret_val = proc_msg ("s", jnklen); // Violate assumption of preamble length, end up with negative value, blow out stack
(good code)
Example Language: C
int proc_msg(char *s, int msg_len)
{
int pre_len = sizeof("preamble: "); // Note space at the end of the string - assume all strings have preamble with space
}
char *s = "preamble: message\n";
char *sl = strchr(s, ':'); // Number of characters up to ':' (not including space)
int jnklen = sl == NULL ? 0 : sl - s; // If undefined pointer, use zero length
int ret_val = proc_msg ("s", jnklen); // Violate assumption of preamble length, end up with negative value, blow out stack
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: Python library does not limit the resources used to process images that specify a very large number of bands (CWE-1284), leading to excessive memory consumption (CWE-789) or an integer overflow (CWE-190).
large Content-Length HTTP header value triggers application crash in instant messaging application due to failure in memory allocation
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
This weakness can be closely associated with integer overflows (CWE-190). Integer overflow attacks would concentrate on providing an extremely large number that triggers an overflow that causes less memory to be allocated than expected. By providing a large value that does not trigger an integer overflow, the attacker could still cause excessive amounts of memory to be allocated.
Applicable Platform
Uncontrolled memory allocation is possible in many languages, such as dynamic array allocation in perl or initial size parameters in Collections in Java. However, languages like C and C++ where programmers have the power to more directly control memory management will be more susceptible.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
WASC
35
SOAP Array Abuse
CERT C Secure Coding
MEM35-C
Imprecise
Allocate sufficient memory for an object
SEI CERT Perl Coding Standard
IDS32-PL
Imprecise
Validate any integer that is used as an array index
OMG ASCSM
ASCSM-CWE-789
References
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 10, "Resource Limits", Page 574. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product attempts to return a memory resource to the system, but it calls a release function that is not compatible with the function that was originally used to allocate that resource.
Extended Description
This weakness can be generally described as mismatching memory management routines, such as:
The memory was allocated on the stack (automatically), but it was deallocated using the memory management routine free() (CWE-590), which is intended for explicitly allocated heap memory.
The memory was allocated explicitly using one set of memory management functions, and deallocated using a different set. For example, memory might be allocated with malloc() in C++ instead of the new operator, and then deallocated with the delete operator.
When the memory management functions are mismatched, the consequences may be as severe as code execution, memory corruption, or program crash. Consequences and ease of exploit will vary depending on the implementation of the routines and the object being managed.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; DoS: Crash, Exit, or Restart; Execute Unauthorized Code or Commands
Scope: Integrity, Availability, Confidentiality
Potential Mitigations
Phase(s)
Mitigation
Implementation
Only call matching memory management functions. Do not mix and match routines. For example, when you allocate a buffer with malloc(), dispose of the original pointer with free().
Implementation
Strategy: Libraries or Frameworks
Choose a language or tool that provides automatic memory management, or makes manual memory management less error-prone.
For example, glibc in Linux provides protection against free of invalid pointers.
When using Xcode to target OS X or iOS, enable automatic reference counting (ARC) [REF-391].
To help correctly and consistently manage memory when programming in C++, consider using a smart pointer class such as std::auto_ptr (defined by ISO/IEC ISO/IEC 14882:2003), std::shared_ptr and std::unique_ptr (specified by an upcoming revision of the C++ standard, informally referred to as C++ 1x), or equivalent solutions such as Boost.
Architecture and Design
Strategy: Libraries or Frameworks
Use a vetted library or framework that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
For example, glibc in Linux provides protection against free of invalid pointers.
Architecture and Design
Use a language that provides abstractions for memory allocation and deallocation.
Testing
Use a tool that dynamically detects memory management problems, such as valgrind.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
Low
Demonstrative Examples
Example 1
This example allocates a BarObj object using the new operator in C++, however, the programmer then deallocates the object using free(), which may lead to unexpected behavior.
(bad code)
Example Language: C++
void foo(){
BarObj *ptr = new BarObj() /* do some work with ptr here */
...
free(ptr);
}
Instead, the programmer should have either created the object with one of the malloc family functions, or else deleted the object with the delete operator.
(good code)
Example Language: C++
void foo(){
BarObj *ptr = new BarObj() /* do some work with ptr here */
...
delete ptr;
}
Example 2
In this example, the program does not use matching functions such as malloc/free, new/delete, and new[]/delete[] to allocate/deallocate the resource.
(bad code)
Example Language: C++
class A {
void foo();
}; void A::foo(){
int *ptr; ptr = (int*)malloc(sizeof(int)); delete ptr;
}
Example 3
In this example, the program calls the delete[] function on non-heap memory.
(bad code)
Example Language: C++
class A{
void foo(bool);
}; void A::foo(bool heap) {
int localArray[2] = {
11,22
}; int *p = localArray; if (heap){
p = new int[2];
} delete[] p;
}
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Applicable Platform
This weakness is possible in any programming language that allows manual management of memory.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CERT C Secure Coding
WIN30-C
Exact
Properly pair allocation and deallocation functions
CWE-478: Missing Default Case in Multiple Condition Expression
Weakness ID: 478
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The code does not have a default case in an expression with multiple conditions, such as a switch statement.
Extended Description
If a multiple-condition expression (such as a switch in C) omits the default case but does not consider or handle all possible values that could occur, then this might lead to complex logical errors and resultant weaknesses. Because of this, further decisions are made based on poor information, and cascading failure results. This cascading failure may result in any number of security issues, and constitutes a significant failure in the system.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Varies by Context; Alter Execution Logic
Scope: Integrity
Depending on the logical circumstances involved, any consequences may result: e.g., issues of confidentiality, authentication, authorization, availability, integrity, accountability, or non-repudiation.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Ensure that there are no cases unaccounted for when adjusting program flow or values based on the value of a given variable. In the case of switch style statements, the very simple act of creating a default case can, if done correctly, mitigate this situation. Often however, the default case is used simply to represent an assumed option, as opposed to working as a check for invalid input. This is poor practice and in some cases is as bad as omitting a default case entirely.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Python
(Undetermined Prevalence)
JavaScript
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The following does not properly check the return code in the case where the security_check function returns a -1 value when an error occurs. If an attacker can supply data that will invoke an error, the attacker can bypass the security check:
(bad code)
Example Language: C
#define FAILED 0 #define PASSED 1 int result; ... result = security_check(data); switch (result) {
case FAILED:
printf("Security check failed!\n"); exit(-1); //Break never reached because of exit() break;
case PASSED:
printf("Security check passed.\n"); break;
} // program execution continues... ...
Instead a default label should be used for unaccounted conditions:
(good code)
Example Language: C
#define FAILED 0 #define PASSED 1 int result; ... result = security_check(data); switch (result) {
case FAILED:
printf("Security check failed!\n"); exit(-1); //Break never reached because of exit() break;
This label is used because the assumption cannot be made that all possible cases are accounted for. A good practice is to reserve the default case for error handling.
Example 2
In the following Java example the method getInterestRate retrieves the interest rate for the number of points for a mortgage. The number of points is provided within the input parameter and a switch statement will set the interest rate value to be returned based on the number of points.
(bad code)
Example Language: Java
public static final String INTEREST_RATE_AT_ZERO_POINTS = "5.00"; public static final String INTEREST_RATE_AT_ONE_POINTS = "4.75"; public static final String INTEREST_RATE_AT_TWO_POINTS = "4.50"; ... public BigDecimal getInterestRate(int points) {
BigDecimal result = new BigDecimal(INTEREST_RATE_AT_ZERO_POINTS);
switch (points) {
case 0:
result = new BigDecimal(INTEREST_RATE_AT_ZERO_POINTS); break;
case 1:
result = new BigDecimal(INTEREST_RATE_AT_ONE_POINTS); break;
case 2:
result = new BigDecimal(INTEREST_RATE_AT_TWO_POINTS); break;
} return result;
}
However, this code assumes that the value of the points input parameter will always be 0, 1 or 2 and does not check for other incorrect values passed to the method. This can be easily accomplished by providing a default label in the switch statement that outputs an error message indicating an invalid value for the points input parameter and returning a null value.
(good code)
Example Language: Java
public static final String INTEREST_RATE_AT_ZERO_POINTS = "5.00"; public static final String INTEREST_RATE_AT_ONE_POINTS = "4.75"; public static final String INTEREST_RATE_AT_TWO_POINTS = "4.50"; ... public BigDecimal getInterestRate(int points) {
BigDecimal result = new BigDecimal(INTEREST_RATE_AT_ZERO_POINTS);
switch (points) {
case 0:
result = new BigDecimal(INTEREST_RATE_AT_ZERO_POINTS); break;
case 1:
result = new BigDecimal(INTEREST_RATE_AT_ONE_POINTS); break;
case 2:
result = new BigDecimal(INTEREST_RATE_AT_TWO_POINTS); break;
default:
System.err.println("Invalid value for points, must be 0, 1 or 2"); System.err.println("Returning null value for interest rate"); result = null;
}
return result;
}
Example 3
In the following Python example the match-case statements (available in Python version 3.10 and later) perform actions based on the result of the process_data() function. The expected return is either 0 or 1. However, if an unexpected result (e.g., -1 or 2) is obtained then no actions will be taken potentially leading to an unexpected program state.
(bad code)
Example Language: Python
result = process_data(data)
match result:
case 0:
print("Properly handle zero case.")
case 1:
print("Properly handle one case.")
# program execution continues...
The recommended approach is to add a default case that captures any unexpected result conditions, regardless of how improbable these unexpected conditions might be, and properly handles them.
(good code)
Example Language: Python
result = process_data(data)
match result:
case 0:
print("Properly handle zero case.")
case 1:
print("Properly handle one case.")
case _:
print("Properly handle unexpected condition.")
# program execution continues...
Example 4
In the following JavaScript example the switch-case statements (available in JavaScript version 1.2 and later) are used to process a given step based on the result of a calcuation involving two inputs. The expected return is either 1, 2, or 3. However, if an unexpected result (e.g., 4) is obtained then no action will be taken potentially leading to an unexpected program state.
(bad code)
Example Language: JavaScript
let step = input1 + input2;
switch(step) {
case 1:
alert("Process step 1.");
break;
case 2:
alert("Process step 2.");
break;
case 3:
alert("Process step 3.");
break;
}
// program execution continues...
The recommended approach is to add a default case that captures any unexpected result conditions and properly handles them.
(good code)
Example Language: JavaScript
let step = input1 + input2;
switch(step) {
case 1:
alert("Process step 1.");
break;
case 2:
alert("Process step 2.");
break;
case 3:
alert("Process step 3.");
break;
default:
alert("Unexpected step encountered.");
}
// program execution continues...
Example 5
The Finite State Machine (FSM) shown in the "bad" code snippet below assigns the output ("out") based on the value of state, which is determined based on the user provided input ("user_input").
3'h0:
3'h1:
3'h2:
3'h3: state = 2'h3;
3'h4: state = 2'h2;
3'h5: state = 2'h1;
endcase
end
out <= {1'h1, state};
endmodule
The case statement does not include a default to handle the scenario when the user provides inputs of 3'h6 and 3'h7. Those inputs push the system to an undefined state and might cause a crash (denial of service) or any other unanticipated outcome.
Adding a default statement to handle undefined inputs mitigates this issue. This is shown in the "Good" code snippet below. The default statement is in bold.
(good code)
Example Language: Verilog
case (user_input)
3'h0:
3'h1:
3'h2:
3'h3: state = 2'h3;
3'h4: state = 2'h2;
3'h5: state = 2'h1;
default: state = 2'h0;
endcase
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 7, "Switch Statements", Page 337. 1st Edition. Addison Wesley. 2006.
Content
History
Submissions
Submission Date
Submitter
Organization
2006-07-19
(CWE Draft 3, 2006-07-19)
CLASP
Contributions
Contribution Date
Contributor
Organization
2022-08-15
Drew Buttner
MITRE
Suggested name change and other modifications, including a new demonstrative example.
CWE-401: Missing Release of Memory after Effective Lifetime
Weakness ID: 401
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product does not sufficiently track and release allocated memory after it has been used, making the memory unavailable for reallocation and reuse.
Alternate Terms
Memory Leak
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Most memory leaks result in general product reliability problems, but if an attacker can intentionally trigger a memory leak, the attacker might be able to launch a denial of service attack (by crashing or hanging the program) or take advantage of other unexpected program behavior resulting from a low memory condition.
Reduce Performance
Scope: Other
Potential Mitigations
Phase(s)
Mitigation
Implementation
Strategy: Libraries or Frameworks
Choose a language or tool that provides automatic memory management, or makes manual memory management less error-prone.
For example, glibc in Linux provides protection against free of invalid pointers.
When using Xcode to target OS X or iOS, enable automatic reference counting (ARC) [REF-391].
To help correctly and consistently manage memory when programming in C++, consider using a smart pointer class such as std::auto_ptr (defined by ISO/IEC ISO/IEC 14882:2003), std::shared_ptr and std::unique_ptr (specified by an upcoming revision of the C++ standard, informally referred to as C++ 1x), or equivalent solutions such as Boost.
Architecture and Design
Use an abstraction library to abstract away risky APIs. Not a complete solution.
Architecture and Design; Build and Compilation
The Boehm-Demers-Weiser Garbage Collector or valgrind can be used to detect leaks in code.
Note: This is not a complete solution as it is not 100% effective.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Missing Release of Resource after Effective Lifetime
CanFollow
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Memory leaks have two common and sometimes overlapping causes:
Error conditions and other exceptional circumstances often triggered by improper handling of malformed data or unexpectedly interrupted sessions.
Confusion over which part of the program is responsible for freeing the memory, since in some languages, developers are responsible for tracking memory allocation and releasing the memory. If there are no more pointers or references to the memory, then it can no longer be tracked and identified for release.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
The following C function leaks a block of allocated memory if the call to read() does not return the expected number of bytes:
(bad code)
Example Language: C
char* getBlock(int fd) {
char* buf = (char*) malloc(BLOCK_SIZE); if (!buf) {
return NULL;
} if (read(fd, buf, BLOCK_SIZE) != BLOCK_SIZE) {
return NULL;
} return buf;
}
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
(where the weakness is typically related to the presence of some other weaknesses)
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Functional Areas
Memory Management
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
This is often a resultant weakness due to improper handling of malformed data or early termination of sessions.
Terminology
"memory leak" has sometimes been used to describe other kinds of issues, e.g. for information leaks in which the contents of memory are inadvertently leaked (CVE-2003-0400 is one such example of this terminology conflict).
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Memory leak
7 Pernicious Kingdoms
Memory Leak
CLASP
Failure to deallocate data
OWASP Top Ten 2004
A9
CWE More Specific
Denial of Service
CERT C Secure Coding
MEM31-C
Exact
Free dynamically allocated memory when no longer needed
The CERT Oracle Secure Coding Standard for Java (2011)
CWE-1429: Missing Security-Relevant Feedback for Unexecuted Operations in Hardware Interface
Weakness ID: 1429
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product has a hardware interface that silently discards operations
in situations for which feedback would be security-relevant, such as
the timely detection of failures or attacks.
Extended Description
While some systems intentionally withhold feedback as a security
measure, this approach must be strictly controlled to ensure it does
not obscure operational failures that require prompt detection and
remediation. Without these essential confirmations, failures go
undetected, increasing the risk of data loss, security
vulnerabilities, and overall system instability. Even when withholding
feedback is an intentional part of a security policy designed, for
example, to prevent attackers from gleaning sensitive internal
details, the absence of expected feedback becomes a critical weakness
when it masks operational failures that require prompt detection and
remediation.
For instance, certain encryption algorithms always return ciphertext
regardless of errors to prevent attackers from gaining insight into
internal state details. However, if such an algorithm fails to
generate the expected ciphertext and provides no error feedback, the
system cannot distinguish between a legitimate output and a
malfunction. This can lead to undetected cryptographic failures,
potentially compromising data security and system reliability. Without
proper notification, a critical failure might remain hidden,
undermining both the reliability and security of the process.
Therefore, this weakness captures issues across various hardware
interfaces where operations are discarded without any feedback, error
handling, or logging. Such omissions can lead to data loss, security
vulnerabilities, and system instability, with potential impacts
ranging from minor to catastrophic.
For some kinds of hardware products, some errors may be correctly
identified and subsequently discarded, and the lack of feedback may
have been an intentional design decision. However, this could result
in a weakness if system operators or other authorized entities are not
provided feedback about security-critical operations or failures that
could prevent the operators from detecting and responding to an
attack.
For example:
In a System-on-Chip (SoC) platform, write operations to reserved
memory addresses might be correctly identified as invalid and
subsequently discarded. However, if no feedback is provided to
system operators, they may misinterpret the device's state, failing
to recognize conditions that could lead to broader failures or
security vulnerabilities. For example, if an attacker attempts
unauthorized writes to protected regions, the system may silently
discard these writes without alerting security mechanisms. This lack
of feedback could obscure intrusion attempts or misconfigurations,
increasing the risk of unnoticed system compromise
Microcontroller Interrupt Systems: When interrupts are silently
ignored due to priority conflicts or internal errors without
notifying higher-level control, it becomes challenging to diagnose
system failures or detect potential security breaches in a timely
manner.
Network Interface Controllers: Dropping packets - perhaps due to
buffer overflows - without any error feedback can not only cause data
loss but may also contribute to exploitable timing discrepancies
that reveal sensitive internal processing details.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory; Read Files or Directories
Scope: ConfidentialityLikelihood: Medium
Critical data may be exposed if operations are unexecuted or
discarded silently, allowing attackers to exploit the lack of
feedback.
Modify Memory; Modify Files or Directories
Scope: IntegrityLikelihood: Medium
Operations may proceed based on incorrect assumptions,
potentially causing data corruption or incorrect system behavior. In
integrity-sensitive contexts, failing to signal that an operation did
not occur as expected can mask errors that disrupt data
consistency. Without feedback, the mitigation measures that should
ensure updates have been performed cannot be verified, leaving the
system vulnerable to both accidental and malicious data alterations
DoS: Resource Consumption (Memory); DoS: Crash, Exit, or Restart
Scope: AvailabilityLikelihood: High
Unhandled discarded operations can lead to resource exhaustion,
triggering system crashes or denial of service. For availability,
consistent feedback is crucial. Without proper notification of
discarded operations, administrators or other authorized entities
might miss early warning signs of resource imbalances. This delayed
detection could allow a DoS condition to develop, compromising the
system's ability to serve legitimate requests and maintain continuous
operations.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Incorporate logging and feedback mechanisms during the
design phase to ensure proper handling of discarded operations.
Effectiveness: High
Note:
Addressing the issue at the design stage prevents
the weakness from manifesting later.
Implementation
Developers should ensure that every critical operation
includes proper logging or error feedback mechanisms.
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Architecture and Design
This weakness can be introduced during the architecture and
design phase when the system does not incorporate proper mechanisms
for error reporting or feedback for discarded operations, such as when
handling reserved addresses or unexecuted instructions.
Implementation
It can also arise during implementation if developers fail to
include appropriate feedback or logging for critical operations. This
leads to silent failures in certain scenarios like interrupt handling
or network buffer overflows.
Requirements
A further layer of complexity emerges when considering
specifications. The weakness may stem either from ambiguous product
design specifications that fail to delineate when feedback should
occur or from implementations that do not adhere to existing
requirements. In either case, the result is the same: feedback that is
critical for detecting operational failures or security breaches is
missing.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Verilog
(Undetermined Prevalence)
Class: Hardware Description Language
(Undetermined Prevalence)
Class: Not Language-Specific
(Undetermined Prevalence)
This code creates an interrupt handler. If the interrupt's priority
is lower than the currently active one, the interrupt is discarded
without any feedback, perhaps due to resource constraints.
(bad code)
Example Language: C
void interrupt_handler(int irq) {
if (irq_priority[irq] < current_priority) {
return;
}
process_interrupt(irq);
}
The omission of feedback for the dropped lower-priority interrupt can
cause developers to misinterpret the state of the system, leading to
incorrect assumptions and potential system failures, such as missed
sensor readings.
Attackers might leverage this lack of visibility to induce conditions
that lead to timing side-channels. For example, an attacker could
intentionally flood the system with high-priority interrupts, forcing
the system to discard lower-priority interrupts consistently. If these
discarded interrupts correspond to processes executing critical
security functions (e.g., cryptographic key handling), an attacker
might measure system timing variations to infer when and how those
functions are executing. This creates a timing side channel that could
be used to extract sensitive information. Moreover, since these
lower-priority interrupts are not reported, the system remains unaware
that critical tasks such as sensor data collection or maintenance
routines, are being starved of execution. Over time, this can lead to
functional failures or watchdog time resets in real-time systems.
One way to address this problem could be to use structured logging to
provide visibility into discarded interrupts. This allows
administrators, developers, or other authorized entities to track
missed interrupts and optimize the system.
(good code)
Example Language: C
// Priority threshold for active interrupts
int current_priority = 3;
// Simulated priority levels for different IRQs
int irq_priority[5] = {1, 2, 3, 4, 5};
void process_interrupt(int irq) {
printf("Processing interrupt %d\n", irq);
}
void interrupt_handler(int irq) {
if (irq_priority[irq] < current_priority) {
// Log the dropped interrupt using structured feedback
fprintf(stderr, "Warning: Interrupt %d dropped (Priority: %d < Current: %d)\n",
irq, irq_priority[irq], current_priority);
exit(EXIT_FAILURE); // Exit with failure status to indicate a critical issue.
}
process_interrupt(irq);
}
Example 2
Consider a SoC design with these component IPs:
IP 1. Execution Core <--> IP 2 SoC Fabric (NoC, tile etc. ) <--> IP 3 Memory Controller <--> External/ internal memory.
The Core executes operations that trigger transactions that traverse
the HW fabric links to read/write to the final memory module.
There can be unexpected errors in each link. For adding reliability
and redundance, features like ECCs are used in these
transactions. Error correction capabilities have to define how many
error bits can be detected and which errors can be corrected, and
which are uncorrectable errors. In design, often the severity level
and response on different errors is allowed to be configured by system
firmware modules like BIOS.
(bad code)
If an uncorrectable error occurs, the design does not explicitly
trigger an alert back to the execution core.
For system security, if an uncorrectable error occurs but is not
reported to the execution core and handled before the core attempts to
consume the data that is read/written through the corrupted
transactions, then this could enable silent data corruption (SDC)
attacks.
In the case of confidential compute technologies where system firmware
is not a trusted component, error handling controls can be
misconfigured to trigger this weakness and attack the assets protected
by confidential compute.
(good code)
Modify the design so that any uncorrectable error triggers an alert
back to the execution core and gets handled before the core can
consume the data read/written through the corrupted transactions.
Update design access control policies to ensure that alerts sent to
execution core on uncorrectable errors cannot be disabled or masked by
untrusted software/firmware.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Reference
Description
Open source silicon root of trust (RoT) product does not immediately report when an integrity check fails for memory requests, causing the product to accept and continue processing data [REF-1468]
Detection
Methods
Method
Details
Automated Static Analysis - Source Code
Scans code for missing error handling or feedback mechanisms.
Effectiveness: High
Note:
This identify common issues early in the development phase.
Manual Static Analysis - Source Code
Experts manually inspect the code for unhandled operations.
Effectiveness: Moderate
Note:
Useful for identifying design-level omissions.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
CWE-1341: Multiple Releases of Same Resource or Handle
Weakness ID: 1341
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product attempts to close or release a resource or handle more than once, without any successful open between the close operations.
Extended Description
Code typically requires "opening" handles or references to resources such as memory, files, devices, socket connections, services, etc. When the code is finished with using the resource, it is typically expected to "close" or "release" the resource, which indicates to the environment (such as the OS) that the resource can be re-assigned or reused by unrelated processes or actors - or in some cases, within the same process. API functions or other abstractions are often used to perform this release, such as free() or delete() within C/C++, or file-handle close() operations that are used in many languages.
Unfortunately, the implementation or design of such APIs might expect the developer to be responsible for ensuring that such APIs are only called once per release of the resource. If the developer attempts to release the same resource/handle more than once, then the API's expectations are not met, resulting in undefined and/or insecure behavior. This could lead to consequences such as memory corruption, data corruption, execution path corruption, or other consequences.
Note that while the implementation for most (if not all) resource reservation allocations involve a unique identifier/pointer/symbolic reference, then if this identifier is reused, checking the identifier for resource closure may result in a false state of openness and closing of the wrong resource. For this reason, reuse of identifiers is discouraged.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
DoS: Crash, Exit, or Restart
Scope: Availability, IntegrityLikelihood: Medium
Potential Mitigations
Phase(s)
Mitigation
Implementation
Change the code's logic so that the resource is only closed once. This might require simplifying or refactoring. This fix can be simple to do in small code blocks, but more difficult when multiple closes are buried within complex conditionals.
Implementation
Strategy: Refactoring
It can be effective to implement a flag that is (1) set when the resource is opened, (2) cleared when it is closed, and (3) checked before closing. This approach can be useful when there are disparate cases in which closes must be performed. However, flag-tracking can increase code complexity and requires diligent compliance by the programmer.
Implementation
Strategy: Refactoring
When closing a resource, set the resource's associated variable to NULL or equivalent value for the given language. Some APIs will ignore this null value without causing errors. For other APIs, this can lead to application crashes or exceptions, which may still be preferable to corrupting an unintended resource such as memory or data.
Effectiveness: Defense in Depth
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Multiple Operations on Resource in Single-Operation Context
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
Java
(Undetermined Prevalence)
Rust
(Undetermined Prevalence)
Class: Not Language-Specific
(Undetermined Prevalence)
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Operating Systems
Class: Not OS-Specific
(Undetermined Prevalence)
Architectures
Class: Not Architecture-Specific
(Undetermined Prevalence)
Technologies
Class: Not Technology-Specific
(Undetermined Prevalence)
Demonstrative Examples
Example 1
This example attempts to close a file twice. In some cases, the C library fclose() function will catch the error and return an error code. In other implementations, a double-free (CWE-415) occurs, causing the program to fault. Note that the examples presented here are simplistic, and double fclose() calls will frequently be spread around a program, making them more difficult to find during code reviews.
(bad code)
Example Language: C
char b[2000];
FILE *f = fopen("dbl_cls.c", "r");
if (f)
{
b[0] = 0;
fread(b, 1, sizeof(b) - 1, f);
printf("%s\n'", b);
int r1 = fclose(f);
printf("\n-----------------\n1 close done '%d'\n", r1);
int r2 = fclose(f); // Double close
printf("2 close done '%d'\n", r2);
}
There are multiple possible fixes. This fix only has one call to fclose(), which is typically the preferred handling of this problem - but this simplistic method is not always possible.
(good code)
Example Language: C
char b[2000];
FILE *f = fopen("dbl_cls.c", "r");
if (f)
{
b[0] = 0;
fread(b, 1, sizeof(b) - 1, f);
printf("%s\n'", b);
int r = fclose(f);
printf("\n-----------------\n1 close done '%d'\n", r);
}
This fix uses a flag to call fclose() only once. Note that this flag is explicit. The variable "f" could also have been used as it will be either NULL if the file is not able to be opened or a valid pointer if the file was successfully opened. If "f" is replacing "f_flg" then "f" would need to be set to NULL after the first fclose() call so the second fclose call would never be executed.
(good code)
Example Language: C
char b[2000];
int f_flg = 0;
FILE *f = fopen("dbl_cls.c", "r");
if (f)
{
int r1 = fclose(f);
f_flg = 0;
printf("\n-----------------\n1 close done '%d'\n", r1);
}
if (f_flg)
{
int r2 = fclose(f); // Double close
f_flg = 0;
printf("2 close done '%d'\n", r2);
}
}
Example 2
The following code shows a simple example of a double free vulnerability.
(bad code)
Example Language: C
char* ptr = (char*)malloc (SIZE); ... if (abrt) {
free(ptr);
} ... free(ptr);
Double free vulnerabilities have two common (and sometimes overlapping) causes:
Error conditions and other exceptional circumstances
Confusion over which part of the program is responsible for freeing the memory
Although some double free vulnerabilities are not much more complicated than this example, most are spread out across hundreds of lines of code or even different files. Programmers seem particularly susceptible to freeing global variables more than once.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Double free resultant from certain error conditions.
Detection
Methods
Method
Details
Automated Static Analysis
For commonly-used APIs and resource types, automated tools often have signatures that can spot this issue.
Automated Dynamic Analysis
Some compiler instrumentation tools such as AddressSanitizer (ASan) can indirectly detect some instances of this weakness.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Terminology
The terms related to "release" may vary depending on the type of resource, programming language, specification, or framework. "Close" has been used synonymously for the release of resources like file descriptors and file handles. "Return" is sometimes used instead of Release. "Free" is typically used when releasing memory or buffers back into the system for reuse.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product dereferences a pointer that it expects to be valid but is NULL.
Alternate Terms
NPD
Common abbreviation for Null Pointer Dereference
null deref
Common abbreviation for Null Pointer Dereference
NPE
Common abbreviation for Null Pointer Exception
nil pointer dereference
used for access of nil in Go programs
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
DoS: Crash, Exit, or Restart
Scope: Availability
NULL pointer dereferences usually result in the failure of the process unless exception handling (on some platforms) is available and implemented. Even when exception handling is being used, it can still be very difficult to return the software to a safe state of operation.
Execute Unauthorized Code or Commands; Read Memory; Modify Memory
Scope: Integrity, Confidentiality
In rare circumstances, when NULL is equivalent to the 0x0 memory address and privileged code can access it, then writing or reading memory is possible, which may lead to code execution.
Potential Mitigations
Phase(s)
Mitigation
Implementation
For any pointers that could have been modified or provided from a function that can return NULL, check the pointer for NULL before use. When working with a multithreaded or otherwise asynchronous environment, ensure that proper locking APIs are used to lock before the check, and unlock when it has finished.
Requirements
Select a programming language that is not susceptible to these issues.
Implementation
Check the results of all functions that return a value and verify that the value is non-null before acting upon it.
Effectiveness: Moderate
Note: Checking the return value of the function will typically be sufficient, however beware of race conditions (CWE-362) in a concurrent environment. This solution does not handle the use of improperly initialized variables (CWE-665).
Architecture and Design
Identify all variables and data stores that receive information from external sources, and apply input validation to make sure that they are only initialized to expected values.
Implementation
Explicitly initialize all variables and other data stores, either during declaration or just before the first usage.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Check for Unusual or Exceptional Conditions
CanFollow
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Concurrent Execution using Shared Resource with Improper Synchronization ('Race Condition')
CanFollow
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Check for Unusual or Exceptional Conditions
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Go
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
This example takes an IP address from a user, verifies that it is well formed and then looks up the hostname and copies it into a buffer.
If an attacker provides an address that appears to be well-formed, but the address does not resolve to a hostname, then the call to gethostbyaddr() will return NULL. Since the code does not check the return value from gethostbyaddr (CWE-252), a NULL pointer dereference (CWE-476) would then occur in the call to strcpy().
Note that this code is also vulnerable to a buffer overflow (CWE-119).
Example 2
In the following code, the programmer assumes that the system always has a property named "cmd" defined. If an attacker can control the program's environment so that "cmd" is not defined, the program throws a NULL pointer exception when it attempts to call the trim() method.
String URL = intent.getStringExtra("URLToOpen"); int length = URL.length();
... }
}
}
The application assumes the URL will always be included in the intent. When the URL is not present, the call to getStringExtra() will return null, thus causing a null pointer exception when length() is called.
Example 4
Consider the following example of a typical client server exchange. The HandleRequest function is intended to perform a request and use a defer to close the connection whenever the function returns.
If a user supplies a malformed request or violates the client policy, the Do method can return a nil response and a non-nil err.
This HandleRequest Function evaluates the close before checking the error. A deferred call's arguments are evaluated immediately, so the defer statement panics due to a nil response.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
race condition causes a table to be corrupted if a timer activates while it is being modified, leading to resultant NULL dereference; also involves locking.
Chain: Use of an unimplemented network socket operation pointing to an uninitialized handler function (CWE-456) causes a crash because of a null pointer dereference (CWE-476).
Chain: The return value of a function returning a pointer is not checked for success (CWE-252) resulting in the later use of an uninitialized variable (CWE-456) and a null pointer dereference (CWE-476)
Chain: a message having an unknown message type may cause a reference to uninitialized memory resulting in a null pointer dereference (CWE-476) or dangling pointer (CWE-825), possibly crashing the system or causing heap corruption.
Chat client allows remote attackers to cause a denial of service (crash) via a passive DCC request with an invalid ID number, which causes a null dereference.
OS allows remote attackers to cause a denial of service (crash from null dereference) or execute arbitrary code via a crafted request during authentication protocol selection.
Network monitor allows remote attackers to cause a denial of service (crash) or execute arbitrary code via malformed packets that cause a NULL pointer dereference.
Chain: System call returns wrong value (CWE-393), leading to a resultant NULL dereference (CWE-476).
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
NULL pointer dereferences are frequently resultant from rarely encountered error conditions and race conditions, since these are most likely to escape detection during the testing phases.
Detection
Methods
Method
Details
Automated Dynamic Analysis
This weakness can be detected using dynamic tools and techniques that interact with the software using large test suites with many diverse inputs, such as fuzz testing (fuzzing), robustness testing, and fault injection. The software's operation may slow down, but it should not become unstable, crash, or generate incorrect results.
Effectiveness: Moderate
Manual Dynamic Analysis
Identify error conditions that are not likely to occur during normal usage and trigger them. For example, run the program under low memory conditions, run with insufficient privileges or permissions, interrupt a transaction before it is completed, or disable connectivity to basic network services such as DNS. Monitor the software for any unexpected behavior. If you trigger an unhandled exception or similar error that was discovered and handled by the application's environment, it may still indicate unexpected conditions that were not handled by the application itself.
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 08 - Memory Management (MEM)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
SEI CERT C Coding Standard - Guidelines 03. Expressions (EXP)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2021 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2020 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2023 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2024 CWE Top 25 Most Dangerous Software Weaknesses
Vulnerability Mapping Notes
Usage
ALLOWED
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
CWE-839: Numeric Range Comparison Without Minimum Check
Weakness ID: 839
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product checks a value to ensure that it is less than or equal to a maximum, but it does not also verify that the value is greater than or equal to the minimum.
Extended Description
Some products use signed integers or floats even when their values are only expected to be positive or 0. An input validation check might assume that the value is positive, and only check for the maximum value. If the value is negative, but the code assumes that the value is positive, this can produce an error. The error may have security consequences if the negative value is used for memory allocation, array access, buffer access, etc. Ultimately, the error could lead to a buffer overflow or other type of memory corruption.
The use of a negative number in a positive-only context could have security implications for other types of resources. For example, a shopping cart might check that the user is not requesting more than 10 items, but a request for -3 items could cause the application to calculate a negative price and credit the attacker's account.
Alternate Terms
Signed comparison
The "signed comparison" term is often used to describe when the product uses a signed variable and checks it to ensure that it is less than a maximum value (typically a maximum buffer size), but does not verify that it is greater than 0.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Application Data; Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
An attacker could modify the structure of the message or data being sent to the downstream component, possibly injecting commands.
DoS: Resource Consumption (Other)
Scope: Availability
in some contexts, a negative value could lead to resource consumption.
Modify Memory; Read Memory
Scope: Confidentiality, Integrity
If a negative value is used to access memory, buffers, or other indexable structures, it could access memory outside the bounds of the buffer.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Strategy: Enforcement by Conversion
If the number to be used is always expected to be positive, change the variable type from signed to unsigned or size_t.
Implementation
Strategy: Input Validation
If the number to be used could have a negative value based on the specification (thus requiring a signed value), but the number should only be positive to preserve code correctness, then include a check to ensure that the value is positive.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
CanPrecede
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Demonstrative Examples
Example 1
The following code is intended to read an incoming packet from a socket and extract one or more headers.
(bad code)
Example Language: C
DataPacket *packet; int numHeaders; PacketHeader *headers;
The code performs a check to make sure that the packet does not contain too many headers. However, numHeaders is defined as a signed int, so it could be negative. If the incoming packet specifies a value such as -3, then the malloc calculation will generate a negative number (say, -300 if each header can be a maximum of 100 bytes). When this result is provided to malloc(), it is first converted to a size_t type. This conversion then produces a large value such as 4294966996, which may cause malloc() to fail or to allocate an extremely large amount of memory (CWE-195). With the appropriate negative numbers, an attacker could trick malloc() into using a very small positive number, which then allocates a buffer that is much smaller than expected, potentially leading to a buffer overflow.
Example 2
The following code reads a maximum size and performs a sanity check on that size. It then performs a strncpy, assuming it will not exceed the boundaries of the array. While the use of "short s" is forced in this particular example, short int's are frequently used within real-world code, such as code that processes structured data.
(bad code)
Example Language: C
int GetUntrustedInt () {
return(0x0000FFFF);
}
void main (int argc, char **argv) {
char path[256]; char *input; int i; short s; unsigned int sz;
i = GetUntrustedInt(); s = i; /* s is -1 so it passes the safety check - CWE-697 */ if (s > 256) {
DiePainfully("go away!\n");
}
/* s is sign-extended and saved in sz */ sz = s;
/* output: i=65535, s=-1, sz=4294967295 - your mileage may vary */ printf("i=%d, s=%d, sz=%u\n", i, s, sz);
input = GetUserInput("Enter pathname:");
/* strncpy interprets s as unsigned int, so it's treated as MAX_INT (CWE-195), enabling buffer overflow (CWE-119) */ strncpy(path, input, s); path[255] = '\0'; /* don't want CWE-170 */ printf("Path is: %s\n", path);
}
This code first exhibits an example of CWE-839, allowing "s" to be a negative number. When the negative short "s" is converted to an unsigned integer, it becomes an extremely large positive integer. When this converted integer is used by strncpy() it will lead to a buffer overflow (CWE-119).
Example 3
In the following code, the method retrieves a value from an array at a specific array index location that is given as an input parameter to the method
(bad code)
Example Language: C
int getValueFromArray(int *array, int len, int index) {
int value;
// check that the array index is less than the maximum
// length of the array if (index < len) {
// get the value at the specified index of the array value = array[index];
} // if array index is invalid then output error message
// and return value indicating error else {
printf("Value is: %d\n", array[index]); value = -1;
}
return value;
}
However, this method only verifies that the given array index is less than the maximum length of the array but does not check for the minimum value (CWE-839). This will allow a negative value to be accepted as the input array index, which will result in a out of bounds read (CWE-125) and may allow access to sensitive memory. The input array index should be checked to verify that is within the maximum and minimum range required for the array (CWE-129). In this example the if statement should be modified to include a minimum range check, as shown below.
(good code)
Example Language: C
...
// check that the array index is within the correct
// range of values for the array if (index >= 0 && index < len) {
...
Example 4
The following code shows a simple BankAccount class with deposit and withdraw methods.
(bad code)
Example Language: Java
public class BankAccount {
public final int MAXIMUM_WITHDRAWAL_LIMIT = 350;
// variable for bank account balance private double accountBalance;
// constructor for BankAccount public BankAccount() {
accountBalance = 0;
}
// method to deposit amount into BankAccount public void deposit(double depositAmount) {...}
// method to withdraw amount from BankAccount public void withdraw(double withdrawAmount) {
System.err.println("Withdrawal amount exceeds the maximum limit allowed, please try again..."); ...
}
}
// other methods for accessing the BankAccount object ...
}
The withdraw method includes a check to ensure that the withdrawal amount does not exceed the maximum limit allowed, however the method does not check to ensure that the withdrawal amount is greater than a minimum value (CWE-129). Performing a range check on a value that does not include a minimum check can have significant security implications, in this case not including a minimum range check can allow a negative value to be used which would cause the financial application using this class to deposit money into the user account rather than withdrawing. In this example the if statement should the modified to include a minimum range check, as shown below.
(good code)
Example Language: Java
public class BankAccount {
public final int MINIMUM_WITHDRAWAL_LIMIT = 0; public final int MAXIMUM_WITHDRAWAL_LIMIT = 350;
...
// method to withdraw amount from BankAccount public void withdraw(double withdrawAmount) {
if (withdrawAmount < MAXIMUM_WITHDRAWAL_LIMIT && withdrawAmount > MINIMUM_WITHDRAWAL_LIMIT) {
...
Note that this example does not protect against concurrent access to the BankAccount balance variable, see CWE-413 and CWE-362.
While it is out of scope for this example, note that the use of doubles or floats in financial calculations may be subject to certain kinds of attacks where attackers use rounding errors to steal money.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: integer overflow (CWE-190) causes a negative signed value, which later bypasses a maximum-only check (CWE-839), leading to heap-based buffer overflow (CWE-122).
chain: negative ID in media player bypasses check for maximum index, then used as an array index for buffer under-read.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
References
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 6, "Type Conversion Vulnerabilities" Page 246. 1st Edition. Addison Wesley. 2006.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 6, "Comparisons", Page 265. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
Truncation errors occur when a primitive is cast to a primitive of a smaller size and data is lost in the conversion.
Extended Description
When a primitive is cast to a smaller primitive, the high order bits of the large value are lost in the conversion, potentially resulting in an unexpected value that is not equal to the original value. This value may be required as an index into a buffer, a loop iterator, or simply necessary state data. In any case, the value cannot be trusted and the system will be in an undefined state. While this method may be employed viably to isolate the low bits of a value, this usage is rare, and truncation usually implies that an implementation error has occurred.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory
Scope: Integrity
The true value of the data is lost and corrupted data is used.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Ensure that no casts, implicit or explicit, take place that move from a larger size primitive or a smaller size primitive.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Likelihood Of Exploit
Low
Demonstrative Examples
Example 1
This example, while not exploitable, shows the possible mangling of values associated with truncation errors:
The above code, when compiled and run on certain systems, returns the following output:
(result)
Int MAXINT: 2147483647 Short MAXINT: -1
This problem may be exploitable when the truncated value is used as an array index, which can happen implicitly when 64-bit values are used as indexes, as they are truncated to 32 bits.
Example 2
In the following Java example, the method updateSalesForProduct is part of a business application class that updates the sales information for a particular product. The method receives as arguments the product ID and the integer amount sold. The product ID is used to retrieve the total product count from an inventory object which returns the count as an integer. Before calling the method of the sales object to update the sales count the integer values are converted to The primitive type short since the method requires short type for the method arguments.
(bad code)
Example Language: Java
... // update sales database for number of product sold with product ID public void updateSalesForProduct(String productID, int amountSold) {
// get the total number of products in inventory database int productCount = inventory.getProductCount(productID); // convert integer values to short, the method for the
// sales object requires the parameters to be of type short short count = (short) productCount; short sold = (short) amountSold; // update sales database for product sales.updateSalesCount(productID, count, sold);
} ...
However, a numeric truncation error can occur if the integer values are higher than the maximum value allowed for the primitive type short. This can cause unexpected results or loss or corruption of data. In this case the sales database may be corrupted with incorrect data. Explicit casting from a from a larger size primitive type to a smaller size primitive type should be prevented. The following example an if statement is added to validate that the integer values less than the maximum value for the primitive type short before the explicit cast and the call to the sales method.
(good code)
Example Language: Java
... // update sales database for number of product sold with product ID public void updateSalesForProduct(String productID, int amountSold) {
// get the total number of products in inventory database int productCount = inventory.getProductCount(productID); // make sure that integer numbers are not greater than
// maximum value for type short before converting if ((productCount < Short.MAX_VALUE) && (amountSold < Short.MAX_VALUE)) {
// convert integer values to short, the method for the
// sales object requires the parameters to be of type short short count = (short) productCount; short sold = (short) amountSold; // update sales database for product sales.updateSalesCount(productID, count, sold);
else { // throw exception or perform other processing
...
}
} ...
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: integer truncation (CWE-197) causes small buffer allocation (CWE-131) leading to out-of-bounds write (CWE-787) in kernel pool, as exploited in the wild per CISA KEV.
Size of a particular type changes for 64-bit platforms, leading to an integer truncation in document processor causes incorrect index to be generated.
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Research Gap
This weakness has traditionally been under-studied and under-reported, although vulnerabilities in popular software have been published in 2008 and 2009.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Numeric truncation error
CLASP
Truncation error
CERT C Secure Coding
FIO34-C
CWE More Abstract
Distinguish between characters read from a file and EOF or WEOF
CERT C Secure Coding
FLP34-C
CWE More Abstract
Ensure that floating point conversions are within range of the new type
CERT C Secure Coding
INT02-C
Understand integer conversion rules
CERT C Secure Coding
INT05-C
Do not use input functions to convert character data if they cannot handle all possible inputs
CERT C Secure Coding
INT31-C
CWE More Abstract
Ensure that integer conversions do not result in lost or misinterpreted data
The CERT Oracle Secure Coding Standard for Java (2011)
NUM12-J
Ensure conversions of numeric types to narrower types do not result in lost or misinterpreted data
Software Fault Patterns
SFP1
Glitch in computation
References
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 6, "Truncation", Page 259. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
A product calculates or uses an incorrect maximum or minimum value that is 1 more, or 1 less, than the correct value.
Alternate Terms
off-by-five
An "off-by-five" error was reported for sudo in 2002 (CVE-2002-0184), but that is more like a "length calculation" error.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
This weakness will generally lead to undefined behavior and therefore crashes. In the case of overflows involving loop index variables, the likelihood of infinite loops is also high.
Modify Memory
Scope: Integrity
If the value in question is important to data (as opposed to flow), simple data corruption has occurred. Also, if the wrap around results in other conditions such as buffer overflows, further memory corruption may occur.
Execute Unauthorized Code or Commands; Bypass Protection Mechanism
Scope: Confidentiality, Availability, Access Control
This weakness can sometimes trigger buffer overflows which can be used to execute arbitrary code. This is usually outside the scope of a program's implicit security policy.
Potential Mitigations
Phase(s)
Mitigation
Implementation
When copying character arrays or using character manipulation methods, the correct size parameter must be used to account for the null terminator that needs to be added at the end of the array. Some examples of functions susceptible to this weakness in C include strcpy(), strncpy(), strcat(), strncat(), printf(), sprintf(), scanf() and sscanf().
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
CanPrecede
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
Class: Not Language-Specific
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The following code allocates memory for a maximum number of widgets. It then gets a user-specified number of widgets, making sure that the user does not request too many. It then initializes the elements of the array using InitializeWidget(). Because the number of widgets can vary for each request, the code inserts a NULL pointer to signify the location of the last widget.
(bad code)
Example Language: C
int i; unsigned int numWidgets; Widget **WidgetList;
However, this code contains an off-by-one calculation error (CWE-193). It allocates exactly enough space to contain the specified number of widgets, but it does not include the space for the NULL pointer. As a result, the allocated buffer is smaller than it is supposed to be (CWE-131). So if the user ever requests MAX_NUM_WIDGETS, there is an out-of-bounds write (CWE-787) when the NULL is assigned. Depending on the environment and compilation settings, this could cause memory corruption.
Example 2
In this example, the code does not account for the terminating null character, and it writes one byte beyond the end of the buffer.
The first call to strncat() appends up to 20 characters plus a terminating null character to fullname[]. There is plenty of allocated space for this, and there is no weakness associated with this first call. However, the second call to strncat() potentially appends another 20 characters. The code does not account for the terminating null character that is automatically added by strncat(). This terminating null character would be written one byte beyond the end of the fullname[] buffer. Therefore an off-by-one error exists with the second strncat() call, as the third argument should be 19.
When using a function like strncat() one must leave a free byte at the end of the buffer for a terminating null character, thus avoiding the off-by-one weakness. Additionally, the last argument to strncat() is the number of characters to append, which must be less than the remaining space in the buffer. Be careful not to just use the total size of the buffer.
The Off-by-one error can also be manifested when reading characters from a character array within a for loop that has an incorrect continuation condition.
(bad code)
Example Language: C
#define PATH_SIZE 60
char filename[PATH_SIZE];
for(i=0; i<=PATH_SIZE; i++) {
char c = fgetc(stdin);
if (c == EOF) {
filename[i] = '\0';
}
else {
filename[i] = c;
}
}
If i reaches PATH_SIZE, then the loop continues. However, filename[PATH_SIZE] is actually out of bounds, since the valid index range is from 0 to PATH_SIZE-1.
In this case, the correct continuation condition is shown below.
(good code)
Example Language: C
for(i=0; i<PATH_SIZE; i++) { ...
Example 4
As another example the Off-by-one error can occur when using the sprintf library function to copy a string variable to a formatted string variable and the original string variable comes from an untrusted source. As in the following example where a local function, setFilename is used to store the value of a filename to a database but first uses sprintf to format the filename. The setFilename function includes an input parameter with the name of the file that is used as the copy source in the sprintf function. The sprintf function will copy the file name to a char array of size 20 and specifies the format of the new variable as 16 characters followed by the file extension .dat.
However this will cause an Off-by-one error if the original filename is exactly 16 characters or larger because the format of 16 characters with the file extension is exactly 20 characters and does not take into account the required null terminator that will be placed at the end of the string.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Off-by-one buffer overflow in function usd by server allows local users to execute arbitrary code as the server user via .htaccess files with long entries.
Off-by-one error in function used in many products leads to a buffer overflow during pathname management, as demonstrated using multiple commands in an FTP server.
Chain: security monitoring product has an off-by-one error that leads to unexpected length values, triggering an assertion.
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 07 - Characters and Strings (STR)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
This is not always a buffer overflow. For example, an off-by-one error could be a factor in a partial comparison, a read from the wrong memory location, an incorrect conditional, etc.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Off-by-one Error
CERT C Secure Coding
STR31-C
Guarantee that storage for strings has sufficient space for character data and the null terminator
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 5: Buffer Overruns." Page 89. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 5, "Off-by-One Errors", Page 180. 1st Edition. Addison Wesley. 2006.
Content
History
Submissions
Submission Date
Submitter
Organization
2006-07-19
(CWE Draft 3, 2006-07-19)
PLOVER
Contributions
Contribution Date
Contributor
Organization
2024-07-20
(CWE 4.17, 2025-04-03)
Jason Xu
Reported compilation error with demonstrative example.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product omits a break statement within a switch or similar construct, causing code associated with multiple conditions to execute. This can cause problems when the programmer only intended to execute code associated with one condition.
Extended Description
This can lead to critical code executing in situations where it should not.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Alter Execution Logic
Scope: Other
This weakness can cause unintended logic to be executed and other unexpected application behavior.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Omitting a break statement so that one may fall through is often indistinguishable from an error, and therefore should be avoided. If you need to use fall-through capabilities, make sure that you have clearly documented this within the switch statement, and ensure that you have examined all the logical possibilities.
Implementation
The functionality of omitting a break statement could be clarified with an if statement. This method is much safer.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
PHP
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
In both of these examples, a message is printed based on the month passed into the function:
(bad code)
Example Language: Java
public void printMessage(int month){
switch (month) {
case 1: print("January"); case 2: print("February"); case 3: print("March"); case 4: print("April"); case 5: print("May"); case 6: print("June"); case 7: print("July"); case 8: print("August"); case 9: print("September"); case 10: print("October"); case 11: print("November"); case 12: print("December");
} println(" is a great month");
}
(bad code)
Example Language: C
void printMessage(int month){
switch (month) {
case 1: printf("January"); case 2: printf("February"); case 3: printf("March"); case 4: printf("April"); case 5: printff("May"); case 6: printf("June"); case 7: printf("July"); case 8: printf("August"); case 9: printf("September"); case 10: printf("October"); case 11: printf("November"); case 12: printf("December");
} printf(" is a great month");
}
Both examples do not use a break statement after each case, which leads to unintended fall-through behavior. For example, calling "printMessage(10)" will result in the text "OctoberNovemberDecember is a great month" being printed.
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Indirect
(where the weakness is a quality issue that might indirectly make it easier to introduce security-relevant weaknesses or make them more difficult to detect)
Detection
Methods
Method
Details
White Box
Omission of a break statement might be intentional, in order to support fallthrough. Automated detection methods might therefore be erroneous. Semantic understanding of expected product behavior is required to interpret whether the code is correct.
Black Box
Since this weakness is associated with a code construct, it would be indistinguishable from other errors that produce the same behavior.
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 7, "Switch Statements", Page 337. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses an expression in which operator precedence causes incorrect logic to be used.
Extended Description
While often just a bug, operator precedence logic errors can have serious consequences if they are used in security-critical code, such as making an authentication decision.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Varies by Context; Unexpected State
Scope: Confidentiality, Integrity, Availability
The consequences will vary based on the context surrounding the incorrect precedence. In a security decision, integrity or confidentiality are the most likely results. Otherwise, a crash may occur due to the software reaching an unexpected state.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Regularly wrap sub-expressions in parentheses, especially in security-critical code.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Logic errors related to operator precedence may cause problems even during normal operation, so they are probably discovered quickly during the testing phase. If testing is incomplete or there is a strong reliance on manual review of the code, then these errors may not be discovered before the software is deployed.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Rarely Prevalent)
C++
(Rarely Prevalent)
Class: Not Language-Specific
(Rarely Prevalent)
Likelihood Of Exploit
Low
Demonstrative Examples
Example 1
In the following example, the method validateUser makes a call to another method to authenticate a username and password for a user and returns a success or failure code.
(bad code)
Example Language: C
#define FAIL 0 #define SUCCESS 1
...
int validateUser(char *username, char *password) {
int isUser = FAIL;
// call method to authenticate username and password
// if authentication fails then return failure otherwise return success if (isUser = AuthenticateUser(username, password) == FAIL) {
return isUser;
} else {
isUser = SUCCESS;
}
return isUser;
}
However, the method that authenticates the username and password is called within an if statement with incorrect operator precedence logic. Because the comparison operator "==" has a higher precedence than the assignment operator "=", the comparison operator will be evaluated first and if the method returns FAIL then the comparison will be true, the return variable will be set to true and SUCCESS will be returned. This operator precedence logic error can be easily resolved by properly using parentheses within the expression of the if statement, as shown below.
(good code)
Example Language: C
...
if ((isUser = AuthenticateUser(username, password)) == FAIL) {
...
Example 2
In this example, the method calculates the return on investment for an accounting/financial application. The return on investment is calculated by subtracting the initial investment costs from the current value and then dividing by the initial investment costs.
(bad code)
Example Language: Java
public double calculateReturnOnInvestment(double currentValue, double initialInvestment) {
However, the return on investment calculation will not produce correct results because of the incorrect operator precedence logic in the equation. The divide operator has a higher precedence than the minus operator, therefore the equation will divide the initial investment costs by the initial investment costs which will only subtract one from the current value. Again this operator precedence logic error can be resolved by the correct use of parentheses within the equation, as shown below.
Note that the initialInvestment variable in this example should be validated to ensure that it is greater than zero to avoid a potential divide by zero error (CWE-369).
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: product does not properly check the result of a reverse DNS lookup because of operator precedence (CWE-783), allowing bypass of DNS-based access restrictions.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C Secure Coding Standard (2008) Chapter 4 - Expressions (EXP)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Comprehensive Categorization: Insufficient Control Flow Management
Vulnerability Mapping Notes
Usage
ALLOWED
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CERT C Secure Coding
EXP00-C
Exact
Use parentheses for precedence of operation
SEI CERT Perl Coding Standard
EXP04-PL
CWE More Abstract
Do not mix the early-precedence logical operators with late-precedence logical operators
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 6, "Precedence", Page 287. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product reads data past the end, or before the beginning, of the intended buffer.
Alternate Terms
OOB read
Shorthand for "Out of bounds" read
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory
Scope: Confidentiality
An attacker could get secret values such as cryptographic keys, PII, memory addresses, or other information that could be used in additional attacks.
Bypass Protection Mechanism
Scope: Confidentiality
Out-of-bounds memory could contain memory addresses or other information that can be used to bypass ASLR and other protection mechanisms in order to improve the reliability of exploiting a separate weakness for code execution.
DoS: Crash, Exit, or Restart
Scope: Availability
An attacker could cause a segmentation fault or crash by causing memory to be read outside of the bounds of the buffer. This is especially likely when the code reads a variable amount of data and assumes that a sentinel exists to stop the read operation, such as a NUL in a string.
Varies by Context
Scope: Other
The read operation could produce other undefined or unexpected results.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Strategy: Input Validation
Assume all input is malicious. Use an "accept known good" input validation strategy, i.e., use a list of acceptable inputs that strictly conform to specifications. Reject any input that does not strictly conform to specifications, or transform it into something that does.
When performing input validation, consider all potentially relevant properties, including length, type of input, the full range of acceptable values, missing or extra inputs, syntax, consistency across related fields, and conformance to business rules. As an example of business rule logic, "boat" may be syntactically valid because it only contains alphanumeric characters, but it is not valid if the input is only expected to contain colors such as "red" or "blue."
Do not rely exclusively on looking for malicious or malformed inputs. This is likely to miss at least one undesirable input, especially if the code's environment changes. This can give attackers enough room to bypass the intended validation. However, denylists can be useful for detecting potential attacks or determining which inputs are so malformed that they should be rejected outright.
To reduce the likelihood of introducing an out-of-bounds read, ensure that you validate and ensure correct calculations for any length argument, buffer size calculation, or offset. Be especially careful of relying on a sentinel (i.e. special character such as NUL) in untrusted inputs.
Architecture and Design
Strategy: Language Selection
Use a language that provides appropriate memory abstractions.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Technologies
Class: ICS/OT
(Often Prevalent)
Demonstrative Examples
Example 1
In the following code, the method retrieves a value from an array at a specific array index location that is given as an input parameter to the method
(bad code)
Example Language: C
int getValueFromArray(int *array, int len, int index) {
int value;
// check that the array index is less than the maximum
// length of the array if (index < len) {
// get the value at the specified index of the array value = array[index];
} // if array index is invalid then output error message
// and return value indicating error else {
printf("Value is: %d\n", array[index]); value = -1;
}
return value;
}
However, this method only verifies that the given array index is less than the maximum length of the array but does not check for the minimum value (CWE-839). This will allow a negative value to be accepted as the input array index, which will result in a out of bounds read (CWE-125) and may allow access to sensitive memory. The input array index should be checked to verify that is within the maximum and minimum range required for the array (CWE-129). In this example the if statement should be modified to include a minimum range check, as shown below.
(good code)
Example Language: C
...
// check that the array index is within the correct
// range of values for the array if (index >= 0 && index < len) {
...
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
The reference implementation code for a Trusted Platform Module does not implement length checks on data, allowing for an attacker to read 2 bytes past the end of a buffer.
Chain: "Heartbleed" bug receives an inconsistent length parameter (CWE-130) enabling an out-of-bounds read (CWE-126), returning memory that could include private cryptographic keys and other sensitive data.
Chain: product does not handle when an input string is not NULL terminated (CWE-170), leading to buffer over-read (CWE-125) or heap-based buffer overflow (CWE-122).
Chain: series of floating-point precision errors
(CWE-1339) in a web browser rendering engine causes out-of-bounds read
(CWE-125), giving access to cross-origin data
OS kernel trusts userland-supplied length value, allowing reading of sensitive information
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
When an out-of-bounds read occurs, typically the product has already made a separate mistake, such as modifying an index or performing pointer arithmetic that produces an out-of-bounds address.
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
SEI CERT C Coding Standard - Guidelines 07. Characters and Strings (STR)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2019 CWE Top 25 Most Dangerous Software Errors
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2021 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2023 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2024 CWE Top 25 Most Dangerous Software Weaknesses
Vulnerability Mapping Notes
Usage
ALLOWED
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Out-of-bounds Read
CERT C Secure Coding
ARR30-C
Imprecise
Do not form or use out-of-bounds pointers or array subscripts
CERT C Secure Coding
ARR38-C
Imprecise
Guarantee that library functions do not form invalid pointers
CERT C Secure Coding
EXP39-C
Imprecise
Do not access a variable through a pointer of an incompatible type
CERT C Secure Coding
STR31-C
Imprecise
Guarantee that storage for strings has sufficient space for character data and the null terminator
CERT C Secure Coding
STR32-C
CWE More Abstract
Do not pass a non-null-terminated character sequence to a library function that expects a string
Raoul Strackx, Yves Younan, Pieter Philippaerts, Frank Piessens, Sven Lachmund and Thomas Walter. "Breaking the memory secrecy assumption". ACM. 2009-03-31.
<https://dl.acm.org/doi/10.1145/1519144.1519145>.
(URL validated: 2023-04-07)
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product writes data past the end, or before the beginning, of the intended buffer.
Alternate Terms
Memory Corruption
Often used to describe the consequences of writing to memory outside the bounds of a buffer, or to memory that is otherwise invalid.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; Execute Unauthorized Code or Commands
Scope: Integrity
Write operations could cause memory corruption. In some cases, an adversary can modify control data such as return addresses in order to execute unexpected code.
DoS: Crash, Exit, or Restart
Scope: Availability
Attempting to access out-of-range, invalid, or unauthorized memory could cause the product to crash.
Unexpected State
Scope: Other
Subsequent write operations can produce undefined or unexpected results.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Strategy: Language Selection
Use a language that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
For example, many languages that perform their own memory management, such as Java and Perl, are not subject to buffer overflows. Other languages, such as Ada and C#, typically provide overflow protection, but the protection can be disabled by the programmer.
Be wary that a language's interface to native code may still be subject to overflows, even if the language itself is theoretically safe.
Architecture and Design
Strategy: Libraries or Frameworks
Use a vetted library or framework that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
Examples include the Safe C String Library (SafeStr) by Messier and Viega [REF-57], and the Strsafe.h library from Microsoft [REF-56]. These libraries provide safer versions of overflow-prone string-handling functions.
Note: This is not a complete solution, since many buffer overflows are not related to strings.
Operation; Build and Compilation
Strategy: Environment Hardening
Use automatic buffer overflow detection mechanisms that are offered by certain compilers or compiler extensions. Examples include: the Microsoft Visual Studio /GS flag, Fedora/Red Hat FORTIFY_SOURCE GCC flag, StackGuard, and ProPolice, which provide various mechanisms including canary-based detection and range/index checking.
D3-SFCV (Stack Frame Canary Validation) from D3FEND [REF-1334] discusses canary-based detection in detail.
Effectiveness: Defense in Depth
Note:
This is not necessarily a complete solution, since these mechanisms only detect certain types of overflows. In addition, the result is still a denial of service, since the typical response is to exit the application.
Implementation
Consider adhering to the following rules when allocating and managing an application's memory:
Double check that the buffer is as large as specified.
When using functions that accept a number of bytes to copy, such as strncpy(), be aware that if the destination buffer size is equal to the source buffer size, it may not NULL-terminate the string.
Check buffer boundaries if accessing the buffer in a loop and make sure there is no danger of writing past the allocated space.
If necessary, truncate all input strings to a reasonable length before passing them to the copy and concatenation functions.
Operation; Build and Compilation
Strategy: Environment Hardening
Run or compile the software using features or extensions that randomly arrange the positions of a program's executable and libraries in memory. Because this makes the addresses unpredictable, it can prevent an attacker from reliably jumping to exploitable code.
Examples include Address Space Layout Randomization (ASLR) [REF-58] [REF-60] and Position-Independent Executables (PIE) [REF-64]. Imported modules may be similarly realigned if their default memory addresses conflict with other modules, in a process known as "rebasing" (for Windows) and "prelinking" (for Linux) [REF-1332] using randomly generated addresses. ASLR for libraries cannot be used in conjunction with prelink since it would require relocating the libraries at run-time, defeating the whole purpose of prelinking.
For more information on these techniques see D3-SAOR (Segment Address Offset Randomization) from D3FEND [REF-1335].
Effectiveness: Defense in Depth
Note: These techniques do not provide a complete solution. For instance, exploits frequently use a bug that discloses memory addresses in order to maximize reliability of code execution [REF-1337]. It has also been shown that a side-channel attack can bypass ASLR [REF-1333].
Operation
Strategy: Environment Hardening
Use a CPU and operating system that offers Data Execution Protection (using hardware NX or XD bits) or the equivalent techniques that simulate this feature in software, such as PaX [REF-60] [REF-61]. These techniques ensure that any instruction executed is exclusively at a memory address that is part of the code segment.
For more information on these techniques see D3-PSEP (Process Segment Execution Prevention) from D3FEND [REF-1336].
Effectiveness: Defense in Depth
Note: This is not a complete solution, since buffer overflows could be used to overwrite nearby variables to modify the software's state in dangerous ways. In addition, it cannot be used in cases in which self-modifying code is required. Finally, an attack could still cause a denial of service, since the typical response is to exit the application.
Implementation
Replace unbounded copy functions with analogous functions that support length arguments, such as strcpy with strncpy. Create these if they are not available.
Effectiveness: Moderate
Note: This approach is still susceptible to calculation errors, including issues such as off-by-one errors (CWE-193) and incorrectly calculating buffer lengths (CWE-131).
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Class: Assembly
(Undetermined Prevalence)
Technologies
Class: ICS/OT
(Often Prevalent)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
The following code attempts to save four different identification numbers into an array.
If returnChunkSize() happens to encounter an error it will return -1. Notice that the return value is not checked before the memcpy operation (CWE-252), so -1 can be passed as the size argument to memcpy() (CWE-805). Because memcpy() assumes that the value is unsigned, it will be interpreted as MAXINT-1 (CWE-195), and therefore will copy far more memory than is likely available to the destination buffer (CWE-787, CWE-788).
Example 3
This code takes an IP address from the user and verifies that it is well formed. It then looks up the hostname and copies it into a buffer.
This function allocates a buffer of 64 bytes to store the hostname. However, there is no guarantee that the hostname will not be larger than 64 bytes. If an attacker specifies an address which resolves to a very large hostname, then the function may overwrite sensitive data or even relinquish control flow to the attacker.
Note that this example also contains an unchecked return value (CWE-252) that can lead to a NULL pointer dereference (CWE-476).
Example 4
This code applies an encoding procedure to an input string and stores it into a buffer.
(bad code)
Example Language: C
char * copy_input(char *user_supplied_string){
int i, dst_index; char *dst_buf = (char*)malloc(4*sizeof(char) * MAX_SIZE); if ( MAX_SIZE <= strlen(user_supplied_string) ){
die("user string too long, die evil hacker!");
} dst_index = 0; for ( i = 0; i < strlen(user_supplied_string); i++ ){
The programmer attempts to encode the ampersand character in the user-controlled string. However, the length of the string is validated before the encoding procedure is applied. Furthermore, the programmer assumes encoding expansion will only expand a given character by a factor of 4, while the encoding of the ampersand expands by 5. As a result, when the encoding procedure expands the string it is possible to overflow the destination buffer if the attacker provides a string of many ampersands.
Example 5
In the following C/C++ code, a utility function is used to trim trailing whitespace from a character string. The function copies the input string to a local character string and uses a while statement to remove the trailing whitespace by moving backward through the string and overwriting whitespace with a NUL character.
(bad code)
Example Language: C
char* trimTrailingWhitespace(char *strMessage, int length) {
However, this function can cause a buffer underwrite if the input character string contains all whitespace. On some systems the while statement will move backwards past the beginning of a character string and will call the isspace() function on an address outside of the bounds of the local buffer.
Example 6
The following code allocates memory for a maximum number of widgets. It then gets a user-specified number of widgets, making sure that the user does not request too many. It then initializes the elements of the array using InitializeWidget(). Because the number of widgets can vary for each request, the code inserts a NULL pointer to signify the location of the last widget.
(bad code)
Example Language: C
int i; unsigned int numWidgets; Widget **WidgetList;
However, this code contains an off-by-one calculation error (CWE-193). It allocates exactly enough space to contain the specified number of widgets, but it does not include the space for the NULL pointer. As a result, the allocated buffer is smaller than it is supposed to be (CWE-131). So if the user ever requests MAX_NUM_WIDGETS, there is an out-of-bounds write (CWE-787) when the NULL is assigned. Depending on the environment and compilation settings, this could cause memory corruption.
Example 7
The following is an example of code that may result in a buffer underwrite. This code is attempting to replace the substring "Replace Me" in destBuf with the string stored in srcBuf. It does so by using the function strstr(), which returns a pointer to the found substring in destBuf. Using pointer arithmetic, the starting index of the substring is found.
(bad code)
Example Language: C
int main() {
...
char *result = strstr(destBuf, "Replace Me");
int idx = result - destBuf;
strcpy(&destBuf[idx], srcBuf);
...
}
In the case where the substring is not found in destBuf, strstr() will return NULL, causing the pointer arithmetic to be undefined, potentially setting the value of idx to a negative number. If idx is negative, this will result in a buffer underwrite of destBuf.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Font rendering library does not properly
handle assigning a signed short value to an unsigned
long (CWE-195), leading to an integer wraparound
(CWE-190), causing too small of a buffer (CWE-131),
leading to an out-of-bounds write
(CWE-787).
The reference implementation code for a Trusted Platform Module does not implement length checks on data, allowing for an attacker to write 2 bytes past the end of a buffer.
Chain: integer truncation (CWE-197) causes small buffer allocation (CWE-131) leading to out-of-bounds write (CWE-787) in kernel pool, as exploited in the wild per CISA KEV.
chain: mobile phone Bluetooth implementation does not include offset when calculating packet length (CWE-682), leading to out-of-bounds write (CWE-787)
Heap-based buffer overflow in media player using a long entry in a playlist
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
At the point when the product writes data to an invalid location, it is likely that a separate weakness already occurred earlier. For example, the product might alter an index, perform incorrect pointer arithmetic, initialize or release memory incorrectly, etc., thus referencing a memory location outside the buffer.
Detection
Methods
Method
Details
Automated Static Analysis
This weakness can often be detected using automated static analysis tools. Many modern tools use data flow analysis or constraint-based techniques to minimize the number of false positives.
Automated static analysis generally does not account for environmental considerations when reporting out-of-bounds memory operations. This can make it difficult for users to determine which warnings should be investigated first. For example, an analysis tool might report buffer overflows that originate from command line arguments in a program that is not expected to run with setuid or other special privileges.
Effectiveness: High
Note:Detection techniques for buffer-related errors are more mature than for most other weakness types.
Automated Dynamic Analysis
This weakness can be detected using dynamic tools and techniques that interact with the software using large test suites with many diverse inputs, such as fuzz testing (fuzzing), robustness testing, and fault injection. The software's operation may slow down, but it should not become unstable, crash, or generate incorrect results.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2019 CWE Top 25 Most Dangerous Software Errors
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2021 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2023 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2024 CWE Top 25 Most Dangerous Software Weaknesses
Vulnerability Mapping Notes
Usage
ALLOWED
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 5: Buffer Overruns." Page 89. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 3, "Nonexecutable Stack", Page 76. 1st Edition. Addison Wesley. 2006.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 5, "Protection Mechanisms", Page 189. 1st Edition. Addison Wesley. 2006.
CWE-374: Passing Mutable Objects to an Untrusted Method
Weakness ID: 374
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product sends non-cloned mutable data as an argument to a method or function.
Extended Description
The function or method that has been called can alter or delete the mutable data. This could violate assumptions that the calling function has made about its state. In situations where unknown code is called with references to mutable data, this external code could make changes to the data sent. If this data was not previously cloned, the modified data might not be valid in the context of execution.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory
Scope: Integrity
Potentially data could be tampered with by another function which should not have been tampered with.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Pass in data which should not be altered as constant or immutable.
Implementation
Clone all mutable data before passing it into an external function . This is the preferred mitigation. This way, regardless of what changes are made to the data, a valid copy is retained for use by the class.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
The following example demonstrates the weakness.
(bad code)
Example Language: C
private:
int foo; complexType bar; String baz; otherClass externalClass;
public:
void doStuff() {
externalClass.doOtherStuff(foo, bar, baz)
}
In this example, bar and baz will be passed by reference to doOtherStuff() which may change them.
Example 2
In the following Java example, the BookStore class manages the sale of books in a bookstore, this class includes the member objects for the bookstore inventory and sales database manager classes. The BookStore class includes a method for updating the sales database and inventory when a book is sold. This method retrieves a Book object from the bookstore inventory object using the supplied ISBN number for the book class, then calls a method for the sales object to update the sales information and then calls a method for the inventory object to update inventory for the BookStore.
(bad code)
Example Language: Java
public class BookStore {
private BookStoreInventory inventory; private SalesDBManager sales; ... // constructor for BookStore public BookStore() {
this.inventory = new BookStoreInventory(); this.sales = new SalesDBManager(); ...
} public void updateSalesAndInventoryForBookSold(String bookISBN) {
// Get book object from inventory using ISBN Book book = inventory.getBookWithISBN(bookISBN); // update sales information for book sold sales.updateSalesInformation(book); // update inventory inventory.updateInventory(book);
} // other BookStore methods ...
} public class Book {
private String title; private String author; private String isbn; // Book object constructors and get/set methods ...
}
However, in this example the Book object that is retrieved and passed to the method of the sales object could have its contents modified by the method. This could cause unexpected results when the book object is sent to the method for the inventory object to update the inventory.
In the Java programming language arguments to methods are passed by value, however in the case of objects a reference to the object is passed by value to the method. When an object reference is passed as a method argument a copy of the object reference is made within the method and therefore both references point to the same object. This allows the contents of the object to be modified by the method that holds the copy of the object reference. [REF-374]
In this case the contents of the Book object could be modified by the method of the sales object prior to the call to update the inventory.
To prevent the contents of the Book object from being modified, a copy of the Book object should be made before the method call to the sales object. In the following example a copy of the Book object is made using the clone() method and the copy of the Book object is passed to the method of the sales object. This will prevent any changes being made to the original Book object.
(good code)
Example Language: Java
... public void updateSalesAndInventoryForBookSold(String bookISBN) {
// Get book object from inventory using ISBN Book book = inventory.getBookWithISBN(bookISBN); // Create copy of book object to make sure contents are not changed Book bookSold = (Book) book.clone(); // update sales information for book sold sales.updateSalesInformation(bookSold); // update inventory inventory.updateInventory(book);
} ...
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Passing mutable objects to an untrusted method
The CERT Oracle Secure Coding Standard for Java (2011)
OBJ04-J
Provide mutable classes with copy functionality to safely allow passing instances to untrusted code
CWE-689: Permission Race Condition During Resource Copy
Weakness ID: 689
(Structure: Composite)
Composite - a Compound Element that consists of two or more distinct weaknesses, in which all weaknesses must be present at the same time in order for a potential vulnerability to arise. Removing any of the weaknesses eliminates or sharply reduces the risk. One weakness, X, can be "broken down" into component weaknesses Y and Z. There can be cases in which one weakness might not be essential to a composite, but changes the nature of the composite when it becomes a vulnerability.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product, while copying or cloning a resource, does not set the resource's permissions or access control until the copy is complete, leaving the resource exposed to other spheres while the copy is taking place.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Application Data; Modify Application Data
Scope: Confidentiality, Integrity
Composite Components
Nature
Type
ID
Name
Requires
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Concurrent Execution using Shared Resource with Improper Synchronization ('Race Condition')
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Common examples occur in file archive extraction, in which the product begins the extraction with insecure default permissions, then only sets the final permissions (as specified in the archive) once the copy is complete. The larger the archive, the larger the timing window for the race condition.
This weakness has also occurred in some operating system utilities that perform copies of deeply nested directories containing a large number of files.
This weakness can occur in any type of functionality that involves copying objects or resources in a multi-user environment, including at the application level. For example, a document management system might allow a user to copy a private document, but if it does not set the new copy to be private as soon as the copy begins, then other users might be able to view the document while the copy is still taking place.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
Perl
(Undetermined Prevalence)
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Database product creates files world-writable before initializing the setuid bits, leading to modification of executables.
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Other
Rationale
This is a Composite of multiple weaknesses that must all occur simultaneously.
Comments
While composites are supported in CWE, they have not been a focus of research. There is a chance that future research or CWE scope clarifications will change or deprecate them. Perform root-cause analysis to determine which weaknesses allow this issue to occur, and map to those weaknesses. For example, the delayed permission-setting in the resource copy might be intended functionality, but creation in a location with insecure permissions might not.
Notes
Research Gap
Under-studied. It seems likely that this weakness could occur in any situation in which a complex or large copy operation occurs, when the resource can be made available to other spheres as soon as it is created, but before its initialization is complete.
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 9, "Permission Races", Page 533. 1st Edition. Addison Wesley. 2006.
CWE-495: Private Data Structure Returned From A Public Method
Weakness ID: 495
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product has a method that is declared public, but returns a reference to a private data structure, which could then be modified in unexpected ways.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Application Data
Scope: Integrity
The contents of the data structure can be modified from outside the intended scope.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Declare the method private.
Implementation
Clone the member data and keep an unmodified version of the data private to the object.
Implementation
Use public setter methods that govern how a private member can be modified.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Improper Control of a Resource Through its Lifetime
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Demonstrative Examples
Example 1
Here, a public method in a Java class returns a reference to a private array. Given that arrays in Java are mutable, any modifications made to the returned reference would be reflected in the original private array.
(bad code)
Example Language: Java
private String[] colors; public String[] getColors() {
return colors;
}
Example 2
In this example, the Color class defines functions that return non-const references to private members (an array type and an integer type), which are then arbitrarily altered from outside the control of the class.
(bad code)
Example Language: C++
class Color {
private:
int[2] colorArray; int colorValue;
public:
Color () : colorArray { 1, 2 }, colorValue (3) { }; int[2] & fa () { return colorArray; } // return reference to private array int & fv () { return colorValue; } // return reference to private integer
};
int main () {
Color c;
c.fa () [1] = 42; // modifies private array element c.fv () = 42; // modifies private int
return 0;
}
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
7 Pernicious Kingdoms
Private Array-Typed Field Returned From A Public Method
CWE-496: Public Data Assigned to Private Array-Typed Field
Weakness ID: 496
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
Assigning public data to a private array is equivalent to giving public access to the array.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Application Data
Scope: Integrity
The contents of the array can be modified from outside the intended scope.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Do not allow objects to modify private members of a class.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Improper Control of a Resource Through its Lifetime
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Demonstrative Examples
Example 1
In the example below, the setRoles() method assigns a publically-controllable array to a private field, thus allowing the caller to modify the private array directly by virtue of the fact that arrays in Java are mutable.
(bad code)
Example Language: Java
private String[] userRoles; public void setUserRoles(String[] userRoles) {
this.userRoles = userRoles;
}
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
If two threads of execution use a resource simultaneously, there exists the possibility that resources may be used while invalid, in turn making the state of execution undefined.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Alter Execution Logic; Unexpected State
Scope: Integrity, Other
The main problem is that -- if a lock is overcome -- data could be altered in a bad state.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Use locking functionality. This is the recommended solution. Implement some form of locking mechanism around code which alters or reads persistent data in a multithreaded environment.
Architecture and Design
Create resource-locking validation checks. If no inherent locking mechanisms exist, use flags and signals to enforce your own blocking scheme when resources are being used by other threads of execution.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
The following example demonstrates the weakness.
(bad code)
Example Language: C
int foo = 0; int storenum(int num) {
static int counter = 0; counter++; if (num > foo) foo = num; return foo;
}
(bad code)
Example Language: Java
public classRace {
static int foo = 0; public static void main() {
new Threader().start(); foo = 1;
} public static class Threader extends Thread {
public void run() {
System.out.println(foo);
}
}
}
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: two threads in a web browser use the same resource (CWE-366), but one of those threads can destroy the resource before the other has completed (CWE-416).
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Affected Resources
System Process
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Race condition within a thread
CERT C Secure Coding
CON32-C
CWE More Abstract
Prevent data races when accessing bit-fields from multiple threads
CERT C Secure Coding
CON40-C
CWE More Abstract
Do not refer to an atomic variable twice in an expression
CERT C Secure Coding
CON43-C
Exact
Do not allow data races in multithreaded code
The CERT Oracle Secure Coding Standard for Java (2011)
VNA02-J
Ensure that compound operations on shared variables are atomic
The CERT Oracle Secure Coding Standard for Java (2011)
VNA03-J
Do not assume that a group of calls to independently atomic methods is atomic
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 13: Race Conditions." Page 205. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 13, "Race Conditions", Page 759. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product attempts to return a memory resource to the system, but it calls the wrong release function or calls the appropriate release function incorrectly.
Extended Description
This weakness can take several forms, such as:
The memory was allocated, explicitly or implicitly, via one memory management method and deallocated using a different, non-compatible function (CWE-762).
The function calls or memory management routines chosen are appropriate, however they are used incorrectly, such as in CWE-761.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; DoS: Crash, Exit, or Restart; Execute Unauthorized Code or Commands
Scope: Integrity, Availability, Confidentiality
This weakness may result in the corruption of memory, and perhaps instructions, possibly leading to a crash. If the corrupted memory can be effectively controlled, it may be possible to execute arbitrary code.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Only call matching memory management functions. Do not mix and match routines. For example, when you allocate a buffer with malloc(), dispose of the original pointer with free().
Implementation
When programming in C++, consider using smart pointers provided by the boost library to help correctly and consistently manage memory.
Architecture and Design
Strategy: Libraries or Frameworks
Use a vetted library or framework that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
For example, glibc in Linux provides protection against free of invalid pointers.
Architecture and Design
Use a language that provides abstractions for memory allocation and deallocation.
Testing
Use a tool that dynamically detects memory management problems, such as valgrind.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Demonstrative Examples
Example 1
This code attempts to tokenize a string and place it into an array using the strsep function, which inserts a \0 byte in place of whitespace or a tab character. After finishing the loop, each string in the AP array points to a location within the input string.
(bad code)
Example Language: C
char **ap, *argv[10], *inputstring; for (ap = argv; (*ap = strsep(&inputstring, " \t")) != NULL;)
if (**ap != '\0')
if (++ap >= &argv[10])
break;
/.../ free(ap[4]);
Since strsep is not allocating any new memory, freeing an element in the middle of the array is equivalent to free a pointer in the middle of inputstring.
Example 2
This example allocates a BarObj object using the new operator in C++, however, the programmer then deallocates the object using free(), which may lead to unexpected behavior.
(bad code)
Example Language: C++
void foo(){
BarObj *ptr = new BarObj() /* do some work with ptr here */
...
free(ptr);
}
Instead, the programmer should have either created the object with one of the malloc family functions, or else deleted the object with the delete operator.
(good code)
Example Language: C++
void foo(){
BarObj *ptr = new BarObj() /* do some work with ptr here */
...
delete ptr;
}
Example 3
In this example, the programmer dynamically allocates a buffer to hold a string and then searches for a specific character. After completing the search, the programmer attempts to release the allocated memory and return SUCCESS or FAILURE to the caller. Note: for simplification, this example uses a hard-coded "Search Me!" string and a constant string length of 20.
} /* didn't match yet, increment pointer and try next char */
str = str + 1;
} /* we did not match the char in the string, free mem and return failure */
free(str); return FAILURE;
}
However, if the character is not at the beginning of the string, or if it is not in the string at all, then the pointer will not be at the start of the buffer when the programmer frees it.
Instead of freeing the pointer in the middle of the buffer, the programmer can use an indexing pointer to step through the memory or abstract the memory calculations by using array indexing.
(good code)
Example Language: C
#define SUCCESS (1) #define FAILURE (0)
int cointains_char(char c){
char *str; int i = 0; str = (char*)malloc(20*sizeof(char)); strcpy(str, "Search Me!"); while( i < strlen(str) ){
} /* didn't match yet, increment pointer and try next char */
i = i + 1;
} /* we did not match the char in the string, free mem and return failure */
free(str); return FAILURE;
}
Example 4
Consider the following code in the context of a parsing application to extract commands out of user data. The intent is to parse each command and add it to a queue of commands to be executed, discarding each malformed entry.
/* The following loop will parse and process each token in the input string */
tok = strtok( input, sep); while( NULL != tok ){
if( isMalformed( tok ) ){
/* ignore and discard bad data */ free( tok );
} else{
add_to_command_queue( tok );
} tok = strtok( NULL, sep));
}
While the above code attempts to free memory associated with bad commands, since the memory was all allocated in one chunk, it must all be freed together.
One way to fix this problem would be to copy the commands into a new memory location before placing them in the queue. Then, after all commands have been processed, the memory can safely be freed.
/* The following loop will parse and process each token in the input string */
tok = strtok( input, sep); while( NULL != tok ){
if( !isMalformed( command ) ){
/* copy and enqueue good data */ command = (char*) malloc( (strlen(tok) + 1) * sizeof(char) ); strcpy( command, tok ); add_to_command_queue( command );
} tok = strtok( NULL, sep));
}
free( input )
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
function "internally calls 'calloc' and returns a pointer at an index... inside the allocated buffer. This led to freeing invalid memory."
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Maintenance
The view-1000 subtree that is associated with this weakness needs additional work. Several entries will likely be created in this branch. Currently the focus is on free() of memory, but delete and other related release routines may require the creation of intermediate entries that are not specific to a particular function. In addition, the role of other types of invalid pointers, such as an expired pointer, i.e. CWE-415 Double Free and release of uninitialized pointers, related to CWE-457.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product makes invalid assumptions about how protocol data or memory is organized at a lower level, resulting in unintended program behavior.
Extended Description
When changing platforms or protocol versions, in-memory organization of data may change in unintended ways. For example, some architectures may place local variables A and B right next to each other with A on top; some may place them next to each other with B on top; and others may add some padding to each. The padding size may vary to ensure that each variable is aligned to a proper word size.
In protocol implementations, it is common to calculate an offset relative to another field to pick out a specific piece of data. Exceptional conditions, often involving new protocol versions, may add corner cases that change the data layout in an unusual way. The result can be that an implementation accesses an unintended field in the packet, treating data of one type as data of another type.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; Read Memory
Scope: Integrity, Confidentiality
Can result in unintended modifications or exposure of sensitive memory.
Potential Mitigations
Phase(s)
Mitigation
Implementation; Architecture and Design
In flat address space situations, never allow computing memory addresses as offsets from another memory address.
Architecture and Design
Fully specify protocol layout unambiguously, providing a structured grammar (e.g., a compilable yacc grammar).
Testing
Testing: Test that the implementation properly handles each case in the protocol grammar.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Improper Interaction Between Multiple Correctly-Behaving Entities
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Insufficient Encapsulation of Machine-Dependent Functionality
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
Low
Demonstrative Examples
Example 1
In this example function, the memory address of variable b is derived by adding 1 to the address of variable a. This derived address is then used to assign the value 0 to b.
(bad code)
Example Language: C
void example() {
char a; char b; *(&a + 1) = 0;
}
Here, b may not be one byte past a. It may be one byte in front of a. Or, they may have three bytes between them because they are aligned on 32-bit boundaries.
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Reliance on data layout
References
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 6, "Structure Padding", Page 284. 1st Edition. Addison Wesley. 2006.
CWE-466: Return of Pointer Value Outside of Expected Range
Weakness ID: 466
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
A function can return a pointer to memory that is outside of the buffer that the pointer is expected to reference.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory; Modify Memory
Scope: Confidentiality, Integrity
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Relevant to the view "Seven Pernicious Kingdoms" (View-700)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Maintenance
This entry should have a chaining relationship with CWE-119 instead of a parent / child relationship, however the focus of this weakness does not map cleanly to any existing entries in CWE. A new parent is being considered which covers the more generic problem of incorrect return values. There is also an abstract relationship to weaknesses in which one component sends incorrect messages to another component; in this case, one routine is sending an incorrect value to another.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
A function returns the address of a stack variable, which will cause unintended program behavior, typically in the form of a crash.
Extended Description
Because local variables are allocated on the stack, when a program returns a pointer to a local variable, it is returning a stack address. A subsequent function call is likely to re-use this same stack address, thereby overwriting the value of the pointer, which no longer corresponds to the same variable since a function's stack frame is invalidated when it returns. At best this will cause the value of the pointer to change unexpectedly. In many cases it causes the program to crash the next time the pointer is dereferenced.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory; Modify Memory; Execute Unauthorized Code or Commands; DoS: Crash, Exit, or Restart
Scope: Availability, Integrity, Confidentiality
If the returned stack buffer address is dereferenced after the return, then an attacker may be able to modify or read memory, depending on how the address is used. If the address is used for reading, then the address itself may be exposed, or the contents that the address points to. If the address is used for writing, this can lead to a crash and possibly code execution.
Potential Mitigations
Phase(s)
Mitigation
Testing
Use static analysis tools to spot return of the address of a stack variable.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Reliance on Undefined, Unspecified, or Implementation-Defined Behavior
CanPrecede
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Operation on a Resource after Expiration or Release
CanPrecede
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
(where the weakness is a quality issue that might indirectly make it easier to introduce security-relevant weaknesses or make them more difficult to detect)
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CERT C Secure Coding
DCL30-C
CWE More Specific
Declare objects with appropriate storage durations
CERT C Secure Coding
POS34-C
Do not call putenv() with a pointer to an automatic variable as the argument
CWE-375: Returning a Mutable Object to an Untrusted Caller
Weakness ID: 375
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
Sending non-cloned mutable data as a return value may result in that data being altered or deleted by the calling function.
Extended Description
In situations where functions return references to mutable data, it is possible that the external code which called the function may make changes to the data sent. If this data was not previously cloned, the class will then be using modified data which may violate assumptions about its internal state.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory
Scope: Access Control, Integrity
Potentially data could be tampered with by another function which should not have been tampered with.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Declare returned data which should not be altered as constant or immutable.
Implementation
Clone all mutable data before returning references to it. This is the preferred mitigation. This way, regardless of what changes are made to the data, a valid copy is retained for use by the class.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Java
(Undetermined Prevalence)
C#
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
This class has a private list of patients, but provides a way to see the list :
(bad code)
Example Language: Java
public class ClinicalTrial {
private PatientClass[] patientList = new PatientClass[50]; public getPatients(...){
return patientList;
}
}
While this code only means to allow reading of the patient list, the getPatients() method returns a reference to the class's original patient list instead of a reference to a copy of the list. Any caller of this method can arbitrarily modify the contents of the patient list even though it is a private member of the class.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Mutable object returned
The CERT Oracle Secure Coding Standard for Java (2011)
OBJ04-J
Provide mutable classes with copy functionality to safely allow passing instances to untrusted code
The CERT Oracle Secure Coding Standard for Java (2011)
OBJ05-J
Defensively copy private mutable class members before returning their references
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses a signal handler that introduces a race condition.
Extended Description
Race conditions frequently occur in signal handlers, since signal handlers support asynchronous actions. These race conditions have a variety of root causes and symptoms. Attackers may be able to exploit a signal handler race condition to cause the product state to be corrupted, possibly leading to a denial of service or even code execution.
These issues occur when non-reentrant functions, or state-sensitive actions occur in the signal handler, where they may be called at any time. These behaviors can violate assumptions being made by the "regular" code that is interrupted, or by other signal handlers that may also be invoked. If these functions are called at an inopportune moment - such as while a non-reentrant function is already running - memory corruption could occur that may be exploitable for code execution. Another signal race condition commonly found occurs when free is called within a signal handler, resulting in a double free and therefore a write-what-where condition. Even if a given pointer is set to NULL after it has been freed, a race condition still exists between the time the memory was freed and the pointer was set to NULL. This is especially problematic if the same signal handler has been set for more than one signal -- since it means that the signal handler itself may be reentered.
There are several known behaviors related to signal handlers that have received the label of "signal handler race condition":
Shared state (e.g. global data or static variables) that are accessible to both a signal handler and "regular" code
Shared state between a signal handler and other signal handlers
Use of non-reentrant functionality within a signal handler - which generally implies that shared state is being used. For example, malloc() and free() are non-reentrant because they may use global or static data structures for managing memory, and they are indirectly used by innocent-seeming functions such as syslog(); these functions could be exploited for memory corruption and, possibly, code execution.
Association of the same signal handler function with multiple signals - which might imply shared state, since the same code and resources are accessed. For example, this can be a source of double-free and use-after-free weaknesses.
Use of setjmp and longjmp, or other mechanisms that prevent a signal handler from returning control back to the original functionality
While not technically a race condition, some signal handlers are designed to be called at most once, and being called more than once can introduce security problems, even when there are not any concurrent calls to the signal handler. This can be a source of double-free and use-after-free weaknesses.
Signal handler vulnerabilities are often classified based on the absence of a specific protection mechanism, although this style of classification is discouraged in CWE because programmers often have a choice of several different mechanisms for addressing the weakness. Such protection mechanisms may preserve exclusivity of access to the shared resource, and behavioral atomicity for the relevant code:
Avoiding shared state
Using synchronization in the signal handler
Using synchronization in the regular code
Disabling or masking other signals, which provides atomicity (which effectively ensures exclusivity)
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Application Data; Modify Memory; DoS: Crash, Exit, or Restart; Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
It may be possible to cause data corruption and possibly execute arbitrary code by modifying global variables or data structures at unexpected times, violating the assumptions of code that uses this global data.
Gain Privileges or Assume Identity
Scope: Access Control
If a signal handler interrupts code that is executing with privileges, it may be possible that the signal handler will also be executed with elevated privileges, possibly making subsequent exploits more severe.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Strategy: Language Selection
Use a language that does not allow this weakness to occur or provides constructs that make this weakness easier to avoid.
Architecture and Design
Design signal handlers to only set flags, rather than perform complex functionality. These flags can then be checked and acted upon within the main program loop.
Implementation
Only use reentrant functions within signal handlers. Also, use validation to ensure that state is consistent while performing asynchronous actions that affect the state of execution.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Concurrent Execution using Shared Resource with Improper Synchronization ('Race Condition')
ParentOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Dangerous Signal Handler not Disabled During Sensitive Operations
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Signal Handler with Functionality that is not Asynchronous-Safe
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Signal Handler Function Associated with Multiple Signals
CanPrecede
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Sometimes Prevalent)
C++
(Sometimes Prevalent)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
This code registers the same signal handler function with two different signals (CWE-831). If those signals are sent to the process, the handler creates a log message (specified in the first argument to the program) and exits.
(bad code)
Example Language: C
char *logMessage;
void handler (int sigNum) {
syslog(LOG_NOTICE, "%s\n", logMessage); free(logMessage); /* artificially increase the size of the timing window to make demonstration of this weakness easier. */
sleep(10); exit(0);
}
int main (int argc, char* argv[]) {
logMessage = strdup(argv[1]); /* Register signal handlers. */
signal(SIGHUP, handler); signal(SIGTERM, handler); /* artificially increase the size of the timing window to make demonstration of this weakness easier. */
sleep(10);
}
The handler function uses global state (globalVar and logMessage), and it can be called by both the SIGHUP and SIGTERM signals. An attack scenario might follow these lines:
The program begins execution, initializes logMessage, and registers the signal handlers for SIGHUP and SIGTERM.
The program begins its "normal" functionality, which is simplified as sleep(), but could be any functionality that consumes some time.
The attacker sends SIGHUP, which invokes handler (call this "SIGHUP-handler").
SIGHUP-handler begins to execute, calling syslog().
syslog() calls malloc(), which is non-reentrant. malloc() begins to modify metadata to manage the heap.
The attacker then sends SIGTERM.
SIGHUP-handler is interrupted, but syslog's malloc call is still executing and has not finished modifying its metadata.
The SIGTERM handler is invoked.
SIGTERM-handler records the log message using syslog(), then frees the logMessage variable.
At this point, the state of the heap is uncertain, because malloc is still modifying the metadata for the heap; the metadata might be in an inconsistent state. The SIGTERM-handler call to free() is assuming that the metadata is inconsistent, possibly causing it to write data to the wrong location while managing the heap. The result is memory corruption, which could lead to a crash or even code execution, depending on the circumstances under which the code is running.
Note that this is an adaptation of a classic example as originally presented by Michal Zalewski [REF-360]; the original example was shown to be exploitable for code execution.
Also note that the strdup(argv[1]) call contains a potential buffer over-read (CWE-126) if the program is called without any arguments, because argc would be 0, and argv[1] would point outside the bounds of the array.
Example 2
The following code registers a signal handler with multiple signals in order to log when a specific event occurs and to free associated memory before exiting.
This is just one possible exploitation of the above code. As another example, the syslog call may use malloc calls which are not async-signal safe. This could cause corruption of the heap management structures. For more details, consult the example within "Delivering Signals for Fun and Profit" [REF-360].
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Signal handler does not disable other signal handlers, allowing it to be interrupted, causing other functionality to access files/etc. with raised privileges
SIGCHLD signal to FTP server can cause crash under heavy load while executing non-reentrant functions like malloc/free.
Functional Areas
Signals
Interprocess Communication
Affected Resources
System Process
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 13: Race Conditions." Page 205. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 13, "Signal Vulnerabilities", Page 791. 1st Edition. Addison Wesley. 2006.
CWE-479: Signal Handler Use of a Non-reentrant Function
Weakness ID: 479
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product defines a signal handler that calls a non-reentrant function.
Extended Description
Non-reentrant functions are functions that cannot safely be called, interrupted, and then recalled before the first call has finished without resulting in memory corruption. This can lead to an unexpected system state and unpredictable results with a variety of potential consequences depending on context, including denial of service and code execution.
Many functions are not reentrant, but some of them can result in the corruption of memory if they are used in a signal handler. The function call syslog() is an example of this. In order to perform its functionality, it allocates a small amount of memory as "scratch space." If syslog() is suspended by a signal call and the signal handler calls syslog(), the memory used by both of these functions enters an undefined, and possibly, exploitable state. Implementations of malloc() and free() manage metadata in global structures in order to track which memory is allocated versus which memory is available, but they are non-reentrant. Simultaneous calls to these functions can cause corruption of the metadata.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
It may be possible to execute arbitrary code through the use of a write-what-where condition.
Modify Memory; Modify Application Data
Scope: Integrity
Signal race conditions often result in data corruption.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Require languages or libraries that provide reentrant functionality, or otherwise make it easier to avoid this weakness.
Architecture and Design
Design signal handlers to only set flags rather than perform complex functionality.
Implementation
Ensure that non-reentrant functions are not found in signal handlers.
Implementation
Use sanity checks to reduce the timing window for exploitation of race conditions. This is only a partial solution, since many attacks might fail, but other attacks still might work within the narrower window, even accidentally.
Effectiveness: Defense in Depth
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Use of a Non-reentrant Function in a Concurrent Context
ChildOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Signal Handler with Functionality that is not Asynchronous-Safe
CanPrecede
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
Low
Demonstrative Examples
Example 1
In this example, a signal handler uses syslog() to log a message:
If the execution of the first call to the signal handler is suspended after invoking syslog(), and the signal handler is called a second time, the memory allocated by syslog() enters an undefined, and possibly, exploitable state.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
SIGCHLD signal to FTP server can cause crash under heavy load while executing non-reentrant functions like malloc/free.
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Affected Resources
System Process
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Unsafe function call from a signal handler
CERT C Secure Coding
SIG30-C
Exact
Call only asynchronous-safe functions within signal handlers
CERT C Secure Coding
SIG34-C
Do not call signal() from within interruptible signal handlers
The CERT Oracle Secure Coding Standard for Java (2011)
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 13, "Signal Vulnerabilities", Page 791. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses a signed primitive and performs a cast to an unsigned primitive, which can produce an unexpected value if the value of the signed primitive can not be represented using an unsigned primitive.
Extended Description
It is dangerous to rely on implicit casts between signed and unsigned numbers because the result can take on an unexpected value and violate assumptions made by the program.
Often, functions will return negative values to indicate a failure. When the result of a function is to be used as a size parameter, using these negative return values can have unexpected results. For example, if negative size values are passed to the standard memory copy or allocation functions they will be implicitly cast to a large unsigned value. This may lead to an exploitable buffer overflow or underflow condition.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Unexpected State
Scope: Integrity
Conversion between signed and unsigned values can lead to a variety of errors, but from a security standpoint is most commonly associated with integer overflow and buffer overflow vulnerabilities.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Demonstrative Examples
Example 1
In this example the variable amount can hold a negative value when it is returned. Because the function is declared to return an unsigned int, amount will be implicitly converted to unsigned.
(bad code)
Example Language: C
unsigned int readdata () {
int amount = 0; ... if (result == ERROR) amount = -1; ... return amount;
}
If the error condition in the code above is met, then the return value of readdata() will be 4,294,967,295 on a system that uses 32-bit integers.
Example 2
In this example, depending on the return value of accecssmainframe(), the variable amount can hold a negative value when it is returned. Because the function is declared to return an unsigned value, amount will be implicitly cast to an unsigned number.
The code performs a check to make sure that the packet does not contain too many headers. However, numHeaders is defined as a signed int, so it could be negative. If the incoming packet specifies a value such as -3, then the malloc calculation will generate a negative number (say, -300 if each header can be a maximum of 100 bytes). When this result is provided to malloc(), it is first converted to a size_t type. This conversion then produces a large value such as 4294966996, which may cause malloc() to fail or to allocate an extremely large amount of memory (CWE-195). With the appropriate negative numbers, an attacker could trick malloc() into using a very small positive number, which then allocates a buffer that is much smaller than expected, potentially leading to a buffer overflow.
Example 4
This example processes user input comprised of a series of variable-length structures. The first 2 bytes of input dictate the size of the structure to be processed.
(bad code)
Example Language: C
char* processNext(char* strm) {
char buf[512]; short len = *(short*) strm; strm += sizeof(len); if (len <= 512) {
The programmer has set an upper bound on the structure size: if it is larger than 512, the input will not be processed. The problem is that len is a signed short, so the check against the maximum structure length is done with signed values, but len is converted to an unsigned integer for the call to memcpy() and the negative bit will be extended to result in a huge value for the unsigned integer. If len is negative, then it will appear that the structure has an appropriate size (the if branch will be taken), but the amount of memory copied by memcpy() will be quite large, and the attacker will be able to overflow the stack with data in strm.
Example 5
In the following example, it is possible to request that memcpy move a much larger segment of memory than assumed:
(bad code)
Example Language: C
int returnChunkSize(void *) {
/* if chunk info is valid, return the size of usable memory,
If returnChunkSize() happens to encounter an error it will return -1. Notice that the return value is not checked before the memcpy operation (CWE-252), so -1 can be passed as the size argument to memcpy() (CWE-805). Because memcpy() assumes that the value is unsigned, it will be interpreted as MAXINT-1 (CWE-195), and therefore will copy far more memory than is likely available to the destination buffer (CWE-787, CWE-788).
Example 6
This example shows a typical attempt to parse a string with an error resulting from a difference in assumptions between the caller to a function and the function's action.
(bad code)
Example Language: C
int proc_msg(char *s, int msg_len)
{
// Note space at the end of the string - assume all strings have preamble with space
int pre_len = sizeof("preamble: ");
char buf[pre_len - msg_len]; ... Do processing here if we get this far
}
char *s = "preamble: message\n";
char *sl = strchr(s, ':'); // Number of characters up to ':' (not including space)
int jnklen = sl == NULL ? 0 : sl - s; // If undefined pointer, use zero length
int ret_val = proc_msg ("s", jnklen); // Violate assumption of preamble length, end up with negative value, blow out stack
The buffer length ends up being -1, resulting in a blown out stack. The space character after the colon is included in the function calculation, but not in the caller's calculation. This, unfortunately, is not usually so obvious but exists in an obtuse series of calculations.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Font rendering library does not properly
handle assigning a signed short value to an unsigned
long (CWE-195), leading to an integer wraparound
(CWE-190), causing too small of a buffer (CWE-131),
leading to an out-of-bounds write
(CWE-787).
Chain: integer signedness error (CWE-195) passes signed comparison, leading to heap overflow (CWE-122)
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Signed to unsigned conversion error
Software Fault Patterns
SFP1
Glitch in computation
CERT C Secure Coding
INT31-C
CWE More Specific
Ensure that integer conversions do not result in lost or misinterpreted data
References
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 6, "Type Conversions", Page 223. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
A stack-based buffer overflow condition is a condition where the buffer being overwritten is allocated on the stack (i.e., is a local variable or, rarely, a parameter to a function).
Alternate Terms
Stack Overflow
"Stack Overflow" is often used to mean the same thing as stack-based buffer overflow, however it is also used on occasion to mean stack exhaustion, usually a result from an excessively recursive function call. Due to the ambiguity of the term, use of stack overflow to describe either circumstance is discouraged.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Buffer overflows generally lead to crashes. Other attacks leading to lack of availability are possible, including putting the program into an infinite loop.
Modify Memory; Execute Unauthorized Code or Commands; Bypass Protection Mechanism
Scope: Integrity, Confidentiality, Availability, Access Control
Buffer overflows often can be used to execute arbitrary code, which is usually outside the scope of a program's implicit security policy.
Modify Memory; Execute Unauthorized Code or Commands; Bypass Protection Mechanism; Other
Scope: Integrity, Confidentiality, Availability, Access Control, Other
When the consequence is arbitrary code execution, this can often be used to subvert any other security service.
Potential Mitigations
Phase(s)
Mitigation
Operation; Build and Compilation
Strategy: Environment Hardening
Use automatic buffer overflow detection mechanisms that are offered by certain compilers or compiler extensions. Examples include: the Microsoft Visual Studio /GS flag, Fedora/Red Hat FORTIFY_SOURCE GCC flag, StackGuard, and ProPolice, which provide various mechanisms including canary-based detection and range/index checking.
D3-SFCV (Stack Frame Canary Validation) from D3FEND [REF-1334] discusses canary-based detection in detail.
Effectiveness: Defense in Depth
Note:
This is not necessarily a complete solution, since these mechanisms only detect certain types of overflows. In addition, the result is still a denial of service, since the typical response is to exit the application.
Architecture and Design
Use an abstraction library to abstract away risky APIs. Not a complete solution.
Implementation
Implement and perform bounds checking on input.
Implementation
Do not use dangerous functions such as gets. Use safer, equivalent functions which check for boundary errors.
Operation; Build and Compilation
Strategy: Environment Hardening
Run or compile the software using features or extensions that randomly arrange the positions of a program's executable and libraries in memory. Because this makes the addresses unpredictable, it can prevent an attacker from reliably jumping to exploitable code.
Examples include Address Space Layout Randomization (ASLR) [REF-58] [REF-60] and Position-Independent Executables (PIE) [REF-64]. Imported modules may be similarly realigned if their default memory addresses conflict with other modules, in a process known as "rebasing" (for Windows) and "prelinking" (for Linux) [REF-1332] using randomly generated addresses. ASLR for libraries cannot be used in conjunction with prelink since it would require relocating the libraries at run-time, defeating the whole purpose of prelinking.
For more information on these techniques see D3-SAOR (Segment Address Offset Randomization) from D3FEND [REF-1335].
Effectiveness: Defense in Depth
Note: These techniques do not provide a complete solution. For instance, exploits frequently use a bug that discloses memory addresses in order to maximize reliability of code execution [REF-1337]. It has also been shown that a side-channel attack can bypass ASLR [REF-1333]
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
There are generally several security-critical data on an execution stack that can lead to arbitrary code execution. The most prominent is the stored return address, the memory address at which execution should continue once the current function is finished executing. The attacker can overwrite this value with some memory address to which the attacker also has write access, into which they place arbitrary code to be run with the full privileges of the vulnerable program. Alternately, the attacker can supply the address of an important call, for instance the POSIX system() call, leaving arguments to the call on the stack. This is often called a return into libc exploit, since the attacker generally forces the program to jump at return time into an interesting routine in the C standard library (libc). Other important data commonly on the stack include the stack pointer and frame pointer, two values that indicate offsets for computing memory addresses. Modifying those values can often be leveraged into a "write-what-where" condition.
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
While buffer overflow examples can be rather complex, it is possible to have very simple, yet still exploitable, stack-based buffer overflows:
(bad code)
Example Language: C
#define BUFSIZE 256 int main(int argc, char **argv) {
char buf[BUFSIZE]; strcpy(buf, argv[1]);
}
The buffer size is fixed, but there is no guarantee the string in argv[1] will not exceed this size and cause an overflow.
Example 2
This example takes an IP address from a user, verifies that it is well formed and then looks up the hostname and copies it into a buffer.
This function allocates a buffer of 64 bytes to store the hostname, however there is no guarantee that the hostname will not be larger than 64 bytes. If an attacker specifies an address which resolves to a very large hostname, then the function may overwrite sensitive data or even relinquish control flow to the attacker.
Note that this example also contains an unchecked return value (CWE-252) that can lead to a NULL pointer dereference (CWE-476).
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Stack-based buffer overflows in SFK for wifi chipset used for IoT/embedded devices, as exploited in the wild per CISA KEV.
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Other
Stack-based buffer overflows can instantiate in return address overwrites, stack pointer overwrites or frame pointer overwrites. They can also be considered function pointer overwrites, array indexer overwrites or write-what-where condition, etc.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Stack overflow
Software Fault Patterns
SFP8
Faulty Buffer Access
CERT C Secure Coding
ARR38-C
Imprecise
Guarantee that library functions do not form invalid pointers
CERT C Secure Coding
STR31-C
CWE More Specific
Guarantee that storage for strings has sufficient space for character data and the null terminator
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 5: Buffer Overruns." Page 89. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 3, "Nonexecutable Stack", Page 76. 1st Edition. Addison Wesley. 2006.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 5, "Protection Mechanisms", Page 189. 1st Edition. Addison Wesley. 2006.
CWE-690: Unchecked Return Value to NULL Pointer Dereference
Weakness ID: 690
(Structure: Chain)
Chain - a Compound Element that is a sequence of two or more separate weaknesses that can be closely linked together within software. One weakness, X, can directly create the conditions that are necessary to cause another weakness, Y, to enter a vulnerable condition. When this happens, CWE refers to X as "primary" to Y, and Y is "resultant" from X. Chains can involve more than two weaknesses, and in some cases, they might have a tree-like structure.
Vulnerability Mapping:DISCOURAGEDThis CWE ID should not be used to map to real-world vulnerabilities
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product does not check for an error after calling a function that can return with a NULL pointer if the function fails, which leads to a resultant NULL pointer dereference.
Extended Description
While unchecked return value weaknesses are not limited to returns of NULL pointers (see the examples in CWE-252), functions often return NULL to indicate an error status. When this error condition is not checked, a NULL pointer dereference can occur.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
DoS: Crash, Exit, or Restart
Scope: Availability
Execute Unauthorized Code or Commands; Read Memory; Modify Memory
Scope: Integrity, Confidentiality, Availability
In rare circumstances, when NULL is equivalent to the 0x0 memory address and privileged code can access it, then writing or reading memory is possible, which may lead to code execution.
Chain Components
Nature
Type
ID
Name
StartsWith
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
A typical occurrence of this weakness occurs when an application includes user-controlled input to a malloc() call. The related code might be correct with respect to preventing buffer overflows, but if a large value is provided, the malloc() will fail due to insufficient memory. This problem also frequently occurs when a parsing routine expects that certain elements will always be present. If malformed input is provided, the parser might return NULL. For example, strtok() can return NULL.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The code below makes a call to the getUserName() function but doesn't check the return value before dereferencing (which may cause a NullPointerException).
(bad code)
Example Language: Java
String username = getUserName(); if (username.equals(ADMIN_USER)) {
...
}
Example 2
This example takes an IP address from a user, verifies that it is well formed and then looks up the hostname and copies it into a buffer.
If an attacker provides an address that appears to be well-formed, but the address does not resolve to a hostname, then the call to gethostbyaddr() will return NULL. Since the code does not check the return value from gethostbyaddr (CWE-252), a NULL pointer dereference (CWE-476) would then occur in the call to strcpy().
Note that this code is also vulnerable to a buffer overflow (CWE-119).
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
URI parsing API sets argument to NULL when a parsing failure occurs, such as when the Referer header is missing a hostname, leading to NULL dereference.
chain: unchecked return value can lead to NULL dereference
Detection
Methods
Method
Details
Black Box
This typically occurs in rarely-triggered error conditions, reducing the chances of detection during black box testing.
White Box
Code analysis can require knowledge of API behaviors for library functions that might return NULL, reducing the chances of detection when unknown libraries are used.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product performs an operation on a number that causes it to be sign extended when it is transformed into a larger data type. When the original number is negative, this can produce unexpected values that lead to resultant weaknesses.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory; Modify Memory; Other
Scope: Integrity, Confidentiality, Availability, Other
When an unexpected sign extension occurs in code that operates directly on memory buffers, such as a size value or a memory index, then it could cause the program to write or read outside the boundaries of the intended buffer. If the numeric value is associated with an application-level resource, such as a quantity or price for a product in an e-commerce site, then the sign extension could produce a value that is much higher (or lower) than the application's allowable range.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Avoid using signed variables if you don't need to represent negative values. When negative values are needed, perform validation after you save those values to larger data types, or before passing them to functions that are expecting unsigned values.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
The following code reads a maximum size and performs a sanity check on that size. It then performs a strncpy, assuming it will not exceed the boundaries of the array. While the use of "short s" is forced in this particular example, short int's are frequently used within real-world code, such as code that processes structured data.
(bad code)
Example Language: C
int GetUntrustedInt () {
return(0x0000FFFF);
}
void main (int argc, char **argv) {
char path[256]; char *input; int i; short s; unsigned int sz;
i = GetUntrustedInt(); s = i; /* s is -1 so it passes the safety check - CWE-697 */ if (s > 256) {
DiePainfully("go away!\n");
}
/* s is sign-extended and saved in sz */ sz = s;
/* output: i=65535, s=-1, sz=4294967295 - your mileage may vary */ printf("i=%d, s=%d, sz=%u\n", i, s, sz);
input = GetUserInput("Enter pathname:");
/* strncpy interprets s as unsigned int, so it's treated as MAX_INT (CWE-195), enabling buffer overflow (CWE-119) */ strncpy(path, input, s); path[255] = '\0'; /* don't want CWE-170 */ printf("Path is: %s\n", path);
}
This code first exhibits an example of CWE-839, allowing "s" to be a negative number. When the negative short "s" is converted to an unsigned integer, it becomes an extremely large positive integer. When this converted integer is used by strncpy() it will lead to a buffer overflow (CWE-119).
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Product uses "char" type for input character. When char is implemented as a signed type, ASCII value 0xFF (255), a sign extension produces a -1 value that is treated as a program-specific separator value, effectively disabling a length check and leading to a buffer overflow. This is also a multiple interpretation error.
chain: signed short width value in image processor is sign extended during conversion to unsigned int, which leads to integer overflow and heap-based buffer overflow.
Sign extension when manipulating Pascal-style strings leads to integer overflow and improper memory copy.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
Sign extension errors can lead to buffer overflows and other memory-based problems. They are also likely to be factors in other weaknesses that are not based on memory operations, but rely on numeric calculation.
Maintenance
This entry is closely associated with signed-to-unsigned conversion errors (CWE-195) and other numeric errors. These relationships need to be more closely examined within CWE.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Sign extension error
Software Fault Patterns
SFP1
Glitch in computation
CERT C Secure Coding
INT31-C
CWE More Specific
Ensure that integer conversions do not result in lost or misinterpreted data
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses an unsigned primitive and performs a cast to a signed primitive, which can produce an unexpected value if the value of the unsigned primitive can not be represented using a signed primitive.
Extended Description
Although less frequent an issue than signed-to-unsigned conversion, unsigned-to-signed conversion can be the perfect precursor to dangerous buffer underwrite conditions that allow attackers to move down the stack where they otherwise might not have access in a normal buffer overflow condition. Buffer underwrites occur frequently when large unsigned values are cast to signed values, and then used as indexes into a buffer or for pointer arithmetic.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
DoS: Crash, Exit, or Restart
Scope: Availability
Incorrect sign conversions generally lead to undefined behavior, and therefore crashes.
Modify Memory
Scope: Integrity
If a poor cast lead to a buffer overflow or similar condition, data integrity may be affected.
Execute Unauthorized Code or Commands; Bypass Protection Mechanism
Scope: Integrity, Confidentiality, Availability, Access Control
Improper signed-to-unsigned conversions without proper checking can sometimes trigger buffer overflows which can be used to execute arbitrary code. This is usually outside the scope of a program's implicit security policy.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Choose a language which is not subject to these casting flaws.
Architecture and Design
Design object accessor functions to implicitly check values for valid sizes. Ensure that all functions which will be used as a size are checked previous to use as a size. If the language permits, throw exceptions rather than using in-band errors.
Implementation
Error check the return values of all functions. Be aware of implicit casts made, and use unsigned variables for sizes if at all possible.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
CanAlsoBe
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 6, "Type Conversions", Page 223. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product reuses or references memory after it has been freed. At some point afterward, the memory may be allocated again and saved in another pointer, while the original pointer references a location somewhere within the new allocation. Any operations using the original pointer are no longer valid because the memory "belongs" to the code that operates on the new pointer.
Alternate Terms
Dangling pointer
a pointer that no longer points to valid memory, often after it has been freed
UAF
commonly used acronym for Use After Free
Use-After-Free
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory
Scope: Integrity
The use of previously freed memory may corrupt valid data, if the memory area in question has been allocated and used properly elsewhere.
DoS: Crash, Exit, or Restart
Scope: Availability
If chunk consolidation occurs after the use of previously freed data, the process may crash when invalid data is used as chunk information.
Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
If malicious data is entered before chunk consolidation can take place, it may be possible to take advantage of a write-what-where primitive to execute arbitrary code. If the newly allocated data happens to hold a class, in C++ for example, various function pointers may be scattered within the heap data. If one of these function pointers is overwritten with an address to valid shellcode, execution of arbitrary code can be achieved.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Strategy: Language Selection
Choose a language that provides automatic memory management.
Implementation
Strategy: Attack Surface Reduction
When freeing pointers, be sure to set them to NULL once they are freed. However, the utilization of multiple or complex data structures may lower the usefulness of this strategy.
Effectiveness: Defense in Depth
Note: If a bug causes an attempted access of this pointer, then a NULL dereference could still lead to a crash or other unexpected behavior, but it will reduce or eliminate the risk of code execution.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Concurrent Execution using Shared Resource with Improper Synchronization ('Race Condition')
CanFollow
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Check for Unusual or Exceptional Conditions
CanFollow
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Unintended Reentrant Invocation of Non-reentrant Code Via Nested Calls
CanPrecede
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
CanPrecede
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Operation on a Resource after Expiration or Release
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Operation on a Resource after Expiration or Release
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Operation on a Resource after Expiration or Release
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
The following code illustrates a use after free error:
(bad code)
Example Language: C
char* ptr = (char*)malloc (SIZE); if (err) {
abrt = 1; free(ptr);
} ... if (abrt) {
logError("operation aborted before commit", ptr);
}
When an error occurs, the pointer is immediately freed. However, this pointer is later incorrectly used in the logError function.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: two threads in a web browser use the same resource (CWE-366), but one of those threads can destroy the resource before the other has completed (CWE-416).
Chain: race condition (CWE-362) from improper handling of a page transition in web client while an applet is loading (CWE-368) leads to use after free (CWE-416)
Chain: A multi-threaded race condition (CWE-367) allows attackers to cause two threads to process the same RPC request, which causes a use-after-free (CWE-416) in one thread
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
If the product accesses a previously-freed pointer, then it means that a separate weakness or error already occurred previously, such as a race condition, an unexpected or poorly handled error condition, confusion over which part of the program is responsible for freeing the memory, performing the free too soon, etc.
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Affected Resources
Memory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
SEI CERT C Coding Standard - Guidelines 08. Memory Management (MEM)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2019 CWE Top 25 Most Dangerous Software Errors
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2021 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2020 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2023 CWE Top 25 Most Dangerous Software Weaknesses
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Weaknesses in the 2024 CWE Top 25 Most Dangerous Software Weaknesses
Vulnerability Mapping Notes
Usage
ALLOWED
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
ISA/IEC 62443
Part 4-1
Req SI-1
7 Pernicious Kingdoms
Use After Free
CLASP
Using freed memory
CERT C Secure Coding
MEM00-C
Allocate and free memory in the same module, at the same level of abstraction
CERT C Secure Coding
MEM01-C
Store a new value in pointers immediately after free()
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses or accesses a file descriptor after it has been closed.
Extended Description
After a file descriptor for a particular file or device has been released, it can be reused. The code might not write to the original file, since the reused file descriptor might reference a different file or device.
Alternate Terms
Stale file descriptor
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Files or Directories
Scope: Confidentiality
The program could read data from the wrong file.
DoS: Crash, Exit, or Restart
Scope: Availability
Accessing a file descriptor that has been closed can cause a crash.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Sometimes Prevalent)
C++
(Sometimes Prevalent)
Class: Not Language-Specific
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CERT C Secure Coding
FIO46-C
Exact
Do not access a closed file
Content
History
Submissions
Submission Date
Submitter
Organization
2012-12-21
(CWE 2.4, 2013-02-21)
CWE Content Team
MITRE
New weakness based on discussion on the CWE research list in December 2012.
CWE-134: Use of Externally-Controlled Format String
Weakness ID: 134
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses a function that accepts a format string as an argument, but the format string originates from an external source.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Memory
Scope: Confidentiality
Format string problems allow for information disclosure which can severely simplify exploitation of the program.
Modify Memory; Execute Unauthorized Code or Commands
Scope: Integrity, Confidentiality, Availability
Format string problems can result in the execution of arbitrary code, buffer overflows, denial of service, or incorrect data representation.
Potential Mitigations
Phase(s)
Mitigation
Requirements
Choose a language that is not subject to this flaw.
Implementation
Ensure that all format string functions are passed a static string which cannot be controlled by the user, and that the proper number of arguments are always sent to that function as well. If at all possible, use functions that do not support the %n operator in format strings. [REF-116] [REF-117]
Build and Compilation
Run compilers and linkers with high warning levels, since they may detect incorrect usage.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Weaknesses for Simplified Mapping of Published Vulnerabilities" (View-1003)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Relevant to the view "Seven Pernicious Kingdoms" (View-700)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
The programmer rarely intends for a format string to be externally-controlled at all. This weakness is frequently introduced in code that constructs log messages, where a constant format string is omitted.
Implementation
In cases such as localization and internationalization, the language-specific message repositories could be an avenue for exploitation, but the format string issue would be resultant, since attacker control of those repositories would also allow modification of message length, format, and content.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Perl
(Rarely Prevalent)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
The following program prints a string provided as an argument.
The example is exploitable, because of the call to printf() in the printWrapper() function. Note: The stack buffer was added to make exploitation more simple.
Example 2
The following code copies a command line argument into a buffer using snprintf().
(bad code)
Example Language: C
int main(int argc, char **argv){
char buf[128]; ... snprintf(buf,128,argv[1]);
}
This code allows an attacker to view the contents of the stack and write to the stack using a command line argument containing a sequence of formatting directives. The attacker can read from the stack by providing more formatting directives, such as %x, than the function takes as arguments to be formatted. (In this example, the function takes no arguments to be formatted.) By using the %n formatting directive, the attacker can write to the stack, causing snprintf() to write the number of bytes output thus far to the specified argument (rather than reading a value from the argument, which is the intended behavior). A sophisticated version of this attack will use four staggered writes to completely control the value of a pointer on the stack.
Example 3
Certain implementations make more advanced attacks even easier by providing format directives that control the location in memory to read from or write to. An example of these directives is shown in the following code, written for glibc:
(bad code)
Example Language: C
printf("%d %d %1$d %1$d\n", 5, 9);
This code produces the following output: 5 9 5 5 It is also possible to use half-writes (%hn) to accurately control arbitrary DWORDS in memory, which greatly reduces the complexity needed to execute an attack that would otherwise require four staggered writes, such as the one mentioned in a separate example.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: untrusted search path enabling resultant format string by loading malicious internationalization messages
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Automated Static Analysis
This weakness can often be detected using automated static analysis tools. Many modern tools use data flow analysis or constraint-based techniques to minimize the number of false positives.
Black Box
Since format strings often occur in rarely-occurring erroneous conditions (e.g. for error message logging), they can be difficult to detect using black box methods. It is highly likely that many latent issues exist in executables that do not have associated source code (or equivalent source.
Effectiveness: Limited
Automated Static Analysis - Binary or Bytecode
According to SOAR, the following detection techniques may be useful:
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
CERT C++ Secure Coding Section 09 - Input Output (FIO)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Applicable Platform
This weakness is possible in any programming language that support format strings.
Research Gap
Format string issues are under-studied for languages other than C. Memory or disk consumption, control flow or variable alteration, and data corruption may result from format string exploitation in applications written in other languages such as Perl, PHP, Python, etc.
Other
In some circumstances, such as internationalization, the set of format strings is externally controlled by design. If the source of these format strings is trusted (e.g. only contained in library files that are only modifiable by the system administrator), then the external control might not itself pose a vulnerability.
While Format String vulnerabilities typically fall under the Buffer Overflow category, technically they are not overflowed buffers. The Format String vulnerability is fairly new (circa 1999) and stems from the fact that there is no realistic way for a function that takes a variable number of arguments to determine just how many arguments were passed in. The most common functions that take a variable number of arguments, including C-runtime functions, are the printf() family of calls. The Format String problem appears in a number of ways. A *printf() call without a format specifier is dangerous and can be exploited. For example, printf(input); is exploitable, while printf(y, input); is not exploitable in that context. The result of the first call, used incorrectly, allows for an attacker to be able to peek at stack memory since the input string will be used as the format specifier. The attacker can stuff the input string with format specifiers and begin reading stack values, since the remaining parameters will be pulled from the stack. Worst case, this improper use may give away enough control to allow an arbitrary value (or values in the case of an exploit program) to be written into the memory of the running program.
Frequently targeted entities are file names, process names, identifiers.
Format string problems are a classic C/C++ issue that are now rare due to the ease of discovery. One main reason format string vulnerabilities can be exploited is due to the %n operator. The %n operator will write the number of characters, which have been printed by the format string therefore far, to the memory pointed to by its argument. Through skilled creation of a format string, a malicious user may use values on the stack to create a write-what-where condition. Once this is achieved, they can execute arbitrary code. Other operators can be used as well; for example, a %9999s operator could also trigger a buffer overflow, or when used in file-formatting functions like fprintf, it can generate a much larger output than intended.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
PLOVER
Format string vulnerability
7 Pernicious Kingdoms
Format String
CLASP
Format string problem
CERT C Secure Coding
FIO30-C
Exact
Exclude user input from format strings
CERT C Secure Coding
FIO47-C
CWE More Specific
Use valid format strings
OWASP Top Ten 2004
A1
CWE More Specific
Unvalidated Input
WASC
6
Format String
The CERT Oracle Secure Coding Standard for Java (2011)
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 6: Format String Problems." Page 109. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 8, "C Format Strings", Page 422. 1st Edition. Addison Wesley. 2006.
CWE-474: Use of Function with Inconsistent Implementations
Weakness ID: 474
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The code uses a function that has inconsistent implementations across operating systems and versions.
Extended Description
The use of inconsistent implementations can cause changes in behavior when the code is ported or built under a different environment than the programmer expects, which can lead to security problems in some cases.
The implementation of many functions varies by platform, and at times, even by different versions of the same platform. Implementation differences can include:
Slight differences in the way parameters are interpreted leading to inconsistent results.
Some implementations of the function carry significant security risks.
The function might not be defined on all platforms.
The function might change which return codes it can provide, or change the meaning of its return codes.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Quality Degradation; Varies by Context
Scope: Other
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design; Requirements
Do not accept inconsistent behavior from the API specifications when the deviant behavior increase the risk level.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Reliance on Undefined, Unspecified, or Implementation-Defined Behavior
ParentOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
PHP
(Often Prevalent)
Class: Not Language-Specific
(Undetermined Prevalence)
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Indirect
(where the weakness is a quality issue that might indirectly make it easier to introduce security-relevant weaknesses or make them more difficult to detect)
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
CWE-558: Use of getlogin() in Multithreaded Application
Weakness ID: 558
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product uses the getlogin() function in a multithreaded context, potentially causing it to return incorrect values.
Extended Description
The getlogin() function returns a pointer to a string that contains the name of the user associated with the calling process. The function is not reentrant, meaning that if it is called from another process, the contents are not locked out and the value of the string can be changed by another process. This makes it very risky to use because the username can be changed by other processes, so the results of the function cannot be trusted.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Application Data; Bypass Protection Mechanism; Other
Scope: Integrity, Access Control, Other
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Using names for security purposes is not advised. Names are easy to forge and can have overlapping user IDs, potentially causing confusion or impersonation.
Implementation
Use getlogin_r() instead, which is reentrant, meaning that other processes are locked out from changing the username.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Use of a Non-reentrant Function in a Concurrent Context
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Demonstrative Examples
Example 1
The following code relies on getlogin() to determine whether or not a user is trusted. It is easily subverted.
(bad code)
Example Language: C
pwd = getpwnam(getlogin()); if (isTrustedGroup(pwd->pw_gid)) {
allow();
} else {
deny();
}
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product accidentally uses the wrong operator, which changes the logic in security-relevant ways.
Extended Description
These types of errors are generally the result of a typo by the programmer.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Alter Execution Logic
Scope: Other
This weakness can cause unintended logic to be executed and other unexpected application behavior.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Sometimes Prevalent)
C++
(Sometimes Prevalent)
Perl
(Sometimes Prevalent)
Class: Not Language-Specific
(Undetermined Prevalence)
Likelihood Of Exploit
Low
Demonstrative Examples
Example 1
The following C/C++ and C# examples attempt to validate an int input parameter against the integer value 100.
(bad code)
Example Language: C
int isValid(int value) {
if (value=100) {
printf("Value is valid\n"); return(1);
} printf("Value is not valid\n"); return(0);
}
(bad code)
Example Language: C#
bool isValid(int value) {
if (value=100) {
Console.WriteLine("Value is valid."); return true;
} Console.WriteLine("Value is not valid."); return false;
}
However, the expression to be evaluated in the if statement uses the assignment operator "=" rather than the comparison operator "==". The result of using the assignment operator instead of the comparison operator causes the int variable to be reassigned locally and the expression in the if statement will always evaluate to the value on the right hand side of the expression. This will result in the input value not being properly validated, which can cause unexpected results.
Example 2
The following C/C++ example shows a simple implementation of a stack that includes methods for adding and removing integer values from the stack. The example uses pointers to add and remove integer values to the stack array variable.
(bad code)
Example Language: C
#define SIZE 50 int *tos, *p1, stack[SIZE];
void push(int i) {
p1++; if(p1==(tos+SIZE)) {
// Print stack overflow error message and exit
} *p1 == i;
}
int pop(void) {
if(p1==tos) {
// Print stack underflow error message and exit
} p1--; return *(p1+1);
}
int main(int argc, char *argv[]) {
// initialize tos and p1 to point to the top of stack tos = stack; p1 = stack; // code to add and remove items from stack ... return 0;
}
The push method includes an expression to assign the integer value to the location in the stack pointed to by the pointer variable.
However, this expression uses the comparison operator "==" rather than the assignment operator "=". The result of using the comparison operator instead of the assignment operator causes erroneous values to be entered into the stack and can cause unexpected results.
Example 3
The example code below is taken from the CVA6 processor core of the HACK@DAC'21 buggy OpenPiton SoC. Debug access allows users to access internal hardware registers that are otherwise not exposed for user access or restricted access through access control protocols. Hence, requests to enter debug mode are checked and authorized only if the processor has sufficient privileges. In addition, debug accesses are also locked behind password checkers. Thus, the processor enters debug mode only when the privilege level requirement is met, and the correct debug password is provided.
The following code [REF-1377] illustrates an instance of a vulnerable implementation of debug mode. The core correctly checks if the debug requests have sufficient privileges and enables the debug_mode_d and debug_mode_q signals. It also correctly checks for debug password and enables umode_i signal.
(bad code)
Example Language: Verilog
module csr_regfile #(
...
// check that we actually want to enter debug depending on the privilege level we are currently in
unique case (priv_lvl_o)
However, it grants debug access and changes the privilege level, priv_lvl_o, even when one of the two checks is satisfied and the other is not. Because of this, debug access can be granted by simply requesting with sufficient privileges (i.e., debug_mode_q is enabled) and failing the password check (i.e., umode_i is disabled). This allows an attacker to bypass the debug password checking and gain debug access to the core, compromising the security of the processor.
A fix to this issue is to only change the privilege level of the processor when both checks are satisfied, i.e., the request has enough privileges (i.e., debug_mode_q is enabled) and the password checking is successful (i.e., umode_i is enabled) [REF-1378].
(good code)
Example Language: Verilog
module csr_regfile #(
...
// check that we actually want to enter debug depending on the privilege level we are currently in
unique case (priv_lvl_o)
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: data visualization program written in PHP uses the "!=" operator instead of the type-strict "!==" operator (CWE-480) when validating hash values, potentially leading to an incorrect type conversion (CWE-704)
Chain: Python-based HTTP Proxy server uses the wrong boolean operators (CWE-480) causing an incorrect comparison (CWE-697) that identifies an authN failure if all three conditions are met instead of only one, allowing bypass of the proxy authentication (CWE-1390)
Detection
Methods
Method
Details
Automated Static Analysis
This weakness can be found easily using static analysis. However in some cases an operator might appear to be incorrect, but is actually correct and reflects unusual logic within the program.
Manual Static Analysis
This weakness can be found easily using static analysis. However in some cases an operator might appear to be incorrect, but is actually correct and reflects unusual logic within the program.
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 49 - Miscellaneous (MSC)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
Comprehensive Categorization: Insufficient Control Flow Management
Vulnerability Mapping Notes
Usage
ALLOWED
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Using the wrong operator
CERT C Secure Coding
EXP45-C
CWE More Abstract
Do not perform assignments in selection statements
CERT C Secure Coding
EXP46-C
CWE More Abstract
Do not use a bitwise operator with a Boolean-like operand
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product calls a function that can never be guaranteed to work safely.
Extended Description
Certain functions behave in dangerous ways regardless of how they are used. Functions in this category were often implemented without taking security concerns into account. The gets() function is unsafe because it does not perform bounds checking on the size of its input. An attacker can easily send arbitrarily-sized input to gets() and overflow the destination buffer. Similarly, the >> operator is unsafe to use when reading into a statically-allocated character array because it does not perform bounds checking on the size of its input. An attacker can easily send arbitrarily-sized input to the >> operator and overflow the destination buffer.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Varies by Context
Scope: Other
Potential Mitigations
Phase(s)
Mitigation
Implementation; Requirements
Ban the use of dangerous functions. Use their safe equivalent.
Testing
Use grep or static analysis tools to spot usage of dangerous functions.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
The code below calls gets() to read information into a buffer.
(bad code)
Example Language: C
char buf[BUFSIZE]; gets(buf);
The gets() function in C is inherently unsafe.
Example 2
The code below calls the gets() function to read in data from the command line.
(bad code)
Example Language: C
char buf[24]; printf("Please enter your name and press <Enter>\n"); gets(buf); ...
}
However, gets() is inherently unsafe, because it copies all input from STDIN to the buffer without checking size. This allows the user to provide a string that is larger than the buffer size, resulting in an overflow condition.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
FTP client uses inherently insecure gets() function and is setuid root on some systems, allowing buffer overflow
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
CWE-785: Use of Path Manipulation Function without Maximum-sized Buffer
Weakness ID: 785
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product invokes a function for normalizing paths or file names, but it provides an output buffer that is smaller than the maximum possible size, such as PATH_MAX.
Extended Description
Passing an inadequately-sized output buffer to a path manipulation function can result in a buffer overflow. Such functions include realpath(), readlink(), PathAppend(), and others.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; Execute Unauthorized Code or Commands; DoS: Crash, Exit, or Restart
Scope: Integrity, Confidentiality, Availability
Potential Mitigations
Phase(s)
Mitigation
Implementation
Always specify output buffers large enough to handle the maximum-size possible result from path manipulation functions.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "Seven Pernicious Kingdoms" (View-700)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Windows provides a large number of utility functions that manipulate buffers containing filenames. In most cases, the result is returned in a buffer that is passed in as input. (Usually the filename is modified in place.) Most functions require the buffer to be at least MAX_PATH bytes in length, but you should check the documentation for each function individually. If the buffer is not large enough to store the result of the manipulation, a buffer overflow can occur.
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Demonstrative Examples
Example 1
In this example the function creates a directory named "output\<name>" in the current directory and returns a heap-allocated copy of its name.
(bad code)
Example Language: C
char *createOutputDirectory(char *name) {
char outputDirectoryName[128]; if (getCurrentDirectory(128, outputDirectoryName) == 0) {
return null;
} if (!PathAppend(outputDirectoryName, "output")) {
return null;
} if (!PathAppend(outputDirectoryName, name)) {
return null;
} if (SHCreateDirectoryEx(NULL, outputDirectoryName, NULL) != ERROR_SUCCESS) {
return null;
} return StrDup(outputDirectoryName);
}
For most values of the current directory and the name parameter, this function will work properly. However, if the name parameter is particularly long, then the second call to PathAppend() could overflow the outputDirectoryName buffer, which is smaller than MAX_PATH bytes.
Affected Resources
Memory
File or Directory
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Maintenance
This entry is at a much lower level of abstraction than most entries because it is function-specific. It also has significant overlap with other entries that can vary depending on the perspective. For example, incorrect usage could trigger either a stack-based overflow (CWE-121) or a heap-based overflow (CWE-122). The CWE team has not decided how to handle such entries.
Note: this date reflects when the entry was first published. Draft versions of this entry were provided to members of the CWE community and modified before initial publication.
CWE-469: Use of Pointer Subtraction to Determine Size
Weakness ID: 469
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product subtracts one pointer from another in order to determine size, but this calculation can be incorrect if the pointers do not exist in the same memory chunk.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; Read Memory; Execute Unauthorized Code or Commands; Gain Privileges or Assume Identity
There is the potential for arbitrary code execution with privileges of the vulnerable program.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Save an index variable. This is the recommended solution. Rather than subtract pointers from one another, use an index variable of the same size as the pointers in question. Use this variable to "walk" from one pointer to the other and calculate the difference. Always validate this number.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
The following example contains the method size that is used to determine the number of nodes in a linked list. The method is passed a pointer to the head of the linked list.
(bad code)
Example Language: C
struct node {
int data; struct node* next;
};
// Returns the number of nodes in a linked list from
// the given pointer to the head of the list. int size(struct node* head) {
struct node* current = head; struct node* tail; while (current != NULL) {
tail = current; current = current->next;
} return tail - head;
}
// other methods for manipulating the list ...
However, the method creates a pointer that points to the end of the list and uses pointer subtraction to determine the number of nodes in the list by subtracting the tail pointer from the head pointer. There no guarantee that the pointers exist in the same memory area, therefore using pointer subtraction in this way could return incorrect results and allow other unintended behavior. In this example a counter should be used to determine the number of nodes in the list, as shown in the following code.
(good code)
Example Language: C
...
int size(struct node* head) {
struct node* current = head; int count = 0; while (current != NULL) {
count++; current = current->next;
} return count;
}
Detection
Methods
Method
Details
Fuzzing
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 06 - Arrays and the STL (ARR)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Improper pointer subtraction
CERT C Secure Coding
ARR36-C
Exact
Do not subtract or compare two pointers that do not refer to the same array
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product invokes a potentially dangerous function that could introduce a vulnerability if it is used incorrectly, but the function can also be used safely.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Varies by Context; Quality Degradation; Unexpected State
Scope: Other
If the function is used incorrectly, then it could result in security problems.
Potential Mitigations
Phase(s)
Mitigation
Build and Compilation; Implementation
Identify a list of prohibited API functions and prohibit developers from using these functions, providing safer alternatives. In some cases, automatic code analysis tools or the compiler can be instructed to spot use of prohibited functions, such as the "banned.h" include file from Microsoft's SDL. [REF-554] [REF-7]
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
The following code attempts to create a local copy of a buffer to perform some manipulations to the data.
(bad code)
Example Language: C
void manipulate_string(char * string){
char buf[24]; strcpy(buf, string); ...
}
However, the programmer does not ensure that the size of the data pointed to by string will fit in the local buffer and copies the data with the potentially dangerous strcpy() function. This may result in a buffer overflow condition if an attacker can influence the contents of the string parameter.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
(where the weakness exists independent of other weaknesses)
Indirect
(where the weakness is a quality issue that might indirectly make it easier to introduce security-relevant weaknesses or make them more difficult to detect)
Detection
Methods
Method
Details
Automated Static Analysis - Binary or Bytecode
According to SOAR, the following detection techniques may be useful:
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 09 - Input Output (FIO)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
This weakness is different than CWE-242 (Use of Inherently Dangerous Function). CWE-242 covers functions with such significant security problems that they can never be guaranteed to be safe. Some functions, if used properly, do not directly pose a security risk, but can introduce a weakness if not called correctly. These are regarded as potentially dangerous. A well-known example is the strcpy() function. When provided with a destination buffer that is larger than its source, strcpy() will not overflow. However, it is so often misused that some developers prohibit strcpy() entirely.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
7 Pernicious Kingdoms
Dangerous Functions
CERT C Secure Coding
CON33-C
CWE More Abstract
Avoid race conditions when using library functions
CERT C Secure Coding
ENV33-C
CWE More Abstract
Do not call system()
CERT C Secure Coding
ERR07-C
Prefer functions that support error checking over equivalent functions that don't
CERT C Secure Coding
ERR34-C
CWE More Abstract
Detect errors when converting a string to a number
CERT C Secure Coding
FIO01-C
Be careful using functions that use file names for identification
CERT C Secure Coding
MSC30-C
CWE More Abstract
Do not use the rand() function for generating pseudorandom numbers
CERT C Secure Coding
STR31-C
Imprecise
Guarantee that storage for strings has sufficient space for character data and the null terminator
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 8, "C String Handling", Page 388. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The code calls sizeof() on a pointer type, which can be an incorrect calculation if the programmer intended to determine the size of the data that is being pointed to.
Extended Description
The use of sizeof() on a pointer can sometimes generate useful information. An obvious case is to find out the wordsize on a platform. More often than not, the appearance of sizeof(pointer) indicates a bug.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; Read Memory
Scope: Integrity, Confidentiality
This error can often cause one to allocate a buffer that is much smaller than what is needed, leading to resultant weaknesses such as buffer overflows.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Use expressions such as "sizeof(*pointer)" instead of "sizeof(pointer)", unless you intend to run sizeof() on a pointer type to gain some platform independence or if you are allocating a variable on the stack.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
Care should be taken to ensure sizeof returns the size of the data structure itself, and not the size of the pointer to the data structure.
In this example, sizeof(foo) returns the size of the pointer.
This example defines a fixed username and password. The AuthenticateUser() function is intended to accept a username and a password from an untrusted user, and check to ensure that it matches the username and password. If the username and password match, AuthenticateUser() is intended to indicate that authentication succeeded.
(bad code)
Example Language: C
/* Ignore CWE-259 (hard-coded password) and CWE-309 (use of password system for authentication) for this example. */
if (strncmp(username, inUser, sizeof(username))) {
printf("Auth failure of username using sizeof\n"); return(AUTH_FAIL);
} /* Because of CWE-467, the sizeof returns 4 on many platforms and architectures. */
if (! strncmp(pass, inPass, sizeof(pass))) {
printf("Auth success of password using sizeof\n"); return(AUTH_SUCCESS);
} else {
printf("Auth fail of password using sizeof\n"); return(AUTH_FAIL);
}
}
int main (int argc, char **argv) {
int authResult;
if (argc < 3) {
ExitError("Usage: Provide a username and password");
} authResult = AuthenticateUser(argv[1], argv[2]); if (authResult != AUTH_SUCCESS) {
ExitError("Authentication failed");
} else {
DoAuthenticatedTask(argv[1]);
}
}
In AuthenticateUser(), because sizeof() is applied to a parameter with an array type, the sizeof() call might return 4 on many modern architectures. As a result, the strncmp() call only checks the first four characters of the input password, resulting in a partial comparison (CWE-187), leading to improper authentication (CWE-287).
Because of the partial comparison, any of these passwords would still cause authentication to succeed for the "admin" user:
(attack code)
pass5 passABCDEFGH passWORD
Because only 4 characters are checked, this significantly reduces the search space for an attacker, making brute force attacks more feasible.
The same problem also applies to the username, so values such as "adminXYZ" and "administrator" will succeed for the username.
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Detection
Methods
Method
Details
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
CERT C++ Secure Coding Section 06 - Arrays and the STL (ARR)
MemberOf
View - a subset of CWE entries that provides a way of examining CWE content. The two main view structures are Slices (flat lists) and Graphs (containing relationships between entries).
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Use of sizeof() on a pointer type
CERT C Secure Coding
ARR01-C
Do not apply the sizeof operator to a pointer when taking the size of an array
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The product calls umask() with an incorrect argument that is specified as if it is an argument to chmod().
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Read Files or Directories; Modify Files or Directories; Bypass Protection Mechanism
Scope: Confidentiality, Integrity, Access Control
Potential Mitigations
Phase(s)
Mitigation
Implementation
Use umask() with the correct argument.
Testing
If you suspect misuse of umask(), you can use grep to spot call instances of umask().
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Function Call With Incorrectly Specified Argument Value
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Other
Some umask() manual pages begin with the false statement: "umask sets the umask to mask & 0777" Although this behavior would better align with the usage of chmod(), where the user provided argument specifies the bits to enable on the specified file, the behavior of umask() is in fact opposite: umask() sets the umask to ~mask & 0777. The documentation goes on to describe the correct usage of umask(): "The umask is used by open() to set initial file permissions on a newly-created file. Specifically, permissions in the umask are turned off from the mode argument to open(2) (so, for example, the common umask default value of 022 results in new files being created with permissions 0666 & ~022 = 0644 = rw-r--r-- in the usual case where the mode is specified as 0666)."
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
VariantVariant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
The code uses a variable that has not been initialized, leading to unpredictable or unintended results.
Extended Description
In some languages such as C and C++, stack variables are not initialized by default. They generally contain junk data with the contents of stack memory before the function was invoked. An attacker can sometimes control or read these contents. In other languages or conditions, a variable that is not explicitly initialized can be given a default value that has security implications, depending on the logic of the program. The presence of an uninitialized variable can sometimes indicate a typographic error in the code.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Other
Scope: Availability, Integrity, Other
Initial variables usually contain junk, which can not be trusted for consistency. This can lead to denial of service conditions, or modify control flow in unexpected ways. In some cases, an attacker can "pre-initialize" the variable using previous actions, which might enable code execution. This can cause a race condition if a lock variable check passes when it should not.
Other
Scope: Authorization, Other
Strings that are not initialized are especially dangerous, since many functions expect a null at the end -- and only at the end -- of a string.
Potential Mitigations
Phase(s)
Mitigation
Implementation
Strategy: Attack Surface Reduction
Assign all variables to an initial value.
Build and Compilation
Strategy: Compilation or Build Hardening
Most compilers will complain about the use of uninitialized variables if warnings are turned on.
Implementation; Operation
When using a language that does not require explicit declaration of variables, run or compile the software in a mode that reports undeclared or unknown variables. This may indicate the presence of a typographic error in the variable's name.
Requirements
The choice could be made to use a language that is not susceptible to these issues.
Architecture and Design
Mitigating technologies such as safe string libraries and container abstractions could be introduced.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
In C, using an uninitialized char * in some string libraries will return incorrect results, as the libraries expect the null terminator to always be at the end of a string, even if the string is empty.
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Sometimes Prevalent)
C++
(Sometimes Prevalent)
Perl
(Often Prevalent)
PHP
(Often Prevalent)
Class: Not Language-Specific
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
This code prints a greeting using information stored in a POST request:
(bad code)
Example Language: PHP
if (isset($_POST['names'])) {
$nameArray = $_POST['names'];
} echo "Hello " . $nameArray['first'];
This code checks if the POST array 'names' is set before assigning it to the $nameArray variable. However, if the array is not in the POST request, $nameArray will remain uninitialized. This will cause an error when the array is accessed to print the greeting message, which could lead to further exploit.
Example 2
The following switch statement is intended to set the values of the variables aN and bN before they are used:
(bad code)
Example Language: C
int aN, Bn; switch (ctl) {
case -1:
aN = 0; bN = 0; break;
case 0:
aN = i; bN = -i; break;
case 1:
aN = i + NEXT_SZ; bN = i - NEXT_SZ; break;
default:
aN = -1; aN = -1; break;
} repaint(aN, bN);
In the default case of the switch statement, the programmer has accidentally set the value of aN twice. As a result, bN will have an undefined value. Most uninitialized variable issues result in general software reliability problems, but if attackers can intentionally trigger the use of an uninitialized variable, they might be able to launch a denial of service attack by crashing the program. Under the right circumstances, an attacker may be able to control the value of an uninitialized variable by affecting the values on the stack prior to the invocation of the function.
Example 3
This example will leave test_string in an
unknown condition when i is the same value as err_val,
because test_string is not initialized
(CWE-456). Depending on where this code segment appears
(e.g. within a function body), test_string might be
random if it is stored on the heap or stack. If the
variable is declared in static memory, it might be zero
or NULL. Compiler optimization might contribute to the
unpredictability of this address.
(bad code)
Example Language: C
char *test_string;
if (i != err_val)
{
test_string = "Hello World!";
}
printf("%s", test_string);
When the printf() is reached,
test_string might be an unexpected address, so the
printf might print junk strings (CWE-457).
To fix this code, there are a couple approaches to
making sure that test_string has been properly set once
it reaches the printf().
One solution would be to set test_string to an
acceptable default before the conditional:
(good code)
Example Language: C
char *test_string = "Done at the beginning";
if (i != err_val)
{
test_string = "Hello World!";
}
printf("%s", test_string);
Another solution is to ensure that each
branch of the conditional - including the default/else
branch - could ensure that test_string is set:
(good code)
Example Language: C
char *test_string;
if (i != err_val)
{
test_string = "Hello World!";
}
else {
test_string = "Done on the other side!";
}
printf("%s", test_string);
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: sscanf() call is used to check if a username and group exists, but the return value of sscanf() call is not checked (CWE-252), causing an uninitialized variable to be checked (CWE-457), returning success to allow authorization bypass for executing a privileged (CWE-863).
Chain: A denial of service may be caused by an uninitialized variable (CWE-457) allowing an infinite loop (CWE-835) resulting from a connection to an unresponsive server.
Fuzz testing (fuzzing) is a powerful technique for generating large numbers of diverse inputs - either randomly or algorithmically - and dynamically invoking the code with those inputs. Even with random inputs, it is often capable of generating unexpected results such as crashes, memory corruption, or resource consumption. Fuzzing effectively produces repeatable test cases that clearly indicate bugs, which helps developers to diagnose the issues.
Effectiveness: High
Automated Static Analysis
Automated static analysis, commonly referred to as Static Application Security Testing (SAST), can find some instances of this weakness by analyzing source code (or binary/compiled code) without having to execute it. Typically, this is done by building a model of data flow and control flow, then searching for potentially-vulnerable patterns that connect "sources" (origins of input) with "sinks" (destinations where the data interacts with external components, a lower layer such as the OS, etc.)
Effectiveness: High
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Variant level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 8: C++ Catastrophes." Page 143. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 7, "Variable Initialization", Page 312. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
Wrap around errors occur whenever a value is incremented past the maximum value for its type and therefore "wraps around" to a very small, negative, or undefined value.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
This weakness will generally lead to undefined behavior and therefore crashes. In the case of overflows involving loop index variables, the likelihood of infinite loops is also high.
Modify Memory
Scope: Integrity
If the value in question is important to data (as opposed to flow), simple data corruption has occurred. Also, if the wrap around results in other conditions such as buffer overflows, further memory corruption may occur.
Execute Unauthorized Code or Commands; Bypass Protection Mechanism
Scope: Confidentiality, Availability, Access Control
This weakness can sometimes trigger buffer overflows which can be used to execute arbitrary code. This is usually outside the scope of a program's implicit security policy.
Potential Mitigations
Phase(s)
Mitigation
Requirements specification: The choice could be made to use a language that is not susceptible to these issues.
Architecture and Design
Provide clear upper and lower bounds on the scale of any protocols designed.
Implementation
Perform validation on all incremented variables to ensure that they remain within reasonable bounds.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Pillar - a weakness that is the most abstract type of weakness and represents a theme for all class/base/variant weaknesses related to it. A Pillar is different from a Category as a Pillar is still technically a type of weakness that describes a mistake, while a Category represents a common characteristic used to group related things.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Due to how addition is performed by computers, if a primitive is incremented past the maximum value possible for its storage space, the system will not recognize this, and therefore increment each bit as if it still had extra space. Because of how negative numbers are represented in binary, primitives interpreted as signed may "wrap" to very large negative values.
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Often Prevalent)
C++
(Often Prevalent)
Likelihood Of Exploit
Medium
Demonstrative Examples
Example 1
The following image processing code allocates a table for images.
This code intends to allocate a table of size num_imgs, however as num_imgs grows large, the calculation determining the size of the list will eventually overflow (CWE-190). This will result in a very small list to be allocated instead. If the subsequent code operates on the list as if it were num_imgs long, it may result in many types of out-of-bounds problems (CWE-119).
Weakness Ordinalities
Ordinality
Description
Primary
(where the weakness exists independent of other weaknesses)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Notes
Relationship
The relationship between overflow and wrap-around needs to be examined more closely, since several entries (including CWE-190) are closely related.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Wrap-around error
CERT C Secure Coding
MEM07-C
Ensure that the arguments to calloc(), when multiplied, can be represented as a size_t
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 5: Buffer Overruns." Page 89. McGraw-Hill. 2010.
[REF-62]
Mark Dowd, John McDonald and Justin Schuh. "The Art of Software Security Assessment". Chapter 6, "Signed Integer Boundaries", Page 220. 1st Edition. Addison Wesley. 2006.
Vulnerability Mapping:ALLOWEDThis CWE ID may be used to map to real-world vulnerabilities Abstraction:
BaseBase - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
View customized information:
For users who are interested in more notional aspects of a weakness. Example: educators, technical writers, and project/program managers.For users who are concerned with the practical application and details about the nature of a weakness and how to prevent it from happening. Example: tool developers, security researchers, pen-testers, incident response analysts.For users who are mapping an issue to CWE/CAPEC IDs, i.e., finding the most appropriate CWE for a specific issue (e.g., a CVE record). Example: tool developers, security researchers.For users who wish to see all available information for the CWE/CAPEC entry.For users who want to customize what details are displayed.
×
Edit Custom Filter
Description
Any condition where the attacker has the ability to write an arbitrary value to an arbitrary location, often as the result of a buffer overflow.
Common Consequences
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
Impact
Details
Modify Memory; Execute Unauthorized Code or Commands; Gain Privileges or Assume Identity; DoS: Crash, Exit, or Restart; Bypass Protection Mechanism
Scope: Integrity, Confidentiality, Availability, Access Control
Clearly, write-what-where conditions can be used to write data to areas of memory outside the scope of a policy. Also, they almost invariably can be used to execute arbitrary code, which is usually outside the scope of a program's implicit security policy. If the attacker can overwrite a pointer's worth of memory (usually 32 or 64 bits), they can redirect a function pointer to their own malicious code. Even when the attacker can only modify a single byte arbitrary code execution can be possible. Sometimes this is because the same problem can be exploited repeatedly to the same effect. Other times it is because the attacker can overwrite security-critical application-specific data -- such as a flag indicating whether the user is an administrator.
DoS: Crash, Exit, or Restart; Modify Memory
Scope: Integrity, Availability
Many memory accesses can lead to program termination, such as when writing to addresses that are invalid for the current process.
Bypass Protection Mechanism; Other
Scope: Access Control, Other
When the consequence is arbitrary code execution, this can often be used to subvert any other security service.
Potential Mitigations
Phase(s)
Mitigation
Architecture and Design
Strategy: Language Selection
Use a language that provides appropriate memory abstractions.
Operation
Use OS-level preventative functionality integrated after the fact. Not a complete solution.
Relationships
This table shows the weaknesses and high level categories that are related to this
weakness. These relationships are defined as ChildOf, ParentOf, MemberOf and give insight to
similar items that may exist at higher and lower levels of abstraction. In addition,
relationships such as PeerOf and CanAlsoBe are defined to show similar weaknesses that the user
may want to explore.
Relevant to the view "Research Concepts" (View-1000)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Buffer Copy without Checking Size of Input ('Classic Buffer Overflow')
CanFollow
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Variant - a weakness that is linked to a certain type of product, typically involving a specific language or technology. More specific than a Base weakness. Variant level weaknesses typically describe issues in terms of 3 to 5 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Quality Measures (2020)" (View-1305)
Nature
Type
ID
Name
ChildOf
Base - a weakness that is still mostly independent of a resource or technology, but with sufficient details to provide specific methods for detection and prevention. Base level weaknesses typically describe issues in terms of 2 or 3 of the following dimensions: behavior, property, technology, language, and resource.
Relevant to the view "CISQ Data Protection Measures" (View-1340)
Nature
Type
ID
Name
ChildOf
Class - a weakness that is described in a very abstract fashion, typically independent of any specific language or technology. More specific than a Pillar Weakness, but more general than a Base Weakness. Class level weaknesses typically describe issues in terms of 1 or 2 of the following dimensions: behavior, property, and resource.
Improper Restriction of Operations within the Bounds of a Memory Buffer
Modes
Of Introduction
The different Modes of Introduction provide information
about how and when this
weakness may be introduced. The Phase identifies a point in the life cycle at which
introduction
may occur, while the Note provides a typical scenario related to introduction during the
given
phase.
Phase
Note
Implementation
Applicable Platforms
This listing shows possible areas for which the given
weakness could appear. These
may be for specific named Languages, Operating Systems, Architectures, Paradigms,
Technologies,
or a class of such platforms. The platform is listed along with how frequently the given
weakness appears for that instance.
Languages
C
(Undetermined Prevalence)
C++
(Undetermined Prevalence)
Likelihood Of Exploit
High
Demonstrative Examples
Example 1
The classic example of a write-what-where condition occurs when the accounting information for memory allocations is overwritten in a particular fashion. Here is an example of potentially vulnerable code:
(bad code)
Example Language: C
#define BUFSIZE 256 int main(int argc, char **argv) {
Vulnerability in this case is dependent on memory layout. The call to strcpy() can be used to write past the end of buf1, and, with a typical layout, can overwrite the accounting information that the system keeps for buf2 when it is allocated. Note that if the allocation header for buf2 can be overwritten, buf2 itself can be overwritten as well.
The allocation header will generally keep a linked list of memory "chunks". Particularly, there may be a "previous" chunk and a "next" chunk. Here, the previous chunk for buf2 will probably be buf1, and the next chunk may be null. When the free() occurs, most memory allocators will rewrite the linked list using data from buf2. Particularly, the "next" chunk for buf1 will be updated and the "previous" chunk for any subsequent chunk will be updated. The attacker can insert a memory address for the "next" chunk and a value to write into that memory address for the "previous" chunk.
This could be used to overwrite a function pointer that gets dereferenced later, replacing it with a memory address that the attacker has legitimate access to, where they have placed malicious code, resulting in arbitrary code execution.
Selected Observed
Examples
Note: this is a curated list of examples for users to understand the variety of ways in which this
weakness can be introduced. It is not a complete list of all CVEs that are related to this CWE entry.
Chain: Python library does not limit the resources used to process images that specify a very large number of bands (CWE-1284), leading to excessive memory consumption (CWE-789) or an integer overflow (CWE-190).
Chain: 3D renderer has an integer overflow (CWE-190) leading to write-what-where condition (CWE-123) using a crafted image.
Weakness Ordinalities
Ordinality
Description
Resultant
(where the weakness is typically related to the presence of some other weaknesses)
Memberships
This MemberOf Relationships table shows additional CWE Categories and Views that
reference this weakness as a member. This information is often useful in understanding where a
weakness fits within the context of external information sources.
Nature
Type
ID
Name
MemberOf
Category - a CWE entry that contains a set of other entries that share a common characteristic.
(this CWE ID may be used to map to real-world vulnerabilities)
Reason
Acceptable-Use
Rationale
This CWE entry is at the Base level of abstraction, which is a preferred level of abstraction for mapping to the root causes of vulnerabilities.
Comments
Carefully read both the name and description to ensure that this mapping is an appropriate fit. Do not try to 'force' a mapping to a lower-level Base/Variant simply to comply with this preferred level of abstraction.
Taxonomy
Mappings
Mapped Taxonomy Name
Node ID
Fit
Mapped Node Name
CLASP
Write-what-where condition
CERT C Secure Coding
ARR30-C
Imprecise
Do not form or use out-of-bounds pointers or array subscripts
CERT C Secure Coding
ARR38-C
Imprecise
Guarantee that library functions do not form invalid pointers
CERT C Secure Coding
STR31-C
Imprecise
Guarantee that storage for strings has sufficient space for character data and the null terminator
CERT C Secure Coding
STR32-C
Imprecise
Do not pass a non-null-terminated character sequence to a library function that expects a string
Software Fault Patterns
SFP8
Faulty Buffer Access
References
[REF-44]
Michael Howard, David LeBlanc and John Viega. "24 Deadly Sins of Software Security". "Sin 5: Buffer Overruns." Page 89. McGraw-Hill. 2010.

 Objective
Objective This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.
This table specifies different individual consequences
associated with the weakness. The Scope identifies the application security area that is
violated, while the Impact describes the negative technical impact that arises if an
adversary succeeds in exploiting this weakness. The Likelihood provides information about
how likely the specific consequence is expected to be seen relative to the other
consequences in the list. For example, there may be high likelihood that a weakness will be
exploited to achieve a certain impact, but a low likelihood that it will be exploited to
achieve a different impact.